The Rules of Open Source We Took for Granted — Why Changing a License Is Almost Impossible
Today, most developers no longer consider using open source to be anything unusual. Searching for projects on GitHub, installing necessary libraries, and managing dependencies through package managers have become a natural part of the development process. In Python, a simple pip install, in JavaScript npm install, and in Rust cargo add—just a few commands are enough to add hundreds of libraries to a project. In this process, developers often check the license file before even looking at the internal structure of the code. Especially in corporate environments, permissive licenses like MIT and Apache are relatively easy to use, while Copyleft licenses such as GPL or LGPL often require legal review.
This culture has created a kind of implicit rule in the open source world. Many developers operate under the simple assumption that “open source is free to use.” However, in reality, open source is not merely a collection of free code—it operates on a legal structure built on copyright and licensing agreements. Just because code is publicly available on GitHub does not mean anyone can use it without conditions. Each project has a clearly defined license, and that license governs how the code can be used, redistributed, and modified. The reason the open source ecosystem has been sustained for decades is precisely because of this licensing system.
However, this system has one important characteristic: changing a license is extremely difficult. In most open source projects, copyright does not belong to the project itself but to each individual contributor. When someone fixes a bug or adds a new feature, the copyright of that code remains with that contributor. Therefore, to change the license of an entire project, consent must be obtained from every contributor who has ever participated. This might be possible for a small project, but for projects with dozens or hundreds of contributors, it becomes practically impossible.
As a result, many open source projects retain their original license almost permanently. Even when a license change is necessary, the common approach is to start a new project separately or to write a completely different implementation from scratch. However, the emergence of generative AI has begun to raise new questions about this long-standing rule. If code is not modified based on the original but instead completely rewritten using AI, does it still fall under the influence of the original license? Or can it be considered an entirely new project? This is not just a hypothetical question—it has already led to real controversies within open source communities.
Copyleft as a Unique Protective Mechanism — The Legal Structure Created by GPL and LGPL
Open source licenses may appear to be simple text files on the surface, but they embody fundamentally different philosophies. A representative example is the distinction between permissive licenses and Copyleft licenses. Licenses like MIT and Apache follow relatively lenient rules. They allow code to be freely used, modified, and even incorporated into commercial products, with the main requirement being that the original copyright notice and license text are preserved. Because these licenses impose minimal restrictions, they have become widely preferred, especially in corporate environments.
In contrast, Copyleft licenses are built on an entirely different philosophy. A well-known example is the GNU GPL. GPL goes beyond merely making code available—it enforces the continued freedom of that code. If a program built using GPL-licensed code is modified or redistributed, the resulting program must also be released under the GPL. In other words, once GPL code is included in a project, the same license must be maintained going forward. This structure is often referred to as a “viral license.” The purpose of Copyleft is to protect the freedom of code by ensuring that derivative works preserve the same freedoms.
The LGPL is a more relaxed form of Copyleft compared to GPL. It allows libraries to be used within commercial applications, but if the library itself is modified, those modifications must be made public. Thanks to this structure, LGPL libraries have been more widely adopted in enterprise environments. However, the core principle of Copyleft remains intact: derivative works based on existing code must retain the same license.
Because of this principle, changing the license of a Copyleft-licensed project is particularly difficult. For example, converting a project released under GPL to an MIT license cannot be achieved simply by editing the license file. Consent must be obtained from every contributor who holds copyright to the existing code; otherwise, the new license is unlikely to be legally valid. As a result, many projects choose to start anew or develop entirely separate implementations rather than attempt a license change.
It is at this point that the chardet case becomes especially interesting. The project had maintained an LGPL license for a long time, which allowed it to be widely used within the Python ecosystem. At the same time, however, the LGPL license posed a legal burden for some corporate users. And it was precisely this tension that eventually led to the decision to rewrite the code using AI.
A Small Library in the Python Ecosystem — What History Did the chardet Project Stand On
Any Python developer has likely used the requests library at least once. Designed to simplify HTTP requests, it has become a de facto standard tool within the Python ecosystem. However, inside requests lies another dependency that developers often do not explicitly recognize: chardet, a library that automatically detects character encoding. Text data retrieved from the web can be stored in various encodings, and accurately processing it requires an encoding detection algorithm. That is precisely the role chardet fulfills.
The origins of chardet trace back to the Mozilla project. During the early development of web browsers, there was a need for algorithms that could automatically detect different character encodings, leading to the creation of encoding detection code written in C++. This algorithm was later ported to Python, which marked the beginning of the chardet project. Over time, the library became widely used within the Python ecosystem, and by being included as a dependency in core libraries like requests, it effectively became an indirect dependency for countless Python projects.
This kind of structure is very common in modern software ecosystems. A small library becomes part of a massive dependency graph, and thousands or even tens of thousands of projects end up relying on the same code. This structure is often referred to as the software supply chain. Even if developers do not directly use chardet, there is a high chance that it is already included in their projects through other libraries. As a result, even a small project like chardet can have a far-reaching impact when its license or code changes.
Another important point is that chardet has maintained the LGPL license for a long time. This is closely tied to its historical roots in Mozilla code. The LGPL license allows the use of the library itself while requiring that modifications to the code be disclosed, making it a kind of compromise between open source philosophy and commercial software use. However, at the same time, this license has often been subject to legal review in corporate environments. This tension had long been a concern for the maintainers of chardet.
And at a certain point, that concern found a solution in an unexpected way. Instead of modifying the existing code or negotiating the license, a new approach emerged: rewriting the code entirely using AI. While this decision may have seemed like a simple technical choice, it quickly sparked intense debate across the entire open source community.
The Beginning of the Incident — The Declaration That the Entire Code Was Rewritten with AI
One of the most sensitive changes in a long-maintained open source project is a license change. Especially when a project using a Copyleft license attempts to transition to a more permissive license, it almost always leads to controversy. The chardet project found itself in a similar situation. This widely used library in the Python ecosystem had maintained an LGPL license for many years, but for some users, this license was perceived as a legal burden. In corporate environments in particular, dependencies that include Copyleft licenses often require legal review, making it reasonable for maintainers to consider a license change in order to improve the project’s accessibility.
However, changing the license of existing code is nearly impossible. As discussed earlier, copyright in open source projects is distributed among individual contributors. For a project that has been maintained over many years—or even decades—tracking down every contributor and obtaining their consent is not realistically feasible. In this situation, the approach chosen by the chardet maintainers was not to modify the existing code or negotiate permissions, but to rewrite the code itself. And the tool used for that task was generative AI.
The maintainers explained that they used Claude Code to create a new implementation that was not based on the original code. According to their claim, the new version was not a simple refactoring or transformation but a completely newly written codebase, and therefore not subject to the original LGPL license. Under this logic, it could be considered a new project, allowing the application of a permissive license such as MIT. In fact, chardet version 7.0.0 was released under the MIT license, and on the surface, it appeared to be a straightforward license change.
However, this announcement immediately triggered strong backlash from the community. The core issue was not simply whether the code had been rewritten. The more important question became who wrote the code, how it was written, and based on what information. In particular, the fact that a developer who had long maintained the original code used AI to generate the new version raised doubts about whether this could truly be considered an independent implementation in the traditional sense. At this point, the debate began to expand beyond a simple licensing issue into a new domain where software law and AI technology intersect.
Clean-Room Implementation — An Old Legal Technique: The IBM PC BIOS and Phoenix Case
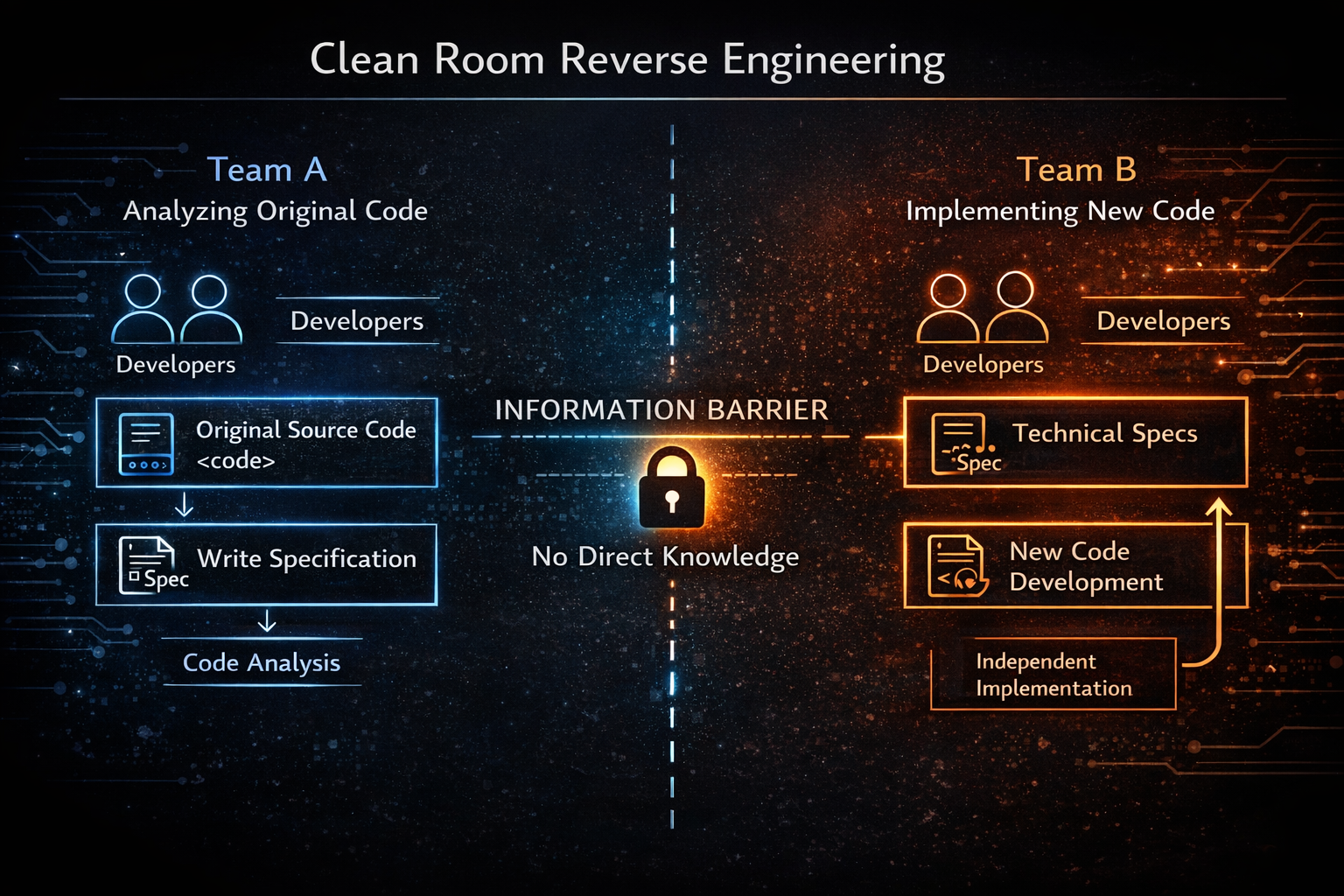
In the history of software, various technical and legal strategies have emerged to navigate around copyright issues. One of the most well-known concepts is clean-room implementation. This approach was developed as a way to reproduce the functionality of existing code while avoiding copyright infringement. The core idea is simple: if the same functionality is implemented without directly referencing the original code, the result can be considered a legally independent work. However, in practice, proving this requires a highly rigorous process.
Traditional clean-room implementation is typically carried out by two independent teams. The first team analyzes the original code and produces a functional specification. This specification does not include the structure or implementation details of the code, but only describes what the program is supposed to do. The second team then writes new code based solely on this specification. The crucial point is that this team must be able to demonstrate that they have never seen the original code. When a clear information barrier exists between the two teams, the resulting code is much more likely to be recognized as an independent implementation under the law.
A well-known example of this concept is the IBM PC BIOS case in the 1980s. At the time, the BIOS of the IBM PC was an essential component for manufacturers building compatible computers, but it could not be directly copied due to copyright restrictions. Phoenix Technologies used a clean-room approach to reimplement the BIOS. One team analyzed the IBM BIOS and created a functional specification, while another team used that specification to write entirely new code. As a result, the Phoenix BIOS was recognized as a legally independent implementation, which contributed to the explosive growth of the PC-compatible market.
This case later became an important precedent in the software industry. The key point of clean-room implementation is not simply rewriting code, but establishing a structured process that controls the flow of information. In other words, a clear barrier must be in place to ensure that knowledge of the original code does not influence the creation of the new code. This principle has since been widely applied in reverse engineering and compatibility projects.
However, in the case of chardet, this traditional model does not apply cleanly. The fact that a maintainer who already knows the original code used AI to generate new code raises the question of whether the flow of information can truly be considered isolated. And it is precisely at this point that a new challenge emerges—one that reflects how software law is being reshaped in the age of AI.
The Boundary Broken by AI — Why the Clean-Room Model No Longer Works
The core of clean-room implementation is the control of information flow. There must be a clear barrier between those who have seen the original code and those who write the new code. However, with the emergence of generative AI, this structure has begun to break down in unexpected ways. Unlike human developers, AI models do not rely on a specific piece of code, but operate based on statistical patterns learned from vast amounts of data. This training data likely includes a large volume of open source code, and may even contain code similar to the project in question.
As a result, AI code generation creates a fundamentally different problem from the traditional clean-room concept. Consider a case where a developer does not look at the original code and simply asks an AI to implement a specific function. In this scenario, the developer can claim that they did not reference the original code. However, the possibility remains that the AI model learned from that code—or something similar—during its training process. This makes it unclear where the boundary of information flow should be drawn. The traditional clean-room model focused on controlling information exchange between human developers, but when the training data of AI models must also be considered, the structure can no longer be applied in a straightforward way.
This issue extends beyond a technical debate into a matter of legal interpretation. Determining whether AI-generated code is a derivative work or an independent implementation may require analyzing the entire code generation process. Factors such as the prompt given to the AI, the data used to train the model, and the similarity between the generated code and existing code could all become relevant. However, in most cases, this information is difficult to access externally. In particular, the training data of commercial AI models is often not disclosed, making any legal dispute significantly more complex to resolve.
In this way, AI code generation is challenging many of the assumptions underlying existing copyright frameworks. In the past, the author of code was clearly identifiable, and it was relatively straightforward to determine whether copying had occurred. Now, however, the process of code generation itself is based on probabilistic models, and even with the same prompt, different code can be produced each time. In such a context, the question of “who wrote the code” becomes increasingly ambiguous—and that ambiguity directly leads to issues of copyright and licensing.
Ultimately, the chardet case raises questions that go far beyond a single project’s licensing dispute. What relationship does AI-generated code have to existing code? And can traditional copyright rules still be applied to such code? These questions are likely to recur across the entire open source ecosystem. At this point, the debate expands even further—into whether AI-generated code itself can be protected by copyright at all.
Another Variable Introduced by U.S. Courts — The Ruling That AI-Generated Works Lack Copyright
One factor that further complicates the debate around AI-generated code is the emergence of recent legal precedents. In particular, U.S. court rulings on AI and copyright are having unexpected implications for the entire software industry. One of the fundamental principles of U.S. copyright law is that copyright applies only to human-created works. While this principle has existed for a long time, the rise of generative AI has brought renewed attention to its significance. As debates emerged over whether AI-generated images, text, and music could be protected by copyright, courts have consistently held that works lacking human creative input are not eligible for copyright protection.
This principle directly impacts the issue of AI-generated code. If code produced by AI is not considered a human creation, then it may not qualify for copyright protection at all. This leads to an unexpected paradox. Software licenses are generally built on copyright—they allow the copyright holder to grant others permission to use the code under specific conditions. But if AI-generated code has no copyright, then the act of applying a license to that code may itself lose legal meaning.
At this point, the chardet case becomes even more complex. The maintainers argue that the new code is an independent implementation created through AI. However, if courts determine that AI-generated code lacks copyright, then the new code may not qualify as a protected work in the traditional sense. As a result, applying a license such as MIT could become legally meaningless. The MIT license is essentially a permission granted by a copyright holder—but if no copyright exists, then no permission may be required in the first place.
This situation raises new questions about the very foundation of open source licensing. Until now, the open source ecosystem has been built on copyright. Developers create code, hold copyright over it, and grant others permission under specific conditions. But in an era where AI becomes a major tool for code generation, this structure may no longer function in a clear or predictable way. The chardet case sits precisely at this boundary—and it may well be the starting point of many similar debates to come.
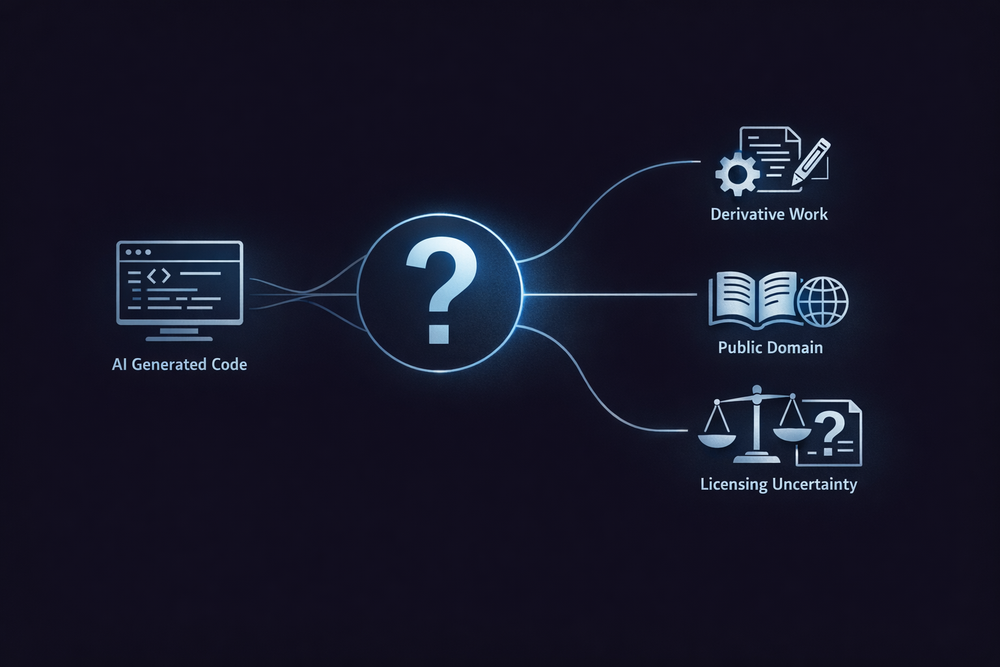
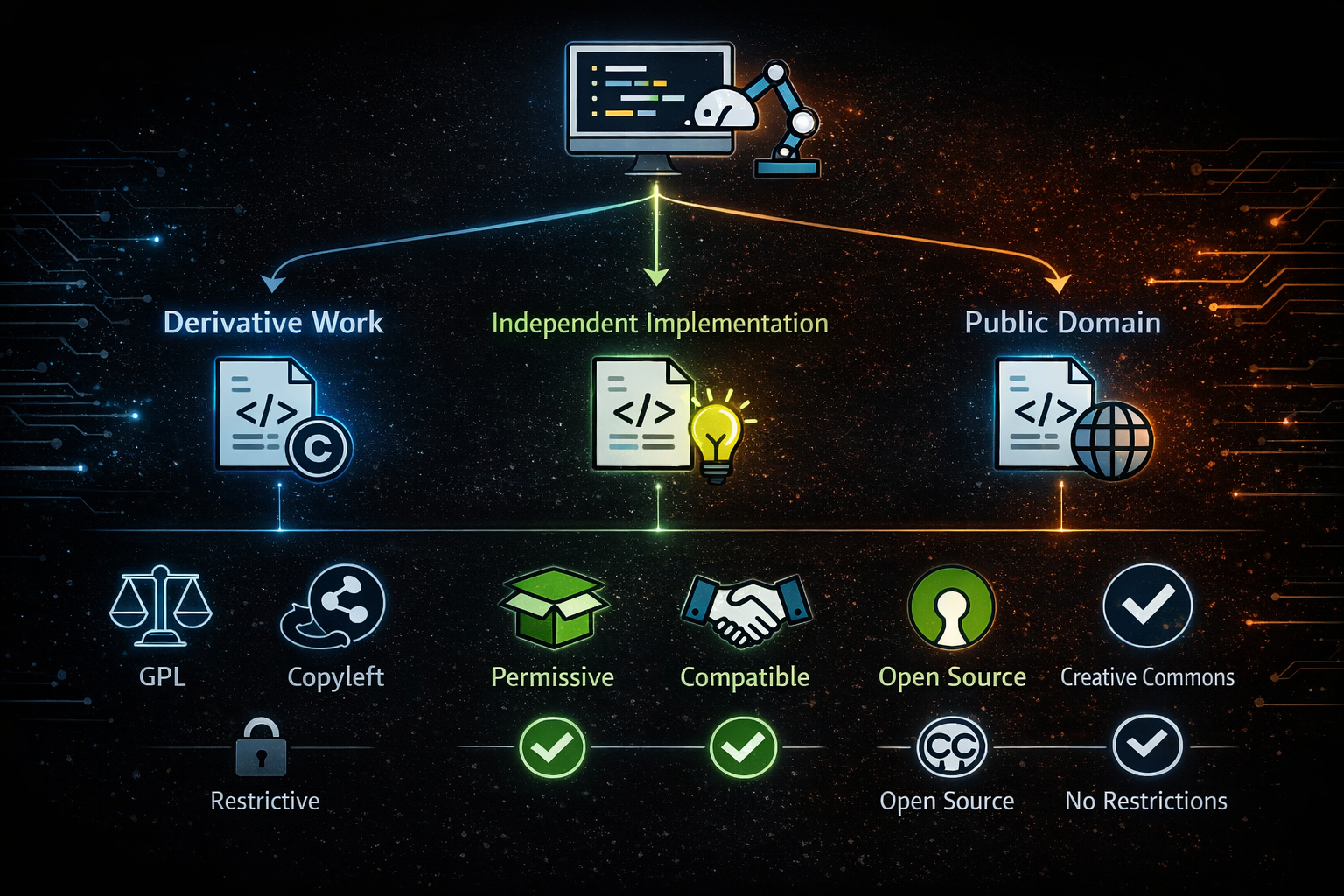
Three Possible Interpretations — Derivative Work, Independent Implementation, or Public Domain
At this point, the issue can be framed more structurally. The debate surrounding the chardet case cannot be reduced to a simple question of whether the code was rewritten. In reality, the emergence of AI code generation as a new technology has collided with existing copyright frameworks, giving rise to multiple possible interpretations at once. Each interpretation leads to a fundamentally different conclusion. While no definitive legal answer exists yet, the debate can broadly be divided into three directions.
The first interpretation argues that AI-generated code is a derivative work of existing code. From this perspective, the key factor is whether the AI model may have been influenced by the original code during training. If the AI generated new code based on the structure or expression of existing LGPL-licensed code, then the result could still be subject to the original license. Under this interpretation, the new implementation of chardet would also need to comply with the LGPL, and the shift to an MIT license could be legally problematic.
The second interpretation views AI-generated code as an independent implementation. This perspective emphasizes that functional similarity does not necessarily constitute copyright infringement. If two developers independently implement the same algorithm, it does not mean they have violated each other’s rights. Similarly, if an AI generates code based on a functional description, the result could simply be another solution to the same problem. In this case, the AI-generated code would be considered a legally independent work, and applying a new license would be valid.
The third interpretation leads to a more radical conclusion. As discussed earlier, if AI-generated code is not eligible for copyright protection, it may effectively fall into the public domain. Works in the public domain can be freely used by anyone without the need for a license. If this interpretation holds, then applying licenses such as MIT or GPL to AI-generated code could become meaningless. This, in turn, could fundamentally reshape the entire open source licensing system.
These three interpretations go beyond a purely legal debate. Each outcome carries different implications for the future of the open source ecosystem. If the derivative work interpretation prevails, Copyleft licenses will continue to function as strong protective mechanisms. If the independent implementation view is accepted, AI could become a new tool for bypassing Copyleft. And if the public domain interpretation becomes reality, the open source licensing system itself may enter an entirely new phase.
What the Community Truly Fears — AI Rewriting and the Open Source Supply Chain
The debate surrounding the chardet case does not end with differences in legal interpretation. What many developers are actually concerned about is not the legal outcome itself, but the structural impact on the entire open source ecosystem. Modern software development operates on a supply chain built from countless dependencies. A small library in one project can be indirectly included in thousands of others, and this web of connections becomes even more complex through package managers and automated dependency systems.
In such a structure, licensing is not merely a legal document—it is a factor that determines the stability of the software supply chain. Companies analyze project dependencies to identify which licenses are involved and establish policies to reduce legal risk. However, if it becomes possible to change licenses through AI-based rewriting, this entire management framework could begin to break down. It would become significantly more difficult to determine which license actually governs a given piece of code.
Another concern is the potential weakening of the practical effectiveness of Copyleft licenses. The core idea of Copyleft is to preserve code freedom by requiring derivative works to adopt the same license. But if existing code can be rewritten using AI and released under a different license, this protective mechanism could be easily bypassed. In such a scenario, some developers may feel uneasy, worrying that the code they released could be reused in ways they never intended.
These concerns are already being expressed in various forms within the developer community. Some argue that in the age of AI, releasing open source code could actually become riskier. Others, however, believe that AI democratizes code generation and expands the freedom of software development. As these opposing perspectives collide, the chardet case has grown beyond a single project dispute into a broader question about the philosophy of open source in the AI era.
And at this point, we arrive at a more fundamental question. If AI becomes a central actor in code production, can license models like Copyleft continue to hold their meaning? Or will the open source licensing system itself need to be redefined in an entirely new way? These questions naturally lead to the next discussion—whether Copyleft can survive in the age of AI.
The First License War of the AI Era — The Questions Left by the chardet Case
Looking back at the debate so far, the chardet case is difficult to view as merely a license change issue in a single open source library. On the surface, it may appear to be a conflict within a small Python library, but in reality, it is closer to one of the first instances where the software copyright system of the AI era has collided with reality. The open source licensing structure, long maintained over decades, was built on the assumption that humans write code. Copyright belongs to the author, and licenses function as a mechanism through which that author grants permission under specific conditions. But the moment AI becomes a central tool for code generation, this very assumption begins to break down.
The chardet case, in particular, revealed this problem in a very concrete form. A project originally based on LGPL code transitioned to an MIT license through AI-driven rewriting, and in the process, multiple issues emerged simultaneously—standards of clean-room implementation, the influence of AI training data, and the copyright status of AI-generated code. Each of these questions may seem independent, but in reality, they are deeply interconnected. If AI has learned from existing code, is the output a derivative work or an independent implementation? And if AI-generated code has no copyright, what meaning does the applied license actually carry? These questions still lack clear answers.
What makes this case especially important is that it represents a type of problem that is likely to recur frequently in the future. AI code generation tools are already part of the development environment, and many developers routinely rely on code completion and generation features. In the past, analyzing and reimplementing a project required significant time and effort, but now it can be done much more quickly with AI tools. While this shift is a positive development in terms of productivity, it also introduces new tensions into copyright and licensing systems.
The case is also significant from the perspective of the software supply chain. Modern software operates on top of numerous dependencies, and a change in a single small library can have far-reaching and unexpected effects. A license change in a widely used library like chardet is not just a matter for one project—it can affect the legal environment of countless projects and companies. If AI-based rewriting becomes recognized as a new pathway for changing licenses, similar attempts may emerge across other projects. As a result, the stability of open source licensing itself could be put to the test.
At the same time, this case raises another intriguing question. If AI-generated code becomes increasingly common, will traditional Copyleft strategies still remain effective? Copyleft was designed to preserve code freedom by requiring derivative works to adopt the same license. However, if AI can rewrite the same functionality into new code, the protective mechanism of Copyleft might be easier to bypass than expected. Whether this will be legally recognized remains uncertain, but the mere possibility is already generating new debates within the open source ecosystem.
Ultimately, the chardet case demonstrates one important fact: we are witnessing the first software licensing dispute of the AI era. There have been many debates around copyright and software licensing in the past—the BIOS clean-room implementation case, API copyright disputes, and various open source license conflicts. But with the rise of AI code generation, an entirely new dimension of the problem has emerged. The question is no longer simply “who wrote the code,” but has expanded into “how was the code generated.”
And this question does not end here. If an AI model has learned from GPL-licensed code, should the code it generates also be subject to GPL? Or should the act of training itself be considered unrelated to copyright? And if AI-generated code is considered a new creative work, who owns its copyright? These questions are already being discussed in courts and developer communities, but no clear consensus has yet been reached.
It is at this point that the next discussion begins. The question raised by the chardet case ultimately leads to a more fundamental issue: if AI learns from GPL code, does its output also become GPL?
This question goes beyond the license of a single library—it has the potential to redefine the law and philosophy of open source in the age of AI. And in the next article, we will explore that question in greater depth.