Why the Concept of “Clean-Room Implementation” Emerged — The Dilemma of Software Copyright and Reimplementation
Anyone who has spent time developing software has likely considered this question at least once: if you observe the functionality of a program and then write new code that performs the same function, is that copyright infringement? Intuitively, it may seem like it is not. After all, you are not copying the code—you are reimplementing the functionality. However, in the legal world, the issue is far more complex. Software is not merely a collection of functions; it is a collection of expressed code. And copyright law protects that expression.
At this point, a crucial legal distinction emerges. Copyright does not protect ideas—it protects expression. This principle applies equally in literature. For example, the idea of “a mystery unfolding in a small town” can be freely used by anyone. But the specific sentences and narrative structure written by an author are protected. The same applies to software. Sorting algorithms, network protocols, and string processing methods are closer to ideas. However, the way those algorithms are expressed in code is subject to copyright protection.
The challenge lies in the nature of computer programs. Many programs perform similar functions, which means their implementations can naturally resemble each other. For instance, if multiple developers independently write a program that reads a file, processes data, and outputs results, the structure of their code may be very similar. Even if function names or variable names differ, the overall flow could be nearly identical. If courts were to judge infringement based solely on code similarity, most software development would be exposed to legal risk.
As a result, the software industry has long grappled with a recurring question: how far is it permissible to implement the same functionality? This is not merely a legal issue—it is closely tied to the competitive structure of the technology industry. If creating software compatible with existing programs were always considered infringement, it would become nearly impossible for new companies to compete with established platforms. On the other hand, if reimplementation were too freely allowed, copyright protection itself could be undermined.
It is within this tension that the concept of clean-room implementation emerged. Clean-room implementation does not simply mean “writing new code.” It is a structured method designed to demonstrate that no copying has occurred. In other words, it is a strategy that carefully designs the development process itself to avoid legal issues. This approach can be seen as a compromise between the needs of the software industry and the constraints of copyright law.
Over time, clean-room implementation has played a crucial role across various areas of the technology industry. In domains where compatibility is essential—such as operating systems, BIOS, and network protocols—this method became almost indispensable. When competing companies needed to implement the same functionality without copying the original code, clean-room implementation was effectively the only viable solution.
At this point, a natural follow-up question arises. How do courts actually determine whether copying has occurred? And why is it not sufficient to simply claim that the code was written without looking at the original?
How “Copying” Is Determined in Copyright Law — The Two Standards of Access and Substantial Similarity
The legal criteria for determining software copyright infringement are more structured than they might appear. Most courts rely on two key factors. The first is whether there was access to the original code, and the second is whether the resulting code shows substantial similarity. When both conditions are satisfied, courts generally conclude that copying is likely to have occurred.
The concept of access does not simply mean whether the original code was directly copied. The crucial question is whether the developer had the opportunity to view or become familiar with the original code. For example, if a developer has analyzed or read a competitor’s program, a court may consider the possibility that the developer retained knowledge of its expression. If the resulting code is similar, it may be interpreted not as independent creation, but as a form of reconstruction based on memory.
This is combined with the second standard: substantial similarity. Courts do not merely compare a few identical lines of code. Instead, they evaluate the overall structure, choice of algorithms, data flow, and function organization. If the core structure of a program is similar, it is less likely to be viewed as coincidence. This is where the concept of substantial similarity becomes critical—it refers not to superficial resemblance, but to similarity at a meaningful and structural level.
When both access and substantial similarity are present, the situation becomes significantly more difficult for the defendant. If a developer had access to the original code and the resulting code is similar, courts often presume that copying has occurred. Although the developer may argue that the code was independently created, proving that claim is challenging. This is especially true in software, where complex structures make legal defense more difficult.
At this point, an important issue arises. In many cases, similarity in programs may simply result from shared functionality. For instance, a program that reads a specific file format must process data in a particular structure. Similarly, code implementing a network protocol must follow the same specification. In such cases, similarity is a natural consequence of technical requirements. However, legal judgments may not always fully account for these technical constraints.
As a result, companies began seeking more robust defensive strategies. It was no longer sufficient to claim, “we did not copy.” Instead, there was a need to demonstrate that the entire development process was independent. This led to the emergence of clean-room implementation. It is not merely a legal argument, but a method of proving independence through organizational structure and development processes.
In the next section, we will examine how clean-room implementation actually works in practice and why it carries such significant legal weight.
What Is Clean-Room Implementation — A Development Structure to Prevent Legal Contamination
At first glance, the concept of clean-room implementation may seem like a simple development technique. In reality, however, it is closer to a legal defense strategy built on structural design. The core idea is straightforward: to block the flow of information so that the expression of the original code does not influence the new code. In other words, it is about preventing “legal contamination” before it can occur during the development process.
Traditional clean-room implementation typically involves two separate teams. The first team analyzes the original code. Their role is not to copy or rewrite it, but to understand how the program works and produce a functional specification. This document describes what inputs the program receives and what outputs it produces. However, it deliberately excludes the structure of the code and the way algorithms are expressed. It explains what the program does, but not how it is implemented.
The second team then writes new code based solely on this specification. Developers in this team are strictly prohibited from viewing the original code. In many cases, they do not even communicate directly with the team that analyzed it. The only information they have is the functional specification. As a result, the code they produce has a very low likelihood of directly replicating the expression of the original code. From a legal perspective, this code is much closer to an independently created new program.
The reason this structure is called a “clean room” comes from the semiconductor industry. In semiconductor manufacturing, work is carried out in tightly controlled environments to prevent dust or contaminants from affecting the product—these environments are called clean rooms. Software clean-room implementation borrows this concept. The “contaminant” being removed here is not dust, but the risk of copyright infringement.
The most important aspect of clean-room implementation lies not in the final code, but in the development process itself. Courts do not evaluate only whether the resulting code is similar; they also examine how that code was created. If there was no possibility for the expression of the original code to be transmitted during development, then even if the final code appears somewhat similar, it is difficult to classify it as copying. This is the essence of clean-room implementation.
This structure is not merely a theoretical legal concept—it has played a significant role in real-world industry. One of the most famous examples in computing history is the case involving IBM PC BIOS and Phoenix. This case demonstrates that clean-room implementation is not just a legal idea, but a strategy capable of reshaping the competitive structure of an entire industry. In the next section, we will take a closer look at that case.
The Most Famous Case — IBM PC BIOS and Phoenix — How Clean-Room Implementation Built the PC Industry
A representative case that demonstrates how clean-room implementation is not merely a legal theory but has had a real impact on industry is the IBM PC BIOS case. In the early 1980s, the personal computer market was effectively dominated by IBM. The IBM PC was not just a product—it had become a new computing standard, and countless companies and developers began building software on top of this platform. However, one of the core components of the IBM PC, the BIOS (Basic Input Output System), was protected by IBM’s copyright. Since the BIOS played a critical role between the operating system and hardware, creating a computer compatible with the IBM PC required a BIOS with the same functionality.
The problem was that directly copying the BIOS code would constitute clear copyright infringement. At the time, many companies wanted to build “clone PCs” compatible with the IBM PC, but the BIOS presented a significant barrier. It was in this context that a company called Phoenix Technologies emerged. Phoenix set out to create a BIOS that performed the same functions without copying IBM’s code—and the method they chose was clean-room implementation.
Phoenix organized two separate teams. The first team analyzed the IBM BIOS and produced a functional specification. This document described what inputs the BIOS received, what outputs it produced, and how the system behaved. However, it deliberately excluded the structure of the original code and the way algorithms were expressed. The second team then used only this specification to write a new BIOS from scratch. The developers on this team had never seen a single line of the original IBM BIOS code. The only information they had was the functional description.
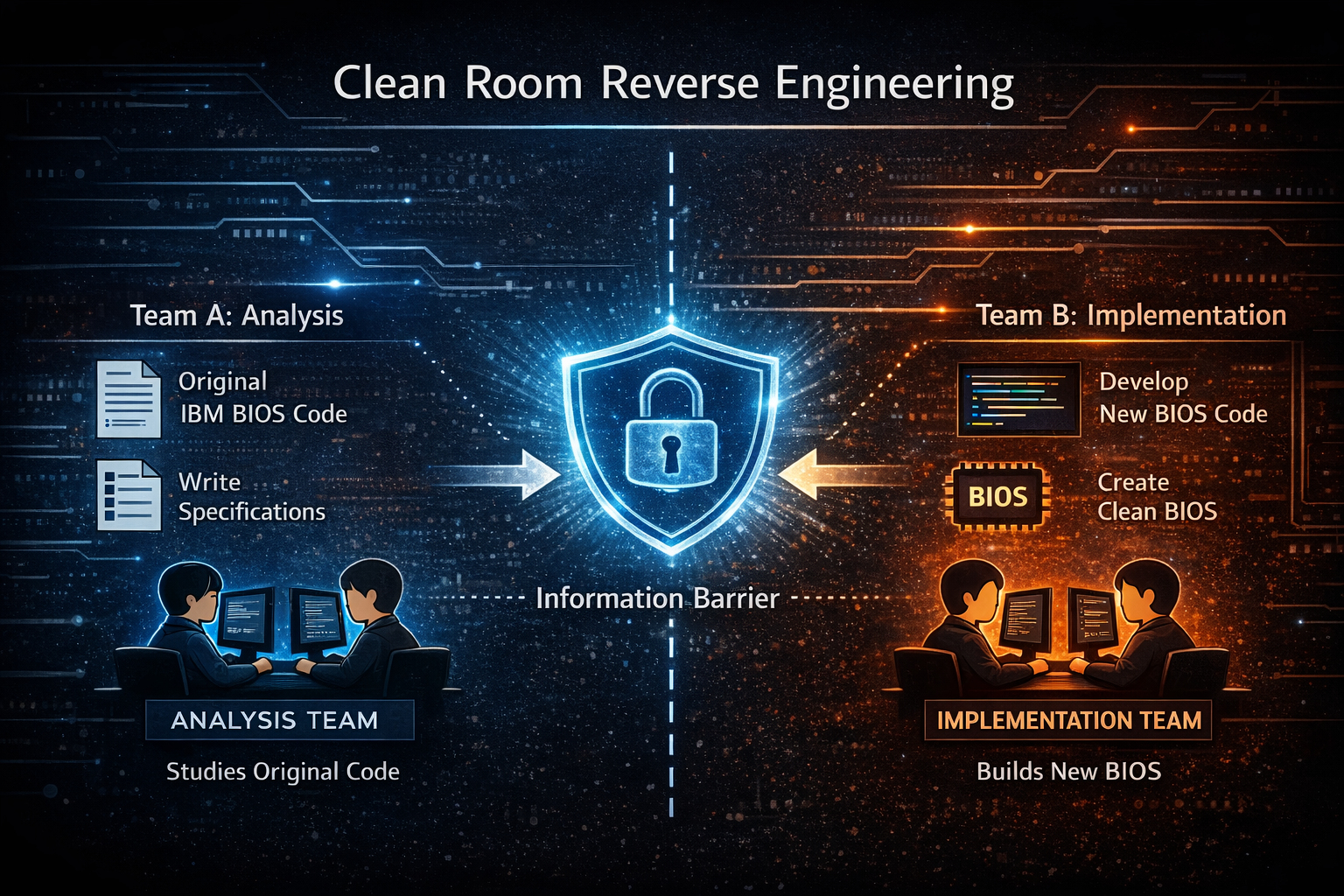
This approach carried significant legal implications. The code written by the second team was not a direct copy of the original code’s expression, but an independently implemented program based on functionality. As a result, the Phoenix BIOS was fully compatible with the IBM PC, yet its code was entirely new. This strategy proved successful, and many PC manufacturers began using the Phoenix BIOS to build IBM-compatible computers. Consequently, a vast ecosystem of “IBM-compatible PCs” emerged, shaping the personal computer market as we know it today.
This case demonstrates that clean-room implementation is not just a legal defense strategy, but a tool capable of reshaping the competitive structure of an entire industry. If Phoenix had failed to legally reimplement the BIOS, the IBM PC might have remained a far more closed platform. And the modern PC industry could have evolved into something entirely different from what we see today.
Conditions for Legal Recognition of Clean-Room Implementation — Proving Independent Development
After the IBM BIOS case, clean-room implementation became a widely known strategy in the software industry. However, not every reimplementation is automatically recognized as legally valid. Courts do not consider it sufficient to simply claim that the code was written without referencing the original. What truly matters is not the final code itself, but whether the development process was genuinely independent. In other words, for clean-room implementation to be accepted, the process must be clearly documented and provable.
The most critical legal requirement is the isolation of information flow. If someone who has seen the original code directly participates in writing the new code, courts may assume that the resulting code was influenced by the original expression. This is why clean-room structures enforce a strict separation between the analysis team and the implementation team. This separation is more than organizational—it can extend to limiting even direct communication between the two teams. The analysis team produces only functional specifications, while the implementation team develops code solely based on those specifications.
Documentation and record-keeping are also essential. Functional specifications, design documents, and development logs can all serve as legal evidence. In the event of a dispute, courts examine not only the final code but also how the development process was carried out. Well-documented records help demonstrate independent implementation, whereas the absence of such records makes it difficult to convincingly prove that the code was independently created.
In practice, however, maintaining a perfect clean-room environment is not easy. Developers often analyze existing systems or understand existing code structures before writing new code. Since human memory cannot be completely erased, there is always the possibility that elements of the original code may influence the new implementation, even unconsciously. For this reason, courts evaluate not only the similarity of the resulting code but also the independence of the development process.
As a result, clean-room implementation is less a simple development technique and more a strategic approach to managing legal risk. It is particularly important in areas where compatibility with existing systems is essential, such as operating systems, file formats, and network protocols. When developers must implement the same functionality while avoiding copyright infringement, clean-room implementation often becomes the safest approach.
However, as the software industry has evolved, another question has begun to emerge. Beyond functionality, can the interface itself be protected by copyright? This question would eventually lead to another well-known case.
API and the Reimplementation Debate — The Google vs Oracle Case
The debate over software reimplementation did not end with the BIOS case. One of the most significant controversies in the 2010s was the Google vs Oracle case. At its core, the dispute centered on whether Android’s use of the Java API structure constituted copyright infringement. After acquiring the rights to Java, Oracle filed a lawsuit against Google, arguing that Android’s use of Java APIs violated copyright.
Google took a different position. It argued that an API is not merely code, but an interface through which developers interact with software. APIs define how functions are called, making them closer to a set of rules than to expressive code. According to this view, granting copyright protection to API structures would severely restrict software compatibility. If API structures themselves were protected, it would become nearly impossible for other companies to build compatible platforms.
The case ultimately reached the U.S. Supreme Court, which ruled in favor of Google. The key reasoning was that the use of Java API structures in Android qualified as fair use. The Court recognized that APIs function as practical interfaces in software development, and that reusing them to build new platforms promotes technological innovation.
This ruling had a major impact on the software industry. It clarified that using API structures does not automatically constitute copyright infringement. At the same time, the case highlighted just how complex the boundaries of software copyright can be. There is always a subtle distinction between functionality, interfaces, and the expression of code.
This debate also connects back to the concept of clean-room implementation. When reimplementing software, developers must constantly consider what can be freely used and what is protected. If the BIOS case was about reimplementing code, the Google vs Oracle case was about reusing interfaces. And today, this debate is expanding in yet another direction.
That direction is the age of AI code generation. A new question now emerges: if an AI learns from existing code and generates new code, is that truly an independent implementation, or is it another form of derivative work influenced by the original?
This question naturally leads into the next section, where we will explore the clean-room problem in the age of AI.
The New Problem in the Age of AI — Is Clean-Room Implementation Still Possible
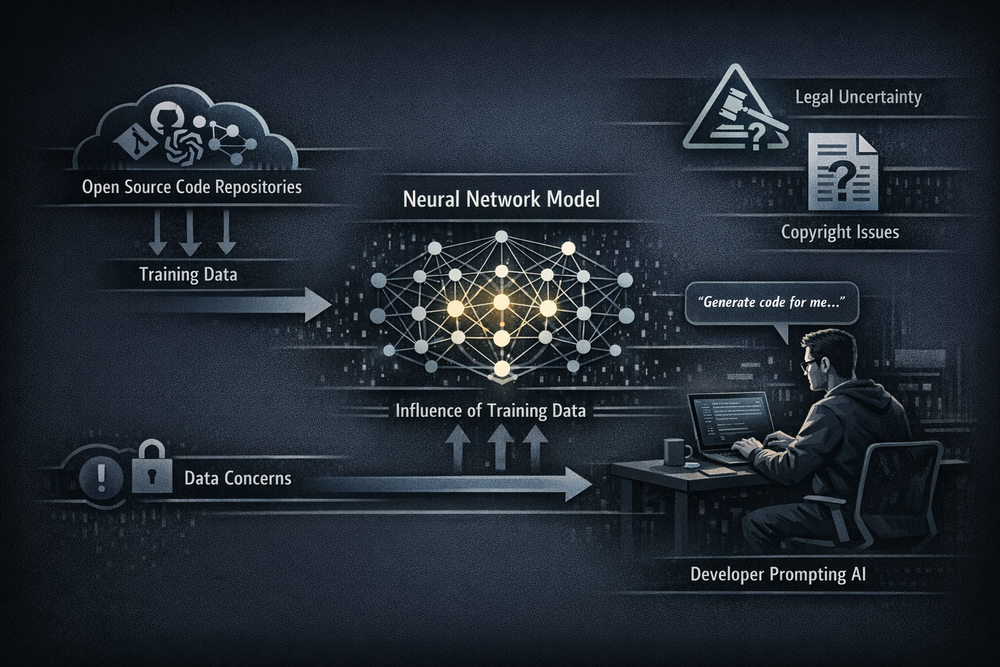
The history and legal structure of clean-room implementation we have examined so far were all built on a model centered around human developers. By separating the team that analyzes the original code from the team that writes new code, and by blocking the flow of information between them, independent implementation could be established. However, with the rise of generative AI, this assumption has begun to break down. Today, many developers use code generation models to build new programs. The issue is that these models are not simple tools—they are systems trained on vast amounts of code data.
Most large language models are trained on a wide range of sources, including public software repositories, documentation, forums, and tutorials. Within this data, there is a high likelihood that numerous open source projects are included. As a result, it cannot be entirely ruled out that the code generated by these models may partially reproduce the structure or expression of specific projects. In this context, can “AI-generated code” truly be considered an independent implementation? Or should it be viewed as a potentially derivative work influenced by training data?
The essence of clean-room implementation is the isolation of information flow. However, AI models inherently operate with prior exposure to vast amounts of code. Even if a developer has not seen the original code, if the model has learned from it, one could argue that the information flow has not been fully isolated. In this sense, a traditional clean-room environment becomes difficult to maintain in an AI-driven context.
Another issue lies in the role of the developer. Consider a case where a developer has read existing code and then asks an AI to “reimplement this functionality.” On the surface, it may appear that the AI generated new code independently. In reality, however, the developer—who is already aware of the original code—has influenced the process. The resulting code becomes a collaborative product of human and AI. From a legal perspective, this situation is far removed from clean-room implementation, because the information flow has not been fully isolated.
AI has made the process of writing code faster, but at the same time, it has made copyright analysis far more complex. In the past, it was relatively clear which code a developer had seen and how new code was written. But once AI enters the process, code generation becomes significantly more opaque. It is difficult to determine what data the model has learned from and which patterns it used to generate the code.
At this point, the significance of clean-room implementation reemerges. In the past, it was possible to control information flow by separating teams. In the AI environment, however, the model itself becomes part of that information flow. As a result, applying traditional clean-room structures is becoming increasingly difficult.
The Legal Gap Between AI and Clean-Room — A Domain the Law Has Yet to Define
The issues raised by AI code generation are not merely technical—they resemble a legal gap. Most existing copyright laws were designed with human creators in mind. They focus on who wrote the code and who copied the original work. However, with the emergence of AI, the process of creating code itself has changed. In many cases, humans no longer write code directly but instead prompt models to generate it. In this situation, the legal standards that should be applied are still unclear.
A particularly important issue is the relationship between training data and generated code. If an AI model has learned from a specific open source project, the code it generates may reflect that influence. However, it is difficult to determine whether that influence is merely pattern learning or an actual reconstruction of the original code’s expression. In some cases, generated code appears highly similar to existing code, while in others it takes on entirely new structures.
There are broadly two perspectives on this issue. The first views AI models as systems for learning statistical patterns. From this perspective, models do not memorize specific code expressions but learn general coding patterns. Therefore, the code they generate is not a copy, but a new combination of learned patterns. Under this interpretation, AI-generated code is closer to independent implementation.
The second perspective sees AI models as something akin to a compressed database. According to this view, models internally store and reconstruct training data. If generated code reproduces the expression of a specific project, it may be closer to a derivative work than a mere pattern-based creation.
The problem is that current legal frameworks do not clearly distinguish between these two perspectives. Even the internal mechanisms by which AI models transform training data into internal representations are not fully understood. As a result, courts will likely need to establish new standards through future AI-related cases.
This situation differs fundamentally from past cases such as the BIOS dispute or the API controversy. In those cases, the relationship between code and developer was relatively clear. Now, with the introduction of AI models as a new actor, the entire copyright framework is being put to the test. And this shift has the potential to affect not just legal theory, but the structure of the entire software industry.
Does Clean-Room Implementation Lose Its Meaning — Copyright in the Age of Code Generation
As AI code generation becomes widespread, some developers argue that the very significance of clean-room implementation is weakening. In the past, developing new software required substantial time and effort. As a result, directly copying the expression of existing code was often the easiest path, and copyright protection played a crucial role. However, with the rise of AI, the cost of generating code has dropped dramatically. It is now possible to produce code with the same functionality in a matter of seconds.
This shift is challenging the fundamental assumptions of the software industry. Traditional copyright systems were built on the premise that code is scarce—that writing code requires significant effort, and therefore its expression needs protection. But in the age of AI, code is no longer scarce. If the same functionality can be generated in countless ways almost instantly, it raises the question of how meaningful it is to protect specific code expressions.
In this context, clean-room implementation may take on a different role. In the past, it served as a strategy for competing companies to build software compatible with existing systems. In the AI era, however, it may reemerge as a minimum standard for ensuring independent implementation. When it is unclear what data an AI model has learned from, documenting and controlling the code generation process itself may become increasingly important.
The relationship with open source licensing must also be reconsidered. If an AI model generates code after learning from countless open source projects, what license should apply to that output? Some argue that AI-generated code should inherit license constraints because it is influenced by existing projects. Others maintain that if the AI produces a new expression, the result should be considered independent code.
This debate ultimately leads to a fundamental question of software copyright: who is the author of the code? Is it the human developer, the AI model, or a collaboration between the two? And this question naturally leads to the next step. If AI-generated code is not recognized as a human creation, can it even be protected by copyright?
That is precisely the topic of the next discussion.
Can code created by AI be protected by copyright, or does it belong to an entirely new legal domain?
Conclusion — Is Clean-Room Implementation a Relic of the Past, and the New Questions of the AI Era
The history of clean-room implementation we have examined is not merely the history of a development technique. It is a strategy that the software industry created to balance legal constraints of copyright with technological competition. As seen in the BIOS case, clean-room implementation had the power to reshape entire industries. Because it made it possible to implement the same functionality without copying the expression of existing code, new companies could enter the market and compete with established platforms. In this sense, clean-room implementation was not simply a legal workaround—it was closer to an institutional mechanism that enabled innovation.
This structure was possible because the software development process was relatively transparent. It was feasible to trace who wrote the code, what references were used, and how information flowed during development. By separating the analysis team and the implementation team, information flow could be controlled, making it possible to prove independent implementation. Courts were able to understand this structure, and in multiple cases, clean-room implementation was recognized as a valid legal defense. In this way, clean-room implementation represented a compromise between technology and law.
However, with the rise of generative AI, this balance has begun to shift once again. Code is no longer solely the result of human developers—it can also be generated by models. These models are trained on vast amounts of code data, and their internal workings are not fully transparent. Even if a developer has not seen the original code, if the model has already learned from it, it becomes difficult to argue that information flow has been completely isolated. In other words, in the age of AI, the core premise of clean-room implementation itself becomes uncertain.
This shift raises broader questions about the entire copyright system. Clean-room implementation was built on the assumption that as long as expression is not copied, reimplementation is legally permissible. But AI models can generate new code based on patterns and structures learned from existing code without directly copying its expression. In such cases, is the resulting code an independent creation, or a derivative work influenced by training data? Current law does not provide a clear answer.
Another important change lies in the economics of code production. In the past, creating new software required significant time and resources, making the protection of code expression meaningful. In the AI era, however, the speed of code generation has increased dramatically. If multiple implementations of the same functionality can be generated in seconds, it raises the question of how meaningful it is to protect a specific expression of code. This shift may also affect open source licensing, particularly the philosophy of Copyleft.
Does this mean that clean-room implementation will disappear entirely? Not necessarily. On the contrary, it may regain importance as a way to demonstrate the transparency of the development process. In environments where AI models are involved, documenting and explaining how code was generated may become increasingly critical. Recording which model was used, what prompts were given, and what references were involved could evolve into a new form of “clean-room procedure”.
Ultimately, the question raised by clean-room implementation remains valid today. Where is the boundary between implementing the same functionality and copying code? This question has persisted since the early days of the software industry and remains unresolved even in the age of AI. Only the form of the question has changed.
In the past, this question revolved around two teams of developers.
Now, it is shared between human developers and AI models.
And at this point, a new question emerges. If code is generated by AI, who owns its copyright? Is it the human developer, the company that built the model, or no one at all? This is not merely a matter of legal curiosity—it is a question that could shape the future structure of the software industry.
The next article will explore exactly this issue.
Can code created by AI be protected by copyright?