
AI Has Always Been Alone — The Assumption of a Single-Agent Structure
Most of the AI systems we have used so far have fundamentally operated as a single thinking entity. When a user inputs a prompt, one model interprets the entire context and generates a single response. This process appears simple and intuitive on the surface, and in the early stages it feels very powerful. Especially for short questions and clearly defined requirements, this structure seems to work almost perfectly. As a result, we naturally accept the assumption that “AI is a single intelligent entity.” This assumption has persisted for so long that many people do not even recognize it as a design choice. However, this structure is merely the result of a particular design—it is not inherently necessary.
The problem becomes visible when this single-agent structure is extended to more complex tasks. When the task goes beyond simple Q&A—such as analyzing an entire codebase or solving multi-step reasoning problems—a single model is required to handle everything simultaneously. In such cases, the model must fit all information into a single context and continue reasoning within it. At first, this appears to work well, but as more information accumulates, the consistency of the results begins to break down. Earlier decisions may distort later ones, or irrelevant information may linger and interfere with reasoning. Despite this, we have often treated the issue not as a structural limitation but as a problem of “writing better prompts.” In reality, this approach is not a fundamental solution—it is merely an optimization within a structure that already has inherent limits.
At this point, an important question emerges. Does AI truly need to be a single entity, or have we simply been using it that way? The current approach gained widespread adoption because of its simplicity, but that simplicity has become a constraint when dealing with complex problems. As tasks grow more diverse and require different types of reasoning, a structure in which one model is responsible for everything becomes increasingly inefficient. Ultimately, we reach a point where we must rethink not how to use a single model better, but the structure itself.
Why It Breaks Down in Complex Problems — The Structural Limits of Context
The reason the single-agent structure fails in complex problems is not simply due to limitations in model performance. The core issue lies in how context is handled. LLMs take all input information as a single context and generate the next token based on that entire context. In this structure, all information accumulates within the same space, and the model continues reasoning based on that whole set. The problem is that as the context grows longer, all information is treated equally regardless of its importance or relevance. Information that was initially critical gradually loses influence as it moves further back, while newly added, less important details can exert a stronger effect. This phenomenon accumulates gradually, making it difficult for users to notice, but it clearly impacts the quality of results.

This issue is often explained through the concepts of context pollution and context rot. Context pollution refers to the accumulation of unnecessary or redundant information that interferes with reasoning. Context rot, on the other hand, describes how initially important information becomes distorted or diluted over time, gradually weakening the model’s judgment. These two problems are not independent—they occur simultaneously and reinforce each other. As a result, the model ends up referencing more information, yet the overall quality of that information decreases, creating a paradoxical situation. Within this structure, no matter how carefully prompts are designed, it becomes difficult to avoid quality degradation beyond a certain point.
The important point here is that this problem is not caused by user error or model limitations. It is structurally unavoidable. The issue lies in the very approach of pushing all information into a single context. That is why we have tried various methods—writing better prompts, reducing unnecessary information, or breaking tasks into steps. However, all of these attempts are still optimizations within the same structure. A fundamental solution must begin not with the question of “how to use context better,” but with the question of “does context need to remain unified?” The answer to this question leads to the approach discussed in the next section: Subagents.
Not a Fix, but a Shift — A New Approach with Subagents
Until now, we have designed systems based on the assumption that a single model must handle everything. As a result, improvements have focused on breaking tasks down more effectively, refining prompts, or enhancing model performance. However, Subagents overturn this assumption. If there is no reason for a single model to handle everything, then the task can be divided into multiple agents, each responsible for its own part. This approach is not merely about improving efficiency—it is an attempt to redesign the structure itself.
The basic workflow of Subagents is surprisingly simple. First, a large task is divided into multiple smaller tasks. Then, a separate agent is created for each task. Each agent processes only its assigned task independently, completely isolated from the contexts of other agents. Once all agents have completed their tasks, the results are combined into a final response. A key point here is that each agent does not need to use the same model or configuration. In other words, different “experts” can be constructed depending on the nature of the task.
The significance of this approach lies not just in parallel processing. The real transformation is that context is separated. Each agent uses only the information necessary for its specific task and is not affected by irrelevant data. This structurally prevents the problems of context pollution and context rot described earlier. At the same time, each agent can be optimized according to its role, naturally improving the overall quality of the system. In essence, Subagents do not aim to create a single smarter model, but to solve problems by combining multiple well-suited models.

At this point, we encounter a significant shift. AI is no longer something to be used as a single tool, but something that must be designed as a system composed of multiple roles. The role of the user also changes. Instead of simply crafting better prompts, the user becomes a designer who decides how to decompose tasks. Although this shift is still in its early stages, it has the potential to significantly influence how AI is used in the future. In the next section, we will explore this structure in more depth and analyze how it actually works.
Core Elements of the Structure — Spawn, Isolation, Orchestration
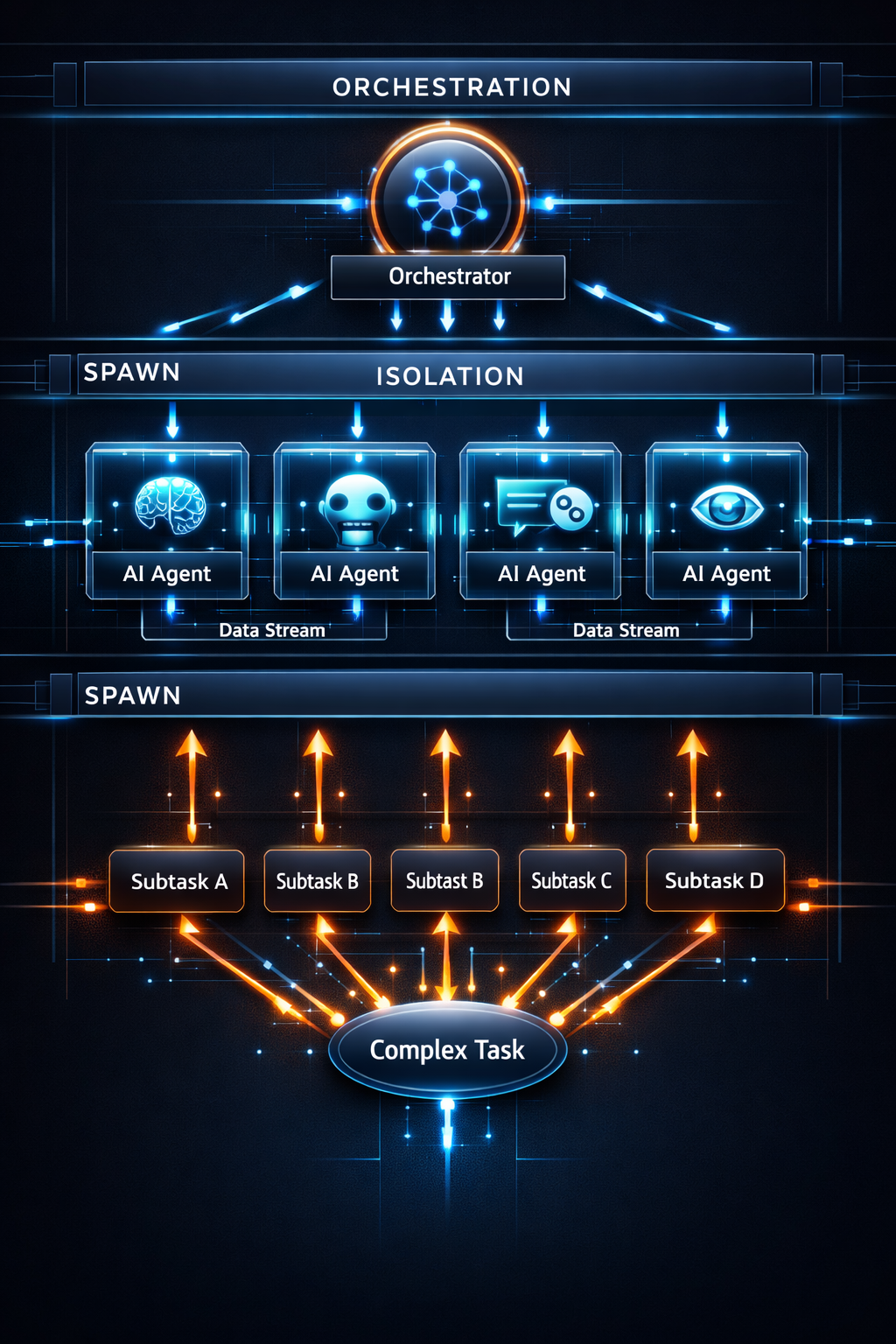
To properly understand the Subagents structure, it is necessary to go beyond the surface-level explanation that “multiple agents run simultaneously” and instead break down the three core principles that define its internal architecture. This structure is not merely a parallel processing system, but an architecture built on clear design principles. In particular, Spawn, Isolation, and Orchestration are not independent functions but complementary elements that together determine how the entire system operates. Without a clear understanding of these three components, Subagents can easily be misunderstood as simply “running multiple agents,” which often leads to flawed system design. Therefore, it is important to view this structure not as a set of features, but as a set of design units.
First, Spawn defines when and how agents are created. In the Subagents model, agents do not exist persistently—they are explicitly created when needed. This creates a fundamental difference from the traditional single-agent structure. Previously, all tasks were handled within a single continuous context. Here, however, a new execution unit is created for each task. This goes beyond simple resource allocation. Because each task begins independently, it is free from residual influence from previous tasks. In this sense, Spawn is not merely about creation—it is about establishing a new starting point for reasoning.
Next, Isolation is the most critical element in this structure. Each agent operates within a completely separate context and does not share its internal state with others. This is not just a matter of separating memory—it means that the reasoning process itself is fully independent. Errors or distortions that occur in one agent do not propagate to others, allowing each agent to focus entirely on its own task. This structure fundamentally eliminates the problems of context pollution and context rot discussed earlier. At the same time, each agent can use a different model or configuration, enabling the system to tailor the environment to the nature of each task. In this sense, Isolation represents the core value of the Subagents architecture.
Finally, Orchestration ties all of these processes together. The mere fact that multiple agents run independently does not automatically produce meaningful results. There must be a process that collects the outputs of each agent, assigns follow-up tasks when necessary, and ultimately integrates everything into a single coherent response. This role is handled by Codex. Orchestration is not just scheduling—it is a higher-level layer that manages the entire execution flow. Thanks to this layer, users do not need to control complex execution logic directly; they can operate the system through high-level instructions. Ultimately, these three elements combine to form not just a feature, but a complete execution model.
Fundamental Differences from a Single LLM — Understanding Through Comparison
When we compare the Subagents structure with the traditional single-LLM approach, it becomes clear that the two are not simply different in scale—they are based on entirely different philosophies. In the traditional approach, a single model absorbs all information and performs all reasoning within a unified context. This structure is simple, intuitive, and highly effective for smaller problems. However, as tasks grow in complexity and require different types of reasoning, this approach becomes increasingly inefficient. When diverse tasks are mixed within a single context, the model struggles to determine what information to prioritize.
In contrast, the Subagents structure eliminates this issue at the design level. Tasks are separated from the outset, and each agent handles only the information relevant to its role. This difference goes beyond execution—it directly impacts scalability and system stability. In the traditional structure, as tasks become more complex, the context grows larger and quality tends to degrade. In Subagents, however, as the number of tasks increases, only the number of agents grows, while the complexity of each agent remains constant. This allows the system to scale to more complex problems in a much more stable way.
Another key difference lies in where intelligence resides. In the traditional approach, intelligence is concentrated within a single model, and the user’s role is to use that model as effectively as possible. In Subagents, intelligence is distributed across multiple agents, and the user’s role shifts to designing how these agents are composed. In other words, while prompt writing was previously the central skill, now structural design becomes the core focus. This is not just a technical shift—it fundamentally changes how AI is used. Subagents do not replace a single LLM; they introduce an entirely new paradigm for problem-solving.
The Most Important Shift — A Structural Solution to the Context Problem
The most significant change introduced by Subagents is the shift in how context is handled. In traditional LLM usage, the primary challenge has been how to construct and manage a single context effectively. Users needed to remove unnecessary information, organize relevant details in the right order, and carefully craft prompts so that the model could interpret them correctly. This process became a discipline of its own, known as prompt engineering. However, all of these efforts were ultimately attempts to optimize a single context—they did not change the underlying structure.
Subagents fundamentally overturn this approach. Instead of optimizing a single context, they divide it into multiple independent contexts. Each agent operates using only the information necessary for its specific task and is unaffected by other agents’ data. This shift does more than improve efficiency—it changes the nature of the problem itself. With separated contexts, each task gains clear boundaries, and the model is no longer disrupted by irrelevant information. As a result, both the stability and accuracy of reasoning improve simultaneously.

This transformation requires a shift in mindset. Previously, the question was “how can all this information be organized within one context?” Now, the question becomes “how should this task be divided?” In other words, problem-solving moves from a prompt-centric approach to a structure-centric one. In this process, the user is no longer just someone who formulates requests—they become a designer of systems. Subagents are both the tool that enables this shift and the structure that demands it.
At this point, we approach a key conclusion. Overcoming the limitations of LLMs is not about building more powerful models, but about changing how models are used. Subagents represent one of the clearest examples of this direction. Of course, this approach does not solve every problem and may introduce new complexities. However, in terms of addressing the fundamental constraint of context, it offers a solution at an entirely different level. In the next section, we will explore how this structure is applied in real-world problem solving and in what situations it creates meaningful advantages.
Toward Designing AI — A Role-Based Agent Structure
One of the most significant changes introduced by the Subagents structure is that it fundamentally alters how we use AI. Previously, the key was to give the clearest possible instructions to a single model. Users focused on refining their questions and organizing the necessary information effectively. However, in a Subagents environment, this approach is no longer sufficient. Since no single agent handles everything, the first question is no longer “what to ask,” but “how should this task be divided?” At this point, the user’s role shifts from a simple requester to a system designer.
This shift naturally leads to a role-based structure. To solve a single problem, multiple agents with different characteristics are configured, each focusing on a specific role. For example, one agent may focus on exploring the codebase, another on identifying errors, and another on applying fixes. This structure is not accidental—it converges toward a form similar to how humans collaborate. Each role complements the others, improving the overall quality of the system. The key point is that these roles are not just about task distribution, but about separating different modes of reasoning.
As a result, the importance of design increases significantly. The outcome depends on how roles are defined, what models and configurations are assigned to each role, and how they are connected. In a well-designed structure, each agent focuses on its role and the overall quality improves. In a poorly designed structure, however, confusion can increase instead. In particular, if the boundaries between roles are unclear or if too much responsibility is assigned to a single role, the system regresses to the problems of a single-agent structure. Therefore, effectively using Subagents requires the ability to design how problems are decomposed and roles are defined.
This transformation goes beyond technical changes—it reshapes how we perceive AI itself. AI is no longer a single intelligent tool, but a system composed of multiple components. The user becomes the designer of that system and shares responsibility for its outcomes. From this perspective, Subagents are not just a new feature, but a signal of the evolution of how AI is used. In the next section, we will examine how this structure is applied in real-world scenarios and where it creates meaningful differences.
Real-World Use Cases — Where the Difference Truly Emerges
The value of Subagents cannot be fully understood through theoretical explanations alone. It becomes clear when we examine the types of problems where this structure creates meaningful differences. A representative example is tasks such as code review or codebase analysis. These tasks do not involve finding a single correct answer—they require simultaneous evaluation from multiple perspectives. In a traditional single-agent approach, one model must consider all perspectives at once, often leading to important aspects being overlooked or distorted. In contrast, the Subagents structure allows each perspective to be handled by a separate agent.
For instance, one agent can focus on tracing execution flow, another on identifying security vulnerabilities, and another on reviewing test coverage. When each agent processes only the information relevant to its role, the overall depth of analysis naturally increases. Moreover, because the outputs of agents do not interfere with one another, important perspectives are less likely to be overshadowed. The final response becomes a synthesis of multiple viewpoints, enabling a much more balanced analysis than a single agent could provide.
This structure is effective not only in code review but also in tasks such as complex feature implementation or large-scale refactoring. By dividing the work into stages and assigning agents to each stage, the overall process can be managed more reliably. In cases where different types of reasoning are required, separating roles instead of relying on a single model reduces the likelihood of errors. Importantly, Subagents are not merely a tool for increasing speed. They directly impact what kinds of problems can be solved more effectively. In other words, Subagents demonstrate their true value in specific categories of complex problems.
However, this structure is not necessary for all tasks. In simple question-answering or short tasks, it may introduce unnecessary complexity. Therefore, it is important to determine when Subagents are appropriate. This decision should be based not only on task size, but also on the diversity and complexity of reasoning required. In the next section, we will examine the practical limitations of this structure and the key considerations for its use.
Practical Limitations — Cost, Complexity, and Misuse
Subagents are undeniably powerful, but they are not a universal solution. The first factor to consider is cost. Since each agent operates independently, token usage increases compared to a single-agent approach. This is not just a matter of execution time—it directly translates into higher operational costs. As the number of agents increases, this cost grows linearly, meaning that excessive decomposition can lead to inefficiency. Therefore, when using Subagents, it is essential to balance structural benefits against cost.
Another challenge is design complexity. Previously, the focus was on crafting a good prompt. Now, the more critical question is how to structure the entire system. Decisions must be made about how to divide tasks, define roles, and connect them. This requires a deeper level of thinking than simple configuration, and poor design can degrade result quality. In particular, overlapping roles or unclear boundaries can lead to conflicts between agents or unnecessary duplication of work.
Finally, one of the most common issues is over-decomposition. When first encountering Subagents, it is tempting to divide tasks as much as possible. In reality, this is not always effective. Creating too many agents results in overly small task units, making the overall process inefficient. It can also introduce unnecessary complexity when integrating results. The key is not to divide as much as possible, but to divide appropriately—a decision that comes from experience and careful design.

These limitations are not weaknesses of Subagents, but rather natural costs of adopting a new structure. No technology is optimal for all situations, and Subagents are most effective within specific problem domains. Therefore, to use this structure effectively, it is crucial to understand when it should—and should not—be applied. Based on these criteria, we will explore in the next section the broader implications and direction of this approach.
Conclusion — AI Is Shifting from a Tool to a System
Looking back at what we have explored so far, Subagents are not merely a feature but a shift that redefines how we interact with AI as a whole. Previously, everything revolved around a single model, and the key question was how effectively we could use that model. As a result, we invested significant effort in refining prompts and optimizing context. However, this approach never escaped the assumption that everything must be solved within a single context. Subagents break this assumption, encouraging us to solve problems by separating tasks and assigning roles. This is not just an improvement in efficiency—it is a transformation in how we perceive and approach problems.
What is particularly important is that this shift changes the role of the user. We are no longer just people who “ask well” to a single model. Instead, we become designers who decide how to structure multiple agents, assign roles, and connect them into a coherent workflow. In this process, the required skill is no longer about crafting better sentences, but about structurally decomposing problems. Determining how to divide tasks, where to draw boundaries, and how to integrate results becomes the core challenge. In other words, the skill of using AI is gradually moving into the domain of system design.

This transformation is likely to have a significant impact on how AI is used in the future. The single-model approach will still remain effective in certain areas, but it will increasingly reveal its limitations when dealing with complex problems. In contrast, a role-based agent structure can become more stable as the scale of the problem grows. This is not just a matter of performance, but of scalability and maintainability. Instead of relying on one large model to handle everything, breaking problems into smaller units and managing them separately is an approach already proven in software design. Subagents can be seen as the application of this principle to the domain of AI.
Of course, this structure is not the right answer in every situation. As discussed earlier, there are real constraints such as cost, complexity, and design difficulty. But what matters is the direction. We are no longer focused on how to use a single model better. Instead, we are moving toward figuring out how to combine multiple models and agents effectively. This shift will happen gradually, but ultimately AI will be understood not as a single tool, but as a system composed of multiple components.
In the end, the meaning of Subagents is clear. LLMs should no longer be understood as a single intelligence, but as a collection of multiple units with defined roles. The quality of outcomes depends on how this structure is designed and utilized, making it not just a matter of usage technique but of system design. We are still at an early stage, but the direction is evident. AI is moving from “using it well” to “designing it well,” and Subagents are one of the starting points of that transformation.