
The Invention of Copyleft — A License Designed to Protect Freedom
When the concept of open source first emerged, ensuring the freedom of software was not a simple problem. In the early computer industry, software was often treated as an accessory to hardware, more like a bundled tool than an independent product. However, by the 1980s, software had begun to grow into a standalone industry, and code itself was increasingly recognized as a valuable corporate asset. Many companies kept their programs proprietary, and source code became more tightly controlled. In this environment, the culture of freely sharing and modifying software was rapidly disappearing.
One of the most prominent figures to challenge this shift was Richard Stallman. He believed that software was not merely a product, but a product of knowledge and collaboration, and argued that developers should be able to freely share code. This vision led to the creation of the GNU Project. The goal of GNU was not simply to build a new operating system, but to restore an environment where software could be freely used and modified. However, this effort faced a critical problem. Simply releasing code did not guarantee that its freedom would be preserved.
What happens if someone takes freely available code, modifies it slightly, and redistributes it as proprietary software? In that moment, the original freedom disappears. In other words, making code available is not enough to protect freedom—it requires a mechanism to enforce that freedom over time. This is where the concept of Copyleft emerged. Copyleft is not just a license that permits sharing; it is a rule that requires all derivative works to maintain the same freedoms. It both allows freedom and enforces its propagation.
This idea was formalized in the GNU General Public License (GPL). The core principle of GPL is simple: if you modify or extend code under this license and distribute it, your changes must also be released under the same GPL terms. In other words, if someone builds new software using community code, the result must also return to the community. This structure goes beyond a legal clause—it functions as a kind of social contract, designed to preserve collaboration across the entire software ecosystem.
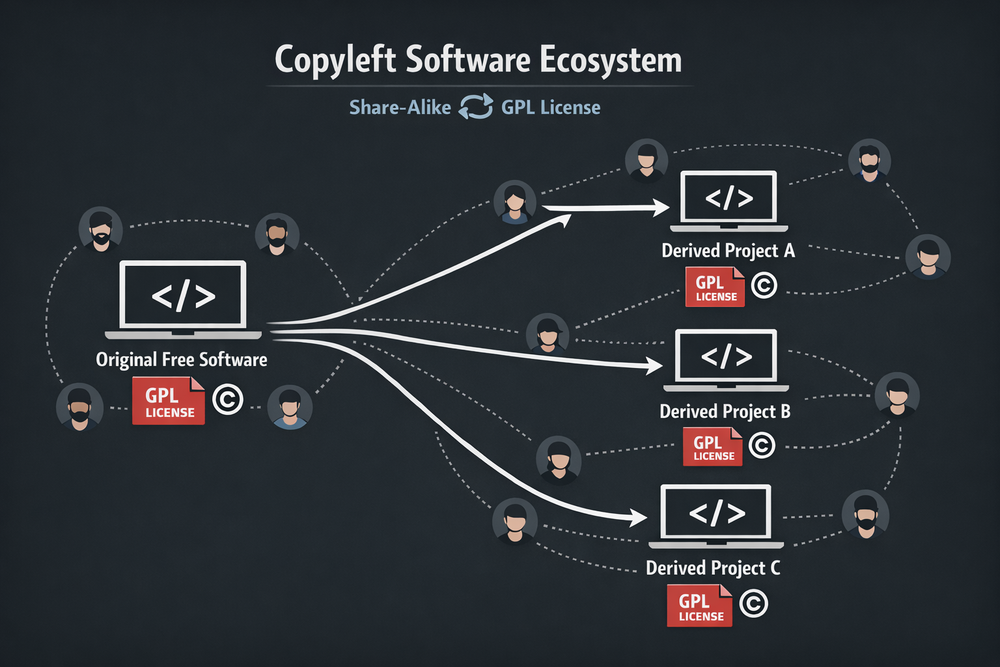
How Copyleft Works — The Structure by Which GPL Protects Code
To understand Copyleft, it is necessary to examine how the GPL actually works. Many people think of GPL simply as a license that requires source code to be disclosed, but in reality, it is a far more sophisticated structure. GPL does not directly protect the software itself—it regulates how software is distributed. In other words, it does not restrict the act of using code, but it applies specific rules the moment that code is distributed externally. These rules revolve around three key concepts: copying, derivative works, and distribution.
For example, if someone copies a program licensed under GPL and distributes it to others, that program must still remain under the GPL. This is a relatively straightforward rule. However, the true power of GPL lies in its treatment of derivative works. If new features are added or a program is extended based on GPL code, the resulting work must also be released under GPL. Because of this rule, Copyleft does more than preserve freedom—it actively expands it. Once code enters the GPL ecosystem, it continues to propagate under the same conditions of freedom.
This structure has had a profound impact on the open source world. A representative example is the Linux kernel. The Linux kernel is developed under the GPL, which has required countless companies and developers to disclose their modifications when extending or adapting it. As a result, the Linux ecosystem did not become a platform controlled by a single company, but instead grew into a massive collaborative project involving developers around the world. In this sense, Copyleft is not merely a tool for protecting code—it functions as a rule that enforces collaboration.
In this regard, Copyleft is clearly distinct from other open source licenses. Licenses such as MIT or BSD allow code to be used freely, but they do not require derivative works to adopt the same license. Someone can take MIT-licensed code, build a commercial product, and keep the source closed without violating the license. GPL, however, does not allow this option. Once GPL code is used, the freedom of that code must be preserved. Because of this structure, Copyleft is sometimes seen as burdensome for companies, yet at the same time, it is recognized as a powerful mechanism for protecting the open source ecosystem.
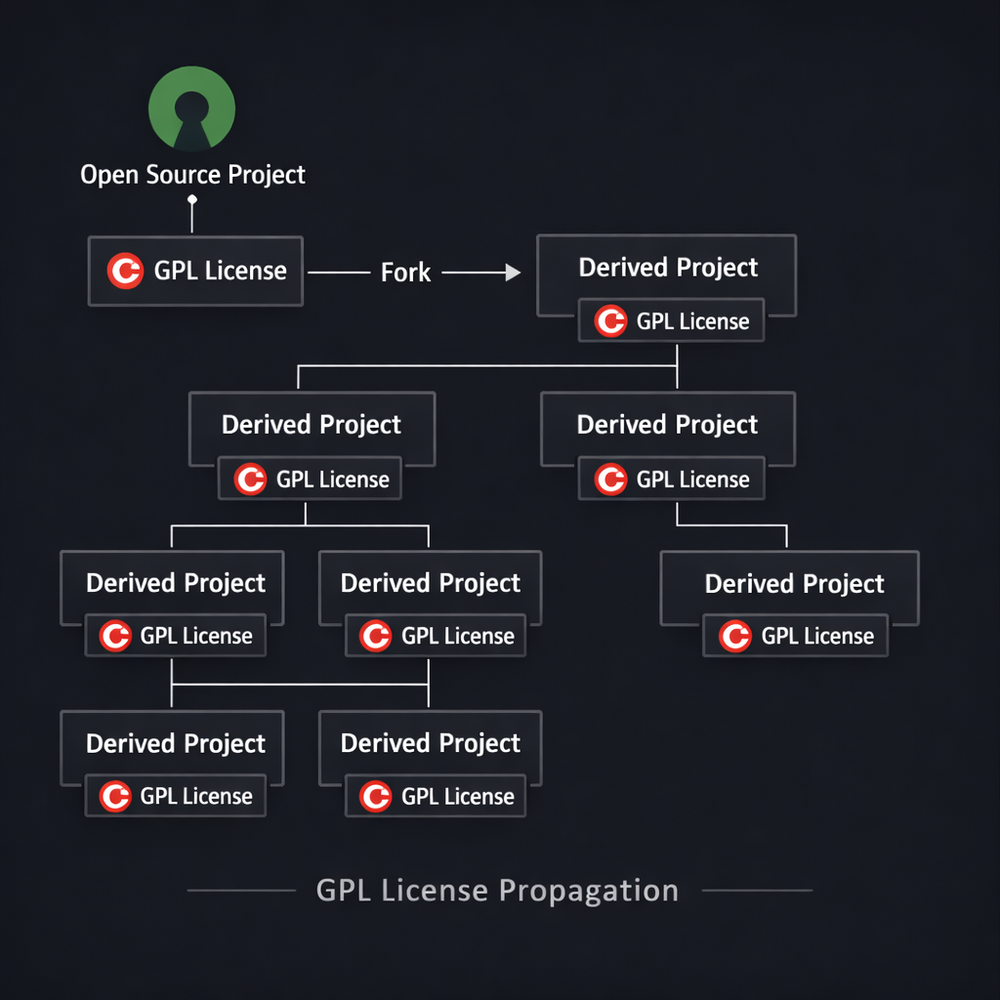
The Assumption Copyleft Relies On — A World Where Humans Write Code
The structure of Copyleft is highly sophisticated, but it is also built on a specific historical assumption. That assumption is surprisingly simple: code is written by humans. In the software development environments of the 1980s and 1990s, this fact was so obvious that no one questioned it. Writing code was the work of skilled developers, and building software required significant time and cost. In such an environment, code itself was a valuable resource, and copying or modifying code was considered a critical issue.
It is precisely at this point that the design philosophy of Copyleft emerges. Copyleft protects freedom by regulating the copying and redistribution of code. If someone copies or modifies code to create a new program, that program must preserve the same freedoms. In other words, Copyleft is a license designed not around the act of creating code, but around the act of copying code. In the era of human developers, this approach was highly rational. The process of code creation was relatively transparent, and it was possible to track who wrote what code.
However, this structure contains an important assumption: that code is created in a linear process. That is, an original piece of code exists, and new code is produced by copying or modifying it. Within this framework, the relationship between original and derivative code can be analyzed relatively easily. By comparing similarities or examining development histories, it is possible to determine whether something is a derivative work. Copyleft functions reliably on top of this development model.
But as the software development environment began to change, this assumption also started to break down. Code generation tools, autocomplete systems, and template-based generators gradually automated the process of writing code. More recently, generative AI has pushed this transformation even further. Developers can now create programs without directly writing code. By describing functionality or providing requirements, AI can generate the code itself. In such an environment, the question of “who wrote the code” becomes increasingly ambiguous.
It is at this point that the traditional assumptions of Copyleft are put to the test. Copyleft was designed to regulate copying, but AI can generate code without copying it directly. In other words, code with the same functionality as the original can be produced without directly using the original code. If this approach becomes widespread, how should the protective structure of Copyleft operate? This question goes beyond a simple licensing debate—it forces a rethinking of the fundamental structure of software development itself. And it is precisely from this point that the Copyleft debate in the age of AI begins.
What Changed with the Arrival of AI — A Paradigm Shift in Code Production
The assumption that Copyleft relied on was relatively simple: humans write code, and others copy or modify that code. Therefore, controlling copying and distribution was sufficient for licensing. However, with the rise of generative AI, this structure has begun to break down at a fundamental level. In recent years, the most significant change in the development environment has not been the speed of writing code, but the way code itself is created. Developers no longer need to write algorithms from scratch. They describe a problem, the AI proposes code, and the developer reviews and refines it. Code creation is increasingly shifting from direct human labor to a generation process mediated through conversational interfaces.
A representative example is AI coding assistants such as GitHub Copilot. Systems like Copilot and Claude Code go beyond simple autocomplete—they can generate entire functions or even modules. When a developer inputs a few lines of description, the model suggests a code structure based on learned patterns. In this process, the developer becomes both the author and the editor of the code. In other words, the origin of code is no longer a single human source, but a collaborative process between human and AI. This shift goes beyond productivity gains and begins to affect the legal nature of code and the structure of licensing.
This transformation is particularly significant because it weakens the scarcity of code. In the past, code that implemented a specific function held substantial value. Writing algorithms required time, and coding was a specialized skill. However, with AI code generation models, the same functionality can now be produced quickly in multiple ways. In other words, there can be countless implementations of the same solution. In such an environment, originality of code becomes less important than problem definition and system design.
In the era when Copyleft was designed, code copying was the central issue. But in the age of AI, the problem appears differently. AI can generate new code that performs similar functions without copying existing code directly. This shift forces a rethinking of Copyleft’s core logic. Copyleft was designed to ensure that copied code preserves the same freedoms, but in a world where AI regenerates code, the very concept of “copying” becomes ambiguous. At this point, Copyleft begins to directly collide with changes in the technological environment.
Can AI Bypass Copyleft — Rewrite as a New Strategy
The most direct point of collision between AI code generation and Copyleft emerges in the concept of “rewrite.” Copyleft licenses operate based on the relationship between original code and derivative code. In other words, if existing code is modified or extended, the resulting work must preserve the same license. However, AI code generation tools introduce a new possibility that can blur this relationship. Instead of modifying existing code directly, a developer can ask AI to produce new code that performs the same function in a different way.
Consider this situation more concretely. Suppose a project is released under the GPL license. A developer studies the structure of that project and then describes a specific function to an AI. The model generates new code based on that description. If this code is not identical to the original, is it merely a rewrite, or is it a derivative work? This question carries significant weight in the Copyleft debate. If AI-generated code is not considered a copy of the original, it could be argued that it can be distributed under a different license.
This debate has already surfaced in real open-source communities. The recent controversy surrounding the license change in the Python ecosystem’s chardet project is closely tied to this issue. Some maintainers argued that rewriting the code using AI tools justified a license change. Others criticized this approach as an attempt to circumvent the spirit of Copyleft. The controversy went beyond a single project and became an example of how software licensing might be interpreted in the age of AI.
However, there is another layer to this problem. AI code generation models do not operate solely on a specific project’s code—they are trained on vast amounts of open-source data. Even if the generated code is not a direct copy of a particular project, it may still reflect patterns learned from the training data. As a result, AI-based rewriting is unlikely to completely neutralize Copyleft. Instead, it is more likely to introduce new forms of legal ambiguity and dispute. Ultimately, the issue is no longer just about the form of the code, but about how the process of code generation itself should be interpreted.
Copyleft’s Legal Defense Line — Criteria for Determining Derivative Works
Despite arguments that AI code generation could weaken Copyleft, it is difficult to conclude that Copyleft has been completely neutralized. This is because software licensing is not judged solely based on the form of the code, but also on the development process and the flow of information. In copyright law, when determining whether something is a derivative work, the key factor is not just similarity between codes, but how the original code influenced the creation of the new code. In other words, even if the code does not appear similar, it may still be considered a derivative work if the original code played a significant role in the development process.
These criteria have appeared repeatedly in past software disputes. One representative case is the Google v. Oracle lawsuit. In this case, the core issues were whether API structures are subject to copyright protection and whether a new implementation constitutes a derivative work. Although the court ultimately ruled in favor of Google, an important point is that the decision considered not only the code itself but also the development process and functional necessity. Legal judgments are therefore not based on simple code comparison, but on an analysis of the entire context in which the code was created.
A similar issue is likely to arise in AI code generation. For example, if a developer inputs code from a specific open-source project into an AI and requests it to “rewrite it differently,” the result may be interpreted not as entirely new code, but as a derivative work of the original. On the other hand, if only a functional description is provided and the AI generates code independently, the result may be considered a completely new implementation. This distinction depends less on the form of the code and more on the flow of information.
In this sense, Copyleft still maintains an important line of defense. Copyleft is not merely a system for protecting code itself, but a rule designed to preserve the collaborative structure of the software ecosystem. The emergence of AI code generation does not automatically eliminate this rule. On the contrary, as AI tools become more deeply involved in the development process, the question of how to define the scope of Copyleft’s application is likely to become even more critical. At this point, Copyleft begins to be reinterpreted not just as a licensing clause, but as a social rule for sustaining cooperation in software development.
The Philosophical Dilemma of Copyleft — Is AI the Enemy of Free Software
The debate surrounding Copyleft cannot be explained purely as a legal issue. This is because Copyleft has always carried meaning beyond a legal document. It was built on the philosophical foundation of the free software movement, centered on the idea of “user freedom.” The freedom advocated by this movement is not simply the right to use software for free. It includes the right to understand, modify, and redistribute programs. To preserve these freedoms, source code must be open, and any derivative work must maintain the same freedoms. Copyleft was designed precisely to protect this principle.
This philosophy has long been a central pillar of the open-source ecosystem. Copyleft encouraged developers to share code while preventing it from being absorbed into proprietary systems. However, with the emergence of AI code generation, this philosophical structure now faces new questions. If anyone can generate code with the same functionality using AI, what meaning does Copyleft retain? In the past, certain functionalities required access to specific project code. Now, they can be implemented simply by describing the problem. In this context, how should the “freedom of code” that Copyleft sought to protect be redefined?
Some developers argue that AI could weaken the foundation of Copyleft. If AI can reproduce the same functionality without directly referencing existing code, the license propagation rules enforced by Copyleft may become increasingly difficult to apply. However, an opposing perspective is equally possible. The goal of the free software movement was to prevent code monopolies and enable users to understand and modify software. If AI provides code generation capabilities to everyone, it could actually expand the ideals of free software to a broader scale. In this view, AI is not an enemy of Copyleft, but rather a technology that realizes its philosophy in a new way.
This debate goes beyond technological change—it raises questions about the future direction of the software ecosystem itself. Copyleft was a rule designed to sustain collaboration, but AI may fundamentally alter the need for collaboration. In an era when code was a scarce resource, sharing and cooperation were essential. But in an environment where code can be generated almost infinitely, the nature of collaboration may evolve. Whether Copyleft will continue to play a central role, or whether a new model of free software will emerge, remains uncertain. What is clear, however, is that the Copyleft debate has expanded beyond licensing into a broader question of software philosophy.
The Future of Copyleft — How Will Licensing Evolve
As AI code generation becomes deeply integrated into software development, discussions about the future of Copyleft are becoming increasingly active. Traditional software licenses were designed for an environment where human developers wrote code. The author and distributor of code were relatively clear, and the origin of code was generally traceable. However, as AI models begin to participate in the code generation process, this structure is becoming far more complex. The “author” of code is no longer a single human developer, but increasingly a collaborative system involving both humans and AI models. In such an environment, existing licensing frameworks struggle to fully explain or govern these new dynamics.
In particular, the relationship between AI training data and generated code is creating new legal debates. Training datasets may include vast amounts of open-source code, and the output generated by models may reflect those influences. Under these conditions, it remains unclear how Copyleft licenses should apply. Some researchers explore whether the AI model itself could be interpreted as a derivative work, while others argue that only the generated code should be evaluated. This debate extends beyond a purely technical issue—it requires reconsidering the legal status of both data and algorithms.
At the same time, as AI models emerge as a new type of software artifact, the question of model licensing has become a major topic. Some projects attempt to manage model weights and training data under separate licensing schemes, diverging from traditional open-source approaches. For example, certain AI projects release models while imposing restrictions on specific uses. These efforts represent experiments in a new direction, distinct from Copyleft, but they also reflect an ongoing search for new models of software sharing in the AI era.
Amid these changes, Copyleft is unlikely to disappear entirely. Instead, it may evolve into new forms. When Copyleft first emerged, it was itself a reinterpretation of existing copyright structures. In the same way, its principles may be reshaped to fit the technological realities of the AI age. For instance, if an AI model is trained on open-source code, new rules might emerge governing how code generated by that model can be distributed. While such approaches are still experimental, they can be seen as attempts to preserve the core philosophy of Copyleft—the propagation of freedom—within a fundamentally new technological landscape.
Conclusion — Is Copyleft Over? And the Next Question
Copyleft has functioned as a central rule in the open-source ecosystem for decades. It is not merely a license that requires source code disclosure, but a social mechanism designed to sustain software collaboration. Copyleft was created to protect the freedom of code and to ensure that this freedom extends to derivative works. Thanks to this structure, many open-source projects have avoided being absorbed into proprietary software and have maintained independent ecosystems. Countless projects, including the Linux kernel, have grown under the protection of Copyleft, shaping the open-source landscape we see today.
However, the rise of generative AI presents a new challenge to this structure. AI can generate code with similar functionality without directly copying existing code, forcing a reconsideration of Copyleft’s core premise centered on copying and distribution. At the same time, AI drastically lowers the cost of code production, fundamentally altering the economic structure of software development. In this changing environment, the role Copyleft will play remains uncertain. Some argue that Copyleft will weaken, while others suggest it may evolve into a stronger or new form.
What is clear is that the Copyleft debate is no longer just about licensing—it is expanding into a broader question about the entire structure of software production. AI is still a tool for developers, but its impact is profound. It is reshaping how code is produced, how collaboration occurs, and even how ownership of software is defined. Copyleft now faces the need to redefine its role within this transformation. Perhaps its future depends less on specific legal clauses and more on how the software community chooses to collaborate and share knowledge.
This naturally leads to the next question. As AI code generation becomes widespread, the software ecosystem is beginning to function not just as a collection of projects, but as a vast interconnected supply chain. AI models learn from massive amounts of code and generate new software from that knowledge, creating connections that differ from traditional open-source development flows. In this context, should AI models be seen merely as development tools, or as a new form of software supply chain? The next article will explore this question, examining the emerging structure of software ecosystems shaped by AI.