
Why Does Open Source Always Appear “Free”
For many developers, open source is something that requires no special explanation. We download code from GitHub every day, install libraries through package managers, read documentation, and sometimes fix bugs or add features. In this process, we rarely pay money. Countless pieces of software are provided for free through repositories like npm, PyPI, Maven Central, and Homebrew, and in most cases, there is no cost to using that code. As this experience repeats itself, open source naturally becomes strongly associated with the idea of “free software.” Just as the internet itself seems to exist without cost, open source also appears to be a technology culture detached from any notion of expense.
But with just a little reflection, a curious question emerges within this structure. Who creates, maintains, and bears the cost of the countless libraries and frameworks we use every day? It is intuitively difficult to accept that software used by tens of millions of developers is sustained purely through volunteer effort. In reality, if you look into the issue trackers of many open source projects, you will often find that there are only a handful of maintainers, and sometimes even a single developer has managed a project for years. The moment such a project becomes part of the internet’s infrastructure, it moves far beyond the realm of a simple hobby.

The reason open source “appears free” lies in a combination of technical characteristics and cultural factors. Once software is created, the cost of replication is almost zero, and distributing it globally through the internet is relatively easy. When this is combined with open source licenses that allow free use and modification, software begins to circulate almost like a public good. Developers naturally consume these results and use them to build other software. In this process, the concept of cost rarely becomes visible.
However, at this point, an important question arises. What kind of economic structure actually sustains software that is so widely used? It is certainly true that open source appears free, but that does not necessarily mean that no costs exist. In fact, the opposite may be true. Perhaps we simply do not see where those costs are occurring. This question naturally leads to the next discussion: how central is open source within the internet infrastructure we rely on every day?
Most of the Software That Powers the Internet Is Open Source
If you take even a brief look at modern internet infrastructure, it is not difficult to see that open source lies at its core. The countless websites we visit run on Linux servers, and web requests are handled by open source web servers such as Nginx or Apache. Data is stored in open source databases like PostgreSQL or MySQL, and applications run on open source languages and runtimes such as Python, Java, and Node.js. Any company operating container-based infrastructure almost inevitably uses Kubernetes, an open source project. All of these are not just development tools—they are the core infrastructure that actually powers the internet.
This reality creates an interesting paradox. Even though a significant portion of the internet economy runs on open source, the software that forms its foundation is often provided for free. From large tech companies to small startups, everyone builds services on top of open source and generates enormous economic value from it. However, the projects that created this infrastructure rarely receive economic rewards at the same scale. This structure gives the open source ecosystem a uniquely unusual economic model.

This phenomenon has become even more pronounced with the rise of cloud and platform businesses. Companies build services on top of open source software and generate revenue from those services. For example, even if core technologies such as databases or messaging systems are open source, companies can offer them as cloud services and create entirely new business models. In this process, open source plays a role in rapidly spreading innovation, while also raising the question of where the economic value is actually flowing.
Ultimately, we are faced with another question. If these technologies sit at the very center of internet infrastructure, shouldn’t they naturally form a massive industry? It does not seem realistic or sustainable that technologies used by billions of people are maintained purely through the passion or volunteer efforts of individual developers. So what does the actual economic structure of the open source ecosystem look like? As we follow this question, we begin to uncover a reality that many do not expect: most open source projects generate far less revenue than one might assume.
But Most Open Source Projects Fail to Make Money
Considering the central role of open source in internet infrastructure, a natural expectation arises. Technologies that are so widely used should, in theory, be supported by a substantial industry behind them. Indeed, some open source companies have built highly successful businesses. However, when we take a broader view of the open source ecosystem, a very different reality emerges. Among the millions of projects in the GitHub ecosystem, only a tiny fraction have stable revenue models. Most projects are maintained by individual developers or small teams, and their work is, in effect, closer to volunteer effort than to a sustainable business.
This structure sometimes reveals itself in unexpected ways. A representative example is the left-pad incident on npm in 2016. When a small library consisting of just a few lines of code was removed from the npm repository, countless projects that depended on it failed to build simultaneously, causing widespread disruption across the internet development ecosystem. This incident was more than just a package management issue. It revealed that part of the internet’s infrastructure depended on a project maintained by an individual developer, and that project was sustained without meaningful economic compensation.

A similar issue appeared in the field of security. When the Heartbleed vulnerability in OpenSSL was disclosed, many people were shocked to learn that a library responsible for critical internet security was maintained with extremely limited resources and manpower. The fact that essential software used by countless companies and government institutions depended on just a few developers exposed a structural problem within the open source ecosystem. These cases are not mere coincidences—they reveal the fundamental characteristics of the open source economic model.
At this point, we are confronted with an important question. Why does software that is so widely used fail to receive sufficient economic compensation? Open source is clearly a powerful model that accelerates innovation and fosters collaboration, yet at the same time, its very structure makes it difficult to generate revenue. To understand this issue, it is not enough to look at a few examples. We need to examine the economic structure of open source more deeply. And it is precisely here that the story begins—why open source is inherently a system where making money is difficult.
Why Is Open Source Structurally Difficult to Monetize
As discussed earlier, many open source projects play a critical role in internet infrastructure, yet often fail to receive sufficient economic compensation. This phenomenon cannot be explained simply as a series of unfortunate cases affecting a few projects. Rather, the structure of open source itself makes revenue generation inherently difficult. The traditional economic model of the software industry is based on scarcity. Companies or products that secure a monopolistic position in the market can generate high profits. However, open source is fundamentally distant from the idea of monopoly. Anyone can read the code, modify it, and, if necessary, fork it into a new project. This freedom is the strength of open source, but at the same time, it is also what makes building a business model more challenging.
Software inherently has near-zero replication cost. Traditional commercial software, however, artificially restricts this replicability through licensing and controlled distribution. Companies must pay to use the software, and in return receive specific features and support. In contrast, open source deliberately removes these restrictions. Anyone can download and use the code, and even create a new distribution that provides the same functionality. While this accelerates the spread of innovation, it also makes it difficult for a single company to secure exclusive revenue. An increase in users does not necessarily lead to an increase in revenue.
Another issue is that the user and the buyer are not the same. Companies actively use open source, but that usage does not necessarily translate into direct revenue for the project. For example, a company might operate a service worth hundreds of millions of dollars using an open source database, yet the database project itself may receive no financial return. In this structure, the value provided by open source projects is enormous, but capturing that value directly is extremely difficult. As a result, many projects end up with a large user base while remaining economically fragile.
These structural characteristics show that open source is not just a method of software development, but a unique economic model. Open source can evolve rapidly through collaboration, yet traditional revenue models from the software industry do not apply easily. This leads to an important question: how do open source projects that actually make money generate their revenue? To understand this, we need to first examine the oldest revenue model in the history of open source.
The Oldest Revenue Model of Open Source — Support and Services
When open source first emerged, the most natural revenue model was not the software itself, but the services surrounding it. The code is provided for free, but companies require various forms of support to operate that software in real-world environments. Installation, operations, security updates, incident response, and performance tuning are not solved simply by downloading the code. Especially for companies running large-scale systems, stability and reliability are critical, which creates a need for professional support. It is precisely at this point that open source companies began to build revenue models.
For example, companies can sell contracts that provide long-term maintenance and technical support to enterprise customers. Organizations using open source databases or operating systems want immediate access to expert assistance when issues arise. These contracts are less about selling software and more about ensuring stable operations. In fact, many companies were able to adopt open source more safely through such support agreements. This support model played a crucial role in enabling the widespread adoption of open source in enterprise environments.
Another form of revenue model is education and consulting. Introducing complex open source technologies into enterprise environments requires specialized knowledge. As a result, many open source companies offer technical training programs and architectural consulting services. These services provide real value to enterprise customers without restricting the free use of the software itself. In an environment where new technologies emerge rapidly, the demand for such expertise remains consistently strong.
This model has been the oldest and most stable approach in the history of open source. Many companies have grown based on this model, and some have achieved significant success. However, over time, the limitations of this approach have also become increasingly apparent. Service-oriented businesses have characteristics that differ from the rapid scalability typically seen in the software industry.
But Service Models Alone Struggle to Build Large Companies
Support and service-based revenue models have long played an important role in the open source ecosystem. However, this approach has clear limitations. Service businesses fundamentally depend on human time and expertise. As the number of customers grows, more engineers and consultants must be hired, and as the organization scales, operational costs increase accordingly. This structure is very different from selling software products. Traditional software companies can generate high margins by selling a product developed once to many customers, but service businesses cannot scale as quickly.
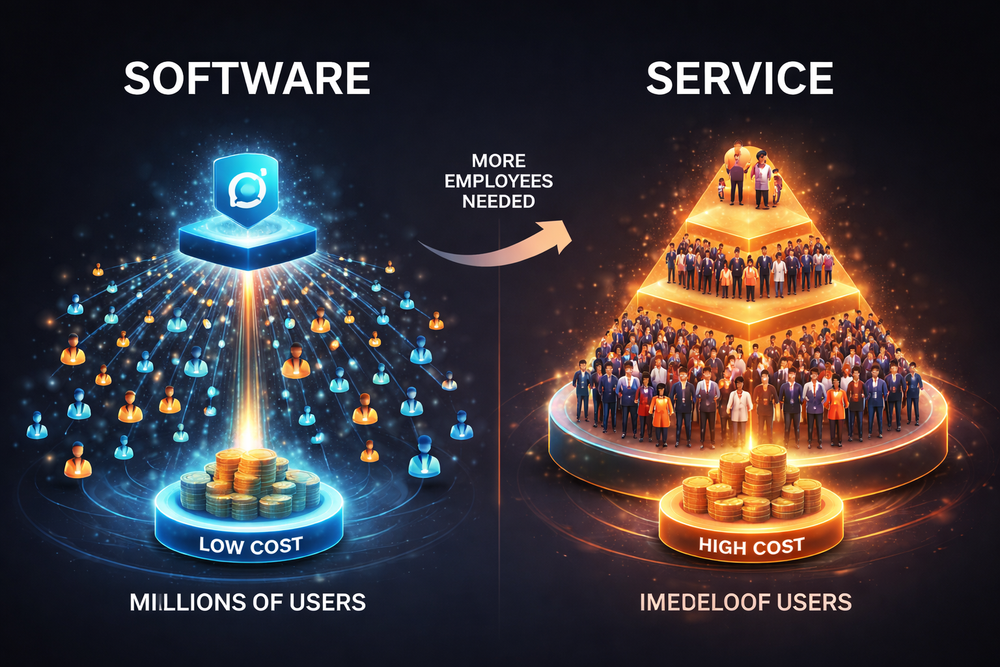
This difference carries significant implications in the software industry. One of the reasons technology companies achieve high valuations is scalability. A single product can be delivered to millions of users simultaneously, increasing revenue without proportional increases in cost. However, service models lack this scalability. As customers grow, service personnel must also increase, which naturally raises the cost structure. As a result, it is difficult for a service-centered model alone to produce the explosive growth curves seen in software companies.
This issue became even more pronounced in the cloud era. Many companies began to prefer using open source software as cloud services rather than operating it themselves. Cloud platforms build new services on top of open source software and generate revenue from them. However, in this process, the original open source projects do not necessarily receive the same economic benefits. In many cases, platform companies capture a larger share of the value.
This situation raised a new question for open source companies. If simply selling support and services is not enough to achieve sufficient growth and revenue, what alternatives exist? To answer this, many companies began experimenting with new strategies. And from this process emerged various business models that would become key trends in the open source ecosystem. In the next section, we will examine how these changes began and how open source companies started exploring new paths.
New Experiments Emerge — Open Core and Licensing Strategies
As the limitations of support and service-based models became increasingly clear, open source companies began searching for alternative approaches. It became evident that selling technical support alone was not sufficient to achieve long-term growth or high company valuations. Especially with the rise of the cloud and SaaS era, software companies had to compete within a new economic structure. In this context, a variety of open source business experiments began to emerge. Among them, the most widely known approach is the model commonly referred to as “Open Core.”
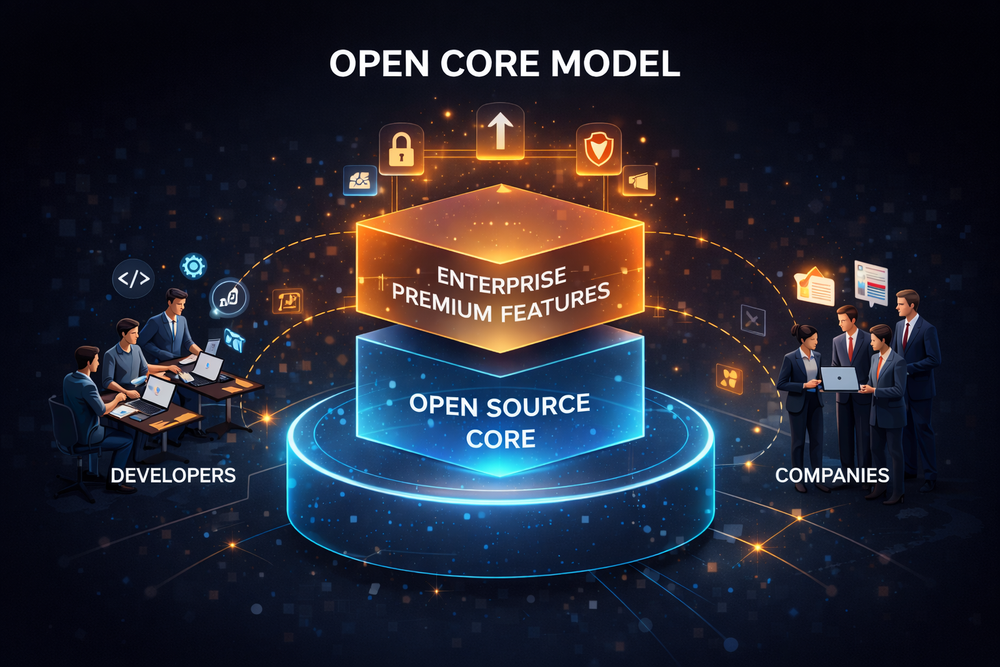
The Open Core model makes core functionalities available as open source while offering certain features required by enterprise customers as commercial products. For example, a basic database engine or search engine can be used freely by anyone, while advanced security features, management tools, or large-scale cluster operations are provided as paid offerings. This model can be seen as an attempt to balance the advantages of open source with the revenue structure of commercial software. The developer community can still freely use and improve the code, while companies can generate stable revenue from enterprise customers.
However, the emergence of the Open Core model also sparked new debates. Some developers criticized this approach as potentially undermining the spirit of open source. When only peripheral features are open while core capabilities remain proprietary, questions arise about whether it can truly be called open source. On the other hand, from a business perspective, there are arguments that some level of commercial functionality is necessary to sustain an open source-based company. This debate is not merely technical—it represents a collision between the philosophy of open source and its economic structure.
During this period, licensing strategies also began to play a critical role. Some companies maintained existing open source licenses while offering separate commercial products, while others introduced new licenses with stronger restrictions. These changes demonstrate that open source is evolving from a simple development methodology into an increasingly complex economic model. At the same time, these experiments lead directly to the key question of the next section: business strategies around open source are not merely matters of choice, but are deeply connected to the structure of the technology industry itself.
Open Source Is Not Just Technology, but an Economic Model
The discussion so far reveals an important truth. We often understand open source as a development method or a collaboration culture, but in reality, a far more complex economic structure exists behind it. Open source projects evolve through collaboration among developers around the world, yet at the same time, various companies build businesses and compete on top of them. Some companies sell support services, others adopt the Open Core model, and still others create new services on top of cloud platforms. All of these activities ultimately converge on a single question: how can a sustainable economic structure be built within an open system like open source?
This question matters because open source is no longer a peripheral technology—it has become the core infrastructure of the software industry. A significant portion of the modern internet runs on open source, and its scale and influence continue to grow. If these technologies become difficult to sustain, the impact will inevitably extend to the entire internet ecosystem. Therefore, understanding the economic model of open source is not merely a concern for developer communities, but a critical issue for the entire technology industry.
What is particularly interesting is that open source does not operate under a single model. Some projects are sustained through corporate sponsorship, others evolve in combination with commercial products, and still others are maintained purely by community effort. This diversity shows that open source remains an area of experimentation. There is no single, fully established economic structure—rather, multiple approaches are being tried simultaneously.
Ultimately, open source can be seen as an ongoing economic experiment. Within a massive collaborative system involving developers and companies worldwide, new business models continuously emerge and disappear. Some succeed, others fail. And through this history of experimentation, the open source ecosystem has taken its current form. So among these experiments, which cases have been the most successful? In the next discussion, we turn to that question by examining one of the most well-known companies in the history of open source.
Next Story — How Did Red Hat Become a $34 Billion Company with Open Source
Through the discussion so far, we have explored the unique economic structure of open source. It is a technology that forms the core of internet infrastructure, yet most projects fail to generate sufficient revenue. At the same time, some companies have experimented with various strategies to build successful businesses within this structure. The emergence of models such as Open Core, service-based businesses, and licensing strategies all stems from this background. Among these experiments, however, one case stands out in particular.
That case is Red Hat. Red Hat built an enterprise software business based on the open source operating system Linux and grew into a multi-billion-dollar company. In 2019, it was acquired by IBM for approximately 34 billion dollars—one of the most symbolic events in the history of open source. At a time when many believed that open source could not generate revenue, one company demonstrated that it could achieve massive success.
Red Hat’s success was not a coincidence. Instead of simply selling open source software as-is, they designed a business model centered on the stability and reliability that enterprises actually needed. While leveraging the openness of Linux, they simultaneously created products and services suitable for enterprise environments. This strategy later became an important reference point for many open source companies.
In the next article, we will explore this story in greater detail. How did Red Hat build a massive company on top of open source? And does that model still hold in today’s cloud era? By following these questions, we will gain a deeper understanding of one of the most compelling success stories in open source business.
