How Development Was Done Before Git
Version control in software development was not always the obvious, fundamental concept it is today. In the present, we are accustomed to an environment where every change to code is automatically recorded, where we can revert to any previous state at any time, and where multiple people can work simultaneously while conflicts are systematically managed. However, such an environment only became established relatively recently. Before Git emerged, the development environment was far more primitive, and many aspects relied heavily on the developer’s attention and memory.
Early developers managed versions by appending suffixes such as _final, _final2, or _real_final to file names. This was not merely a joke but a widely used practice in reality. Since there was no structured way to manage the history of code changes, developers had to manually copy files and rename them to distinguish versions. While this method could somewhat work for individual tasks, it quickly revealed its limitations in collaborative environments. It was nearly impossible to track who modified which part of the code and for what purpose those changes were made.
To address these issues, early version control systems such as CVS (Concurrent Versions System) and Subversion (SVN) emerged. These systems adopted a centralized structure in which a code repository resided on a central server, and developers interacted with it to update their code. This approach made a basic level of collaboration possible and allowed for a certain degree of tracking code changes. However, these systems were fundamentally centralized, which introduced several constraints. Without network connectivity, work became difficult; branching and merging were complex and costly operations.
Most importantly, version control systems of that era did not transform the way developers thought about development; they merely added minimal tooling on top of existing workflows. Developers still remained “people who modify files and upload them,” and collaboration continued to be a process filled with conflicts and confusion. As project scale increased, this structure generated even more problems. These limitations became especially pronounced in large-scale open source projects.
At this point, the key issue was not simply the lack of tools, but that the development paradigm itself had not evolved. Collaboration remained difficult, code changes were still risky, and the systems in place could not keep up with the rapid growth of project scale. Eventually, these problems accumulated to a level that could no longer be ignored.
The first place where this limitation became critical was not in small personal projects, but in massive projects involving developers from around the world. The most representative example of this was the development of the Linux kernel.

The Problems Faced by Linux Kernel Development
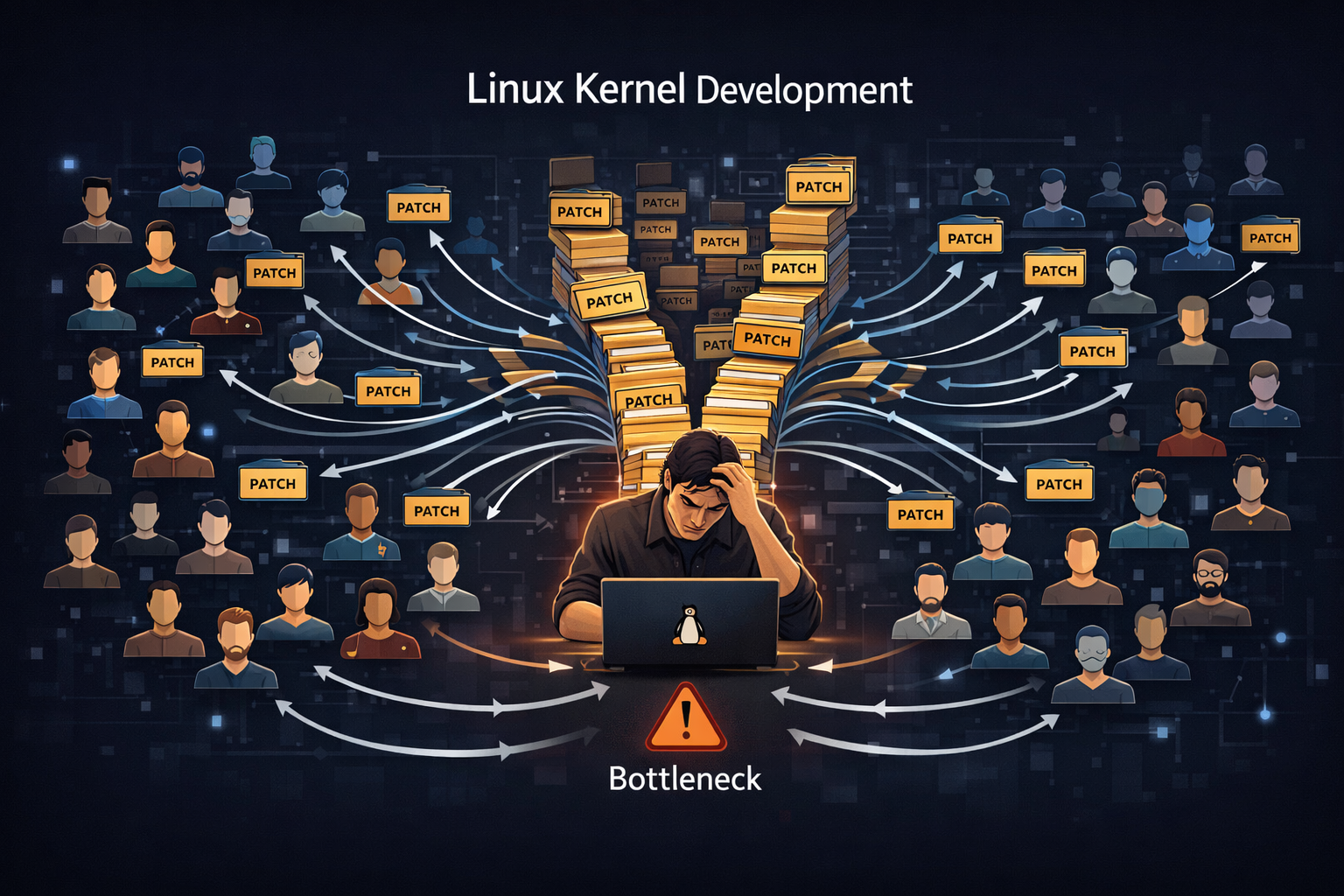
The Linux kernel was not just a software project. It was, in essence, an ecosystem with thousands of developers participating simultaneously. Each developer wrote code in different environments, produced changes at their own pace, and those results ultimately had to be integrated into a single kernel. In such a structure, the most critical problem was not simply writing code, but how to integrate and manage those changes.
In its early days, Linux development was centered around mailing lists. Developers shared patches they created via email, and other developers reviewed them or suggested modifications. Ultimately, Linus Torvalds would accept those patches and integrate them into the kernel. This approach worked effectively in the beginning. The project was relatively small, and the number of contributors was limited, so human judgment and communication were sufficient to manage the process.
However, as Linux grew rapidly, the situation changed completely. A large number of developers began submitting patches simultaneously, and conflicting changes became increasingly frequent. Determining which changes should be applied first and which modifications were more appropriate became a complex process. Moreover, all of this responsibility was concentrated on a single individual, Linus Torvalds.
This was not merely a matter of being “busy.” Tracking code changes became increasingly difficult, and the likelihood of mistakenly integrating incorrect patches grew higher. In a situation where multiple developers were working simultaneously, failing to systematically manage change history could jeopardize the stability of the entire project.
The more fundamental issue was that this structure was not scalable. The Linux kernel continued to grow, but the collaboration model could not keep pace. As the number of developers increased, inefficiency also increased. Eventually, this problem reached a point where it could no longer be ignored.
At this point, the Linux development team had to make a decision. Should they continue with the existing approach and accept increasing chaos, or should they introduce new tools to fundamentally change how collaboration worked? They ultimately chose the latter. And that decision led to the adoption of BitKeeper.
However, this choice would soon give rise to another problem.
The Adoption of BitKeeper and an Uneasy Coexistence
The decision by the Linux kernel development team to adopt BitKeeper was not simply a matter of replacing one tool with another. It was an attempt to transform the very nature of collaboration. BitKeeper was, by the standards of the time, a highly advanced version control system. It provided efficient tracking of code changes and supported distributed collaboration to a certain extent, offering a level of capability that clearly surpassed existing tools.
With BitKeeper in use, Linux kernel development began to take on a much more structured form. Tracking changes became easier, and multiple developers could work simultaneously while managing conflicts more effectively. Most importantly, the burden that had previously been concentrated on Linus Torvalds began to be partially distributed. At this stage, BitKeeper was no longer just a tool—it had become a core piece of infrastructure that made Linux development possible.
However, this transformation came with a clear limitation. BitKeeper was not open source software; it was a proprietary product developed by a company called BitMover. Although it was provided free of charge to Linux kernel developers, the terms of its usage could be changed at any time. In other words, the world’s largest open source project had become dependent on the decisions of an external company.
This situation gradually created discomfort within the open source community. Technically, BitKeeper was an extremely useful tool, but philosophically, it was difficult to accept. The fact that an open source project depended on proprietary software felt contradictory. Some developers criticized the use of BitKeeper, and attempts were made to find alternative solutions.
This tension persisted for some time, but eventually, it collapsed due to a single incident. And that incident would not only lead to a tool replacement, but would also mark the beginning of a new era.
The BitKeeper Incident — The Moment Everything Collapsed
BitKeeper had stabilized Linux kernel development to a certain extent, but at the same time, it was an unstable foundation that could collapse at any moment. That instability had long existed beneath the surface, but it eventually emerged through a single incident. This was not merely a technical issue or a licensing dispute. It was the moment when the fundamental tension between open source and proprietary software exploded into the open.
In 2005, some developers attempted to analyze BitKeeper’s internal protocols. This effort was not simply driven by curiosity, but was part of a broader attempt to break away from dependence on BitKeeper. However, BitMover regarded this as a clear violation of its license. As a result, BitMover decided to revoke the free usage rights it had previously granted to Linux kernel developers.
This decision was not just a matter of “losing access to a tool.” The entire collaboration infrastructure on which Linux kernel development depended disappeared overnight. In a project involving thousands of developers, the loss of a version control system effectively meant that development itself could come to a halt. This incident represented an existential crisis for the Linux kernel development team.
More importantly, this was not just an external shock. The structure in which an open source project depended on a proprietary tool was inherently fragile, and the same problem could occur again at any time. The BitKeeper incident was the moment that risk became reality. And from that moment, the Linux kernel development team reached a clear conclusion: they could no longer depend on external tools.

This incident was not simply the disappearance of a tool; it was the moment when a new tool became absolutely necessary. And this necessity was not something that could be solved externally. The Linux kernel development team found themselves in a position where they had to build their own tool.
At this point, the question was no longer “which tool should we use.”
The question had become “how do we create a tool that can solve this problem?”
Linus Torvalds Builds the Tool Himself
After the BitKeeper incident, Linus Torvalds made a swift decision. Instead of searching for a replacement tool, he chose to build one himself. This decision was not just a technical response; it was closer to a philosophical shift. It was a declaration that they would no longer rely on external tools, but instead construct a system tailored to their own needs.
When designing Git, Linus Torvalds established several clear principles. The most important was speed. The Linux kernel had a massive codebase, with a high volume of rapid changes. If the version control system were slow, development itself would inevitably become a bottleneck. Therefore, Git was designed from the beginning as a system that prioritized extreme performance.
Another crucial principle was data integrity. Git adopted a structure in which all changes are managed using SHA hashes. This was not merely an implementation detail, but a core design choice to ensure system reliability. It structurally prevents corruption or tampering of code history. This design would later play a key role in establishing Git as a trustworthy system.
The most significant shift, however, was the distributed architecture. Linus recognized that centralized systems fundamentally suffered from scalability issues. As a result, Git was designed so that every developer could have a complete copy of the repository locally. This was not just a technical difference—it was a decision that fundamentally changed how collaboration works.
Remarkably, the initial version of Git was created in just a few weeks. This fact may sound exaggerated, but Git was indeed developed at an astonishing pace. Of course, early Git was far from polished and not particularly user-friendly. But what mattered was not perfection—it was direction. Git was a tool designed to solve a specific problem, and its architecture was precisely aligned with that purpose.

At this stage, Git was not yet a world-changing tool. It was simply a tool created to restore Linux kernel development. However, its design was fundamentally different from existing systems. And that difference soon began to trigger much larger changes.
Now the important question becomes this:
What exactly made Git different from existing version control systems?
The Core Structure of Git — What Made It Different
The reason Git was fundamentally different from existing version control systems was not just a matter of features, but that it approached data in an entirely different way. Most traditional systems stored changes as “diffs”—that is, they recorded the differences between versions and built history from those differences.
Git, however, chose a completely different approach. Instead of storing differences, Git stores changes as snapshots. It records the entire state of the project at a given point in time and constructs history from these snapshots. At first glance, this approach might seem inefficient, but in practice it creates a system that is both extremely fast and highly reliable. Git avoids redundant storage by reusing unchanged data, maintaining efficiency even with a snapshot-based model.
Another critical aspect of Git is its use of hashes to identify all objects. Commits, files, and directories all have unique hash values determined by their content. This is not just an identification mechanism—it is a fundamental system for ensuring data integrity. If any data is altered, its hash changes, and the system can immediately detect it.
Git also introduced a radically different approach to branching. In traditional systems, creating a branch was expensive and complex. In Git, however, branches are essentially lightweight pointers, making them extremely fast to create. This difference had a profound impact on how developers work. Developers no longer feared branching and could experiment freely without risk.
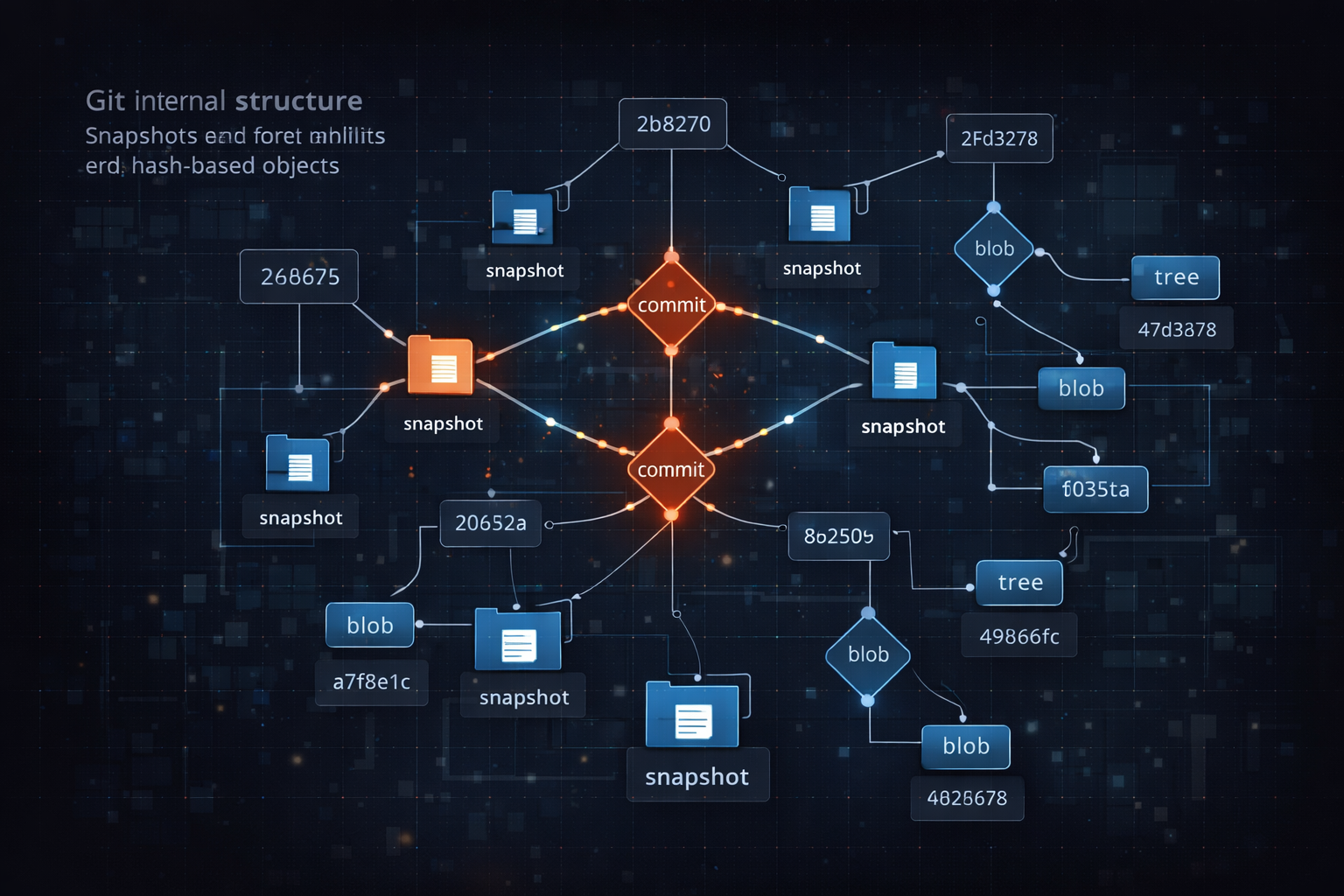
These structural differences did more than improve performance—they transformed how developers think. Git was no longer just a tool for managing files; it became a system for managing the flow of changes. And this shift would go on to deeply influence collaboration practices and the broader development culture.
At this point, Git was beginning to evolve beyond a tool for the Linux kernel—it was becoming the starting point of a new development paradigm.
The Paradigm Shift of Distributed Version Control
The most fundamental difference that set Git apart from existing version control systems was not its features, but its structure. At the core of that structure was the concept of Distributed Version Control Systems (DVCS). In traditional centralized systems, a single server acted as the source of truth, and developers performed their work by depending on that server. Every process—pulling code, making changes, and pushing updates—was centered around a central authority. While this model was simple and easy to understand, it was built upon a critical assumption: all work must be connected to a central system.
Git completely overturned this assumption. In Git, every developer has a full copy of the repository locally, including its entire history, and can perform all operations independently within their own environment. This structural shift may seem like a technical detail at first glance, but in practice, it fundamentally changed how developers interact with code. Developers can create commits, branch, and rewrite history without any network connection. In other words, they are no longer dependent on the state of a central system to make progress.
This change had a particularly profound impact on collaboration. In centralized systems, minimizing conflicts required coordinating work and carefully managing who changed what and when. In contrast, Git enabled developers to work independently and merge their changes later when needed. This transformed collaboration from a synchronization-centric model into a merge-centric model. Developers no longer needed to wait for one another, enabling parallel development at a scale that was previously difficult to achieve. This became especially powerful in large-scale projects involving many contributors.
Additionally, this structure significantly improved system resilience. Even if a central server failed, every developer’s local repository still contained the full project history. The system no longer relied on a single point of failure. This characteristic elevated Git beyond a mere development tool and positioned it as a collaboration infrastructure grounded in distributed system principles.
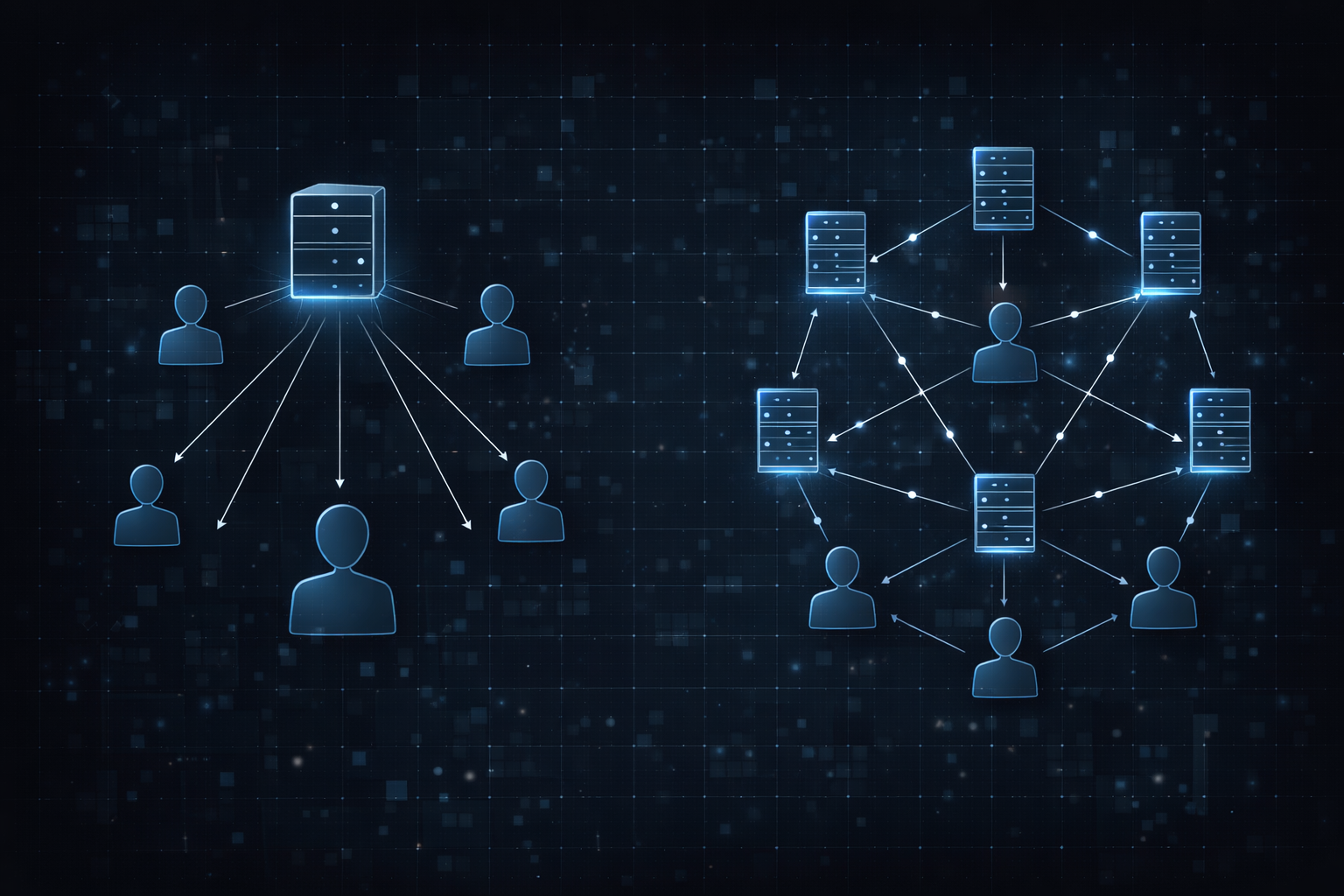
At this point, Git was no longer just a tool for the Linux kernel. It had become a new model that structurally solved the limitations of previous development practices. As this model began to spread to more projects, it gradually established itself as a new standard.
However, a change in structure alone does not immediately transform development culture. That transformation emerges gradually, as new practices and workflows build on top of the tool.
The New Collaboration Model Created by Git
The impact of Git extended far beyond its technical architecture. The real transformation emerged in the new collaboration model that formed around it. Git made branching extremely lightweight, and this alone fundamentally changed how developers approached their work. In earlier systems, creating branches was costly and complex, which discouraged their use. As a result, most development occurred on a single main line. With Git, however, creating a branch became nearly effortless, allowing developers to experiment freely without fear.
This shift naturally led to the concept of feature-based development. Developers began creating separate branches for individual features, working independently within those branches, and then merging them back into the main branch after sufficient review. This process organically integrated code review into the workflow, transforming collaboration from simple code sharing into a decision-making process. Code was no longer just written and shared—it was discussed, evaluated, and refined collectively.
Perhaps the most important change was in how merging itself was perceived. Previously, the goal was to avoid conflicts as much as possible. With Git, merging became an intentional and meaningful process. It required developers to actively decide how different pieces of work should be combined and which changes should be accepted. This elevated merging from a technical necessity to a central part of collaboration, reflecting the team’s standards and philosophy.
These collaboration patterns became even more defined with the emergence of platforms like GitHub. The concept of a Pull Request was not merely a request to merge code, but an interface for discussion, review, and shared decision-making. What Git ultimately created was not just a version control system, but a framework for developers to think, communicate, and make decisions together.
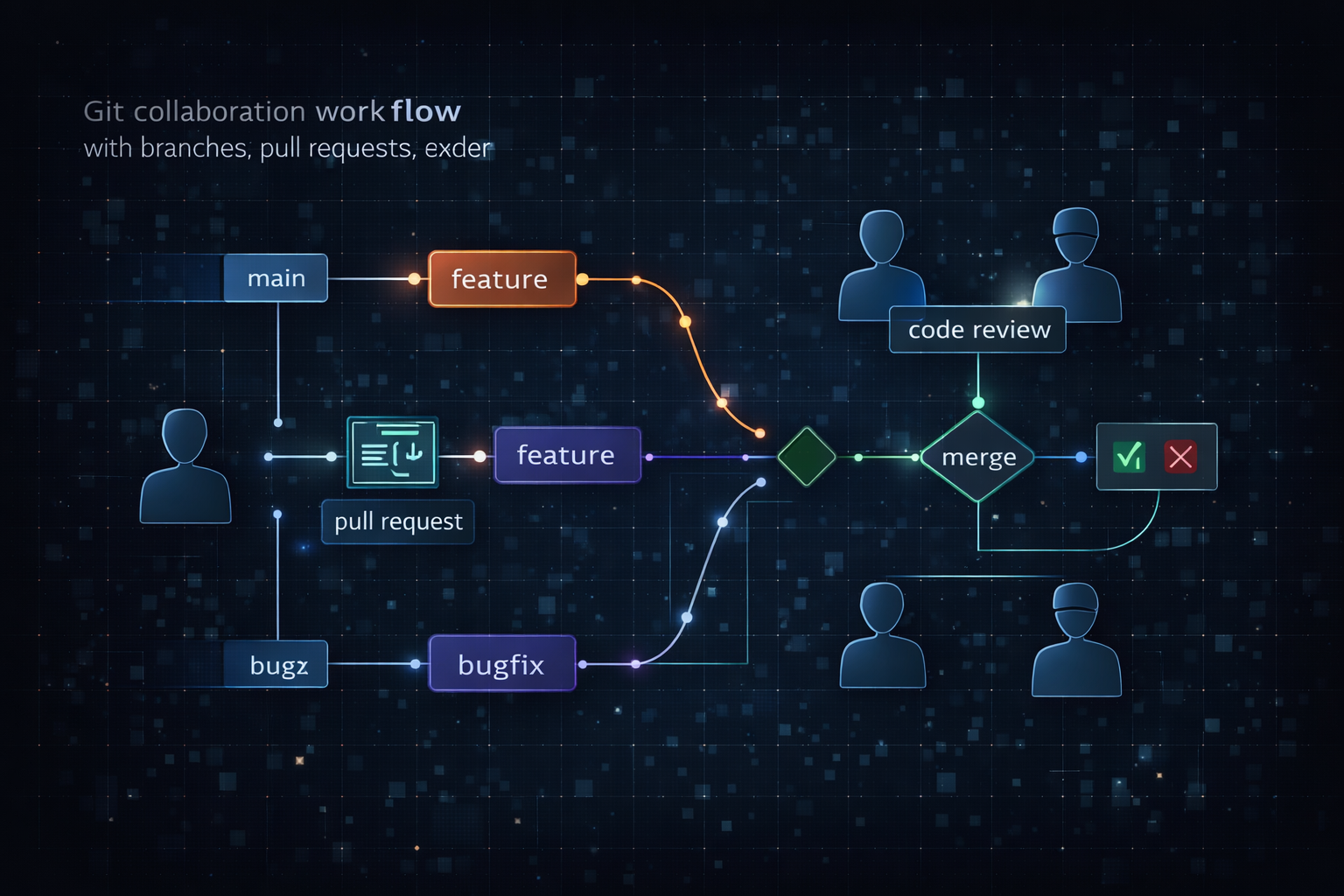
At this stage, Git could no longer be fully described as just a tool. It had become a system that defined how collaboration worked, influenced developer behavior, and shaped overall team productivity. This naturally leads to the next question.
How did such a powerful system become the global standard?
How Git Became the Standard
When Git was first introduced, it was a specialized tool built for the Linux kernel. It was not particularly user-friendly, and many of its concepts were unfamiliar to developers accustomed to existing systems. However, over time, Git began to spread across more projects, eventually becoming the standard used in nearly all development environments. This transformation cannot be explained by technical superiority alone.
One of the most critical factors was the expansion of the ecosystem built around Git. While Git itself was powerful, it was not enough on its own to transform development culture. The decisive turning point came with platforms like GitHub. GitHub, built on top of Git, made collaboration more accessible and exposed open-source projects to a much wider audience. It transformed Git from a purely technical choice into a social and cultural choice.
Git also integrated seamlessly with a wide range of development tools and environments. IDEs, CI/CD systems, and cloud platforms all began to center their workflows around Git. Choosing Git was no longer just about selecting a version control system—it became a foundational decision that shaped the entire development environment. As more projects adopted Git, it gradually became not just a popular choice, but a de facto standard.
An important aspect of this transition is that Git was not imposed as a standard. No single organization or authority mandated its use. Instead, it became the standard organically, as developers independently chose it based on its ability to solve real problems. This is what made Git’s dominance particularly significant—it was not enforced, but earned through widespread adoption.
At this point, Git is no longer just a tool tied to a specific project. It has become the foundation of modern software development and the standard by which collaboration is defined. And this trajectory does not stop here.
The collaboration model introduced by Git continues to expand through platforms like GitHub, ultimately connecting the entire open-source ecosystem into a single, interconnected network.
A Tool Born from Crisis, One That Changed Culture
When we trace Git’s story back to the beginning, its essence starts from a surprisingly simple point. Git was not a system created out of some grand vision or long-term strategic plan. It was merely a tool built to solve a single crisis—the very real problem of losing access to BitKeeper. Yet this simple origin gave Git a uniquely clear direction. It was not a tool designed to implement abstract ideals, but rather a system engineered to solve real, immediate problems.
This point is crucial in understanding how Git evolved. Git was never intended from the outset to be a universal tool for all developers. It was built specifically to support the extremely complex environment of Linux kernel development. That is why performance, integrity, and scalability were not optional features, but essential design requirements. And as a result, those design choices became a strong foundation that could be applied to virtually any other project. In other words, although Git was created to solve a specific problem, the way it solved that problem contained a universally applicable structure for problem-solving.
Git’s true impact, however, reveals itself beyond the technical domain. Git did not simply provide a tool for managing code; it redefined how developers collaborate. Before Git, collaboration was largely about avoiding conflicts and cautiously managing changes. After Git, collaboration became about actively creating branches, isolating changes, and integrating them through merges. This shift was not merely an improvement in efficiency—it represented a fundamental change in how developers perceive and work with code.

This transformation unfolded gradually, but it ultimately led to a clear outcome. Git was no longer just one of many tools—it became a fundamental prerequisite for development. Starting a new project effectively meant creating a Git repository, and collaborating meant working within a Git-centered workflow. In this sense, Git evolved beyond being a tool and became a precondition of the development environment itself.
What is particularly interesting is that this shift was not enforced by any central authority or standardization body. Git spread organically, becoming the standard through the collective choices of developers. This was not simply because Git was technically superior, but because it addressed real problems encountered in everyday development. In the end, Git did not survive because it was merely a “good tool,” but because it was a necessary tool.
And this is not where the story ends. The transformation initiated by Git was not a complete conclusion, but rather the beginning of a new phase. The distributed structure and collaborative model introduced by Git would soon expand further through platforms like GitHub, ultimately connecting the entire developer ecosystem into a unified network.
In that sense, Git was not the end—it was the beginning. And the next chapter of this story explores how a platform was built on top of Git, and how open source evolved into a fully connected ecosystem.