
I Never Intended to Build an App
I never started with the intention of building an app. There was no plan to target a specific market, nor any ambition to grow a service. It wasn’t even a side project driven by technical curiosity. In fact, it was closer to the opposite. While reading a book without any particular goal in mind, I encountered a very small inconvenience. It wasn’t significant, and it wasn’t something that demanded an immediate solution. But for some reason, that feeling didn’t go away. Once I noticed it, I kept encountering the same friction every time I read.
What matters here is not the size of the inconvenience, but its persistence. Most inconveniences fade over time. This one didn’t. It didn’t end when I finished reading; instead, it became more noticeable afterward. There was always something missing after closing the book. That sense of absence repeated itself and eventually solidified into a single question. What exactly am I missing? This question didn’t immediately translate into a functional requirement. It remained vague. So instead of trying to solve it, I simply observed it.
At this point, a critical assumption had already formed. The assumption that “something is missing.” The problem is that this kind of feeling easily turns into certainty without a clear definition. I accepted the discomfort as a problem and assumed it needed to be solved. But at that time, I couldn’t clearly explain what that problem actually was. It only felt real because it kept recurring. Every decision that followed originated from this undefined starting point. The attempt to solve the problem began, but the problem itself remained unstructured.
So the starting point of this story is not “I decided to build an app.” It is the opposite. I started without a clear plan, without a properly defined problem. And this state becomes the foundation for every design decision that follows. Looking back, this moment was the most critical point. Because every subsequent decision was built on top of this vague definition. This series begins precisely from that point.

The Nature of the Discomfort — The Misconception of “No Records”
When you keep tracing the discomfort, it eventually condenses into a single sentence. “There is no record.” While reading, time clearly passes, and actions accumulate. But the moment the book is closed, everything seems to disappear. How long I read today, when I stopped, how long I paused in between—these all become dependent on memory. And memory fades quickly. So I naturally reached a conclusion. The discomfort comes from the absence of records. This judgment seems intuitively correct.
However, there is a critical misconception hidden in this conclusion. I thought “there are no records,” but in reality, records were continuously being generated. The moment reading starts, the moment it stops, the amount read, the reason for interruption—these are all elements that can be expressed as data. The issue was not that data didn’t exist, but that it was not structured. In other words, the problem was not the absence of records, but the absence of a defined structure for those records. This distinction may appear subtle, but it leads to fundamentally different design outcomes.
The concept of a “record” is often mistaken as a single value. For example, “I read for 30 minutes today.” But this value is actually the result of multiple events. It includes when reading started, when it ended, and what happened in between. If you ignore that process and only store the result, the data becomes compressed. Compressed data is simple, but it loses explanatory power. At the time, I failed to recognize this difference. I assumed there were no records, and believed that adding records would solve the problem.
This is where the direction already begins to diverge. Simplifying a problem makes it seem easier to solve. But if that simplification removes the essence of the problem, every subsequent design will be built on a flawed foundation. Instead of asking how to define records, I focused on adding them. I never reached the stage of questioning the structure itself. Therefore, the statement “there are no records” was fundamentally a wrong problem definition. More precisely, I did not understand how records should be modeled.
This difference later becomes a dividing line in system design. A system that simply adds records and a system that represents the flow of time are completely different. The former is state-driven, while the latter is event-driven. At this stage, I did not understand that distinction. So the attempt to solve the problem began, but it was already heading in the wrong direction. This section exists to reveal exactly where that misalignment started.

Why Existing Apps Failed — The “Completion-Centric Model”
After defining the problem as the “absence of records,” the first step was to re-examine existing apps. Since countless reading apps already existed, it seemed reasonable to assume the solution was already there. And indeed, the apps were well-built. Their statistics were detailed, their designs polished, and their user experiences smooth. But as I continued using them, something felt off. Every app seemed to be oriented in the same direction. That direction was not the process, but the outcome.
Most apps were built around “completion.” Metrics like how many books were finished, how much of a yearly goal was achieved, ratings, and summaries were central. This structure is easy to understand. Outcomes are clear, measurable, and easy to compare. From a system design perspective, this is advantageous. But there is a hidden assumption behind this model. The assumption that the process of reading is not important. The process is treated as a means to an end, and only the result is considered worth recording.
This assumption shapes the user experience in a specific way. Users are guided toward the goal of “completion.” But this structure fails to answer certain types of questions. For example, how many attempts it took to finish a book, why reading stopped at a certain point, or how much time was actually invested. These are questions about the process, not the result. And process cannot be represented as a single value.
The key point here is that this is not a feature gap, but a limitation of the model itself. Adding more features does not solve the problem. Because the underlying data structure cannot accommodate those questions. Initially, I did not fully understand this distinction. I simply thought, “the features I want are missing.” But as I analyzed further, it became clear that the issue was structural. Existing apps were not wrong; they were solving a different problem.
Eventually, I reached a conclusion. What I was looking for was a fundamentally different type of data. Not outcomes, but flow. Not state, but time. Not a single value, but a collection of events. However, even this conclusion was incomplete. Because I still did not know how to model that data. So the next step begins. An attempt to redefine the problem, leading into the next collapse of design.
What I Wanted — Not “Results,” but “Flow”
After examining existing apps, what remained was not a simple dissatisfaction. It was not a matter of missing features, nor was it a problem at the level of poor UX. It was closer to a structural mismatch. What I wanted to see and what the apps were showing existed on entirely different axes. At first, I could not clearly articulate this gap, but as I continued using them, its shape gradually became clearer. What I was curious about was not “how much I read,” but “how I read.” However, existing apps did not deal with that question at all.
At this point, an important shift occurs. The problem definition changes from “there is no record” to “the direction of the record is different.” I no longer wanted to see results. Instead, I wanted to see the process itself. I needed to understand how many attempts it took to finish a book, why there were days I did not read, and where exactly I stopped in the middle. This kind of flow was not just data; it was a structure moving along a timeline. Because of that, it could not be expressed as a single value in the first place.
Here, a crucial realization emerges. I did not want to see data; I wanted to see the structure of time. This distinction is larger than it appears. Data can simply be stored, but a time structure must be designed. Time does not organize itself automatically. You must define the unit of segmentation, determine which events to record, and decide how they connect. And those definitions ultimately reshape the entire system. At this point, I began, for the first time, to look at the problem in the right direction.
However, this was still not a complete answer. The direction was correct, but there was still no method. Wanting to see flow is more of a declaration, and translating it into actual design requires many more decisions. Questions naturally follow: what should be the unit of division, what should be considered a single unit, which data is essential, and which can be discarded. These questions begin to dismantle the previously assumed simple model. At this point, the design develops its first crack.

The First Design — A State-Based Model (And Why It Was Wrong)
Even after recognizing the concept of flow, the first design attempt did not escape a simple structure. The most intuitive approach was a state-based model. There is a book as an entity, it has a state, and it has a progress value. This model is intuitive. Most systems are designed this way, so it is easy to accept without much thought. I also adopted this structure initially. Managing state at the book level and updating progress seemed sufficient.
However, this model quickly reveals its limitations. A state always describes only the “present.” Whether a book is currently being read, completed, or abandoned is meaningful at the current moment, but it does not explain how that state came to be. Progress is the same. A value like 60% does not tell you when that point was reached, whether the process was continuous or fragmented, or what happened along the way. This model is suitable for storing results, but it completely fails at reconstructing the process.
This problem cannot be solved by simply adding features. Attaching logs or histories on top of a state model does not fundamentally resolve the issue. The reason is that the underlying concept itself is incorrectly defined. A state is a compressed result of a timeline. Therefore, a state alone cannot represent the structure of time. I came to realize this during the design process. The model was not good because it was simple; it was losing something essential because it was simple.
At this point, a clear conclusion emerges. This model cannot contain the problem I am trying to solve. A structure centered on “current state” fundamentally conflicts with requirements centered on “process.” No matter how much it is extended, it cannot move in the desired direction. This realization signals that the design must be restarted. It is not about refining the structure; it is about changing the underlying concept itself. And at this moment, questions begin to explode.

The Moment Questions Explode — The Design Begins to Collapse
When the state-based model reveals its limitations, the design does not quietly fail. Instead, questions begin to surface all at once. Problems that were previously unconsidered emerge in rapid succession. For example, should the moment reading starts be recorded? Does a one-minute reading session still carry meaning? These questions may appear to be minor details, but in reality, they directly impact the structure of the model. How each question is answered determines the shape of the entire system.
What matters here is not the number of questions, but their direction. The increase in questions does not mean the problem has become more complex. Rather, it is evidence that the existing model cannot accommodate these questions. For instance, deciding where to store progress is not just about choosing a location. Depending on whether this value is treated as a state, an event, or a snapshot, the entire structure changes. If this question is not answered clearly, data consistency will eventually break, and the UI and logic will start to conflict.
At this stage, the design can no longer maintain stability. The previously established structure begins to shake piece by piece. A single small question forces a re-evaluation of the entire model. At this point, I realize something critical. The issue is not that I am asking too many questions, but that the original model was never designed to handle them. In other words, the design is failing to keep up with reality. And as this gap widens, maintaining the existing structure becomes increasingly difficult.
Ultimately, this phase is closer to a collapse than a revision. Attempts to solve problems while preserving the existing model become progressively inefficient. As a result, the options narrow down to one. The structure must be split again, and the concept of time must be brought to the center of the model. But this change is not a simple refactoring. It is a shift in how the system itself is perceived. From this point forward, a new design truly begins.
Starting to Split the Structure — Record / Session / Event
The moment the model could no longer absorb the questions, the choices narrowed down to two paths. Either keep the existing structure and keep patching it, or redefine the structure itself. The former is easier in the short term. You can add a few fields, handle edge cases in code, and things will seem to work for now. But this approach gradually turns the system into something that is harder and harder to explain. I had already tried going down that path a few times, and I knew the outcome was not good. So this time, I decided to change direction from the beginning.
The key was to abandon the idea of a single model. Previously, I tried to put everything into the unit of a “book.” State, progress, reading time—everything was expected to fit into a single object. But this approach itself was the problem. I was forcing data with different characteristics into the same layer. So I started separating them. The book-level state remained, but the actual act of reading was split into a separate unit, and the events that occur within that act were further separated.
This is where the three concepts of Record, Session, and Event emerged. Record maintains the state at the book level. Session represents the unit of actual reading time. And Event records the occurrences that happen within that session. The important point here is not that the model simply increased in number, but that the axis of time was explicitly separated. Previously, time-related information was buried inside the state, but now time itself has an independent structure. This change was not just a structural adjustment, but a shift in how the system is perceived.
However, even at this point, the design was not complete. In fact, more questions started to arise. Where does a Session begin and end? What criteria define an Event? How should the relationship between Record and Session be maintained? Separation means dividing responsibilities, but it also means defining the boundaries between those responsibilities. So this stage was less of a solution and more of the beginning of new problems. Nevertheless, one thing became clear. There was no going back to the previous state-based model.

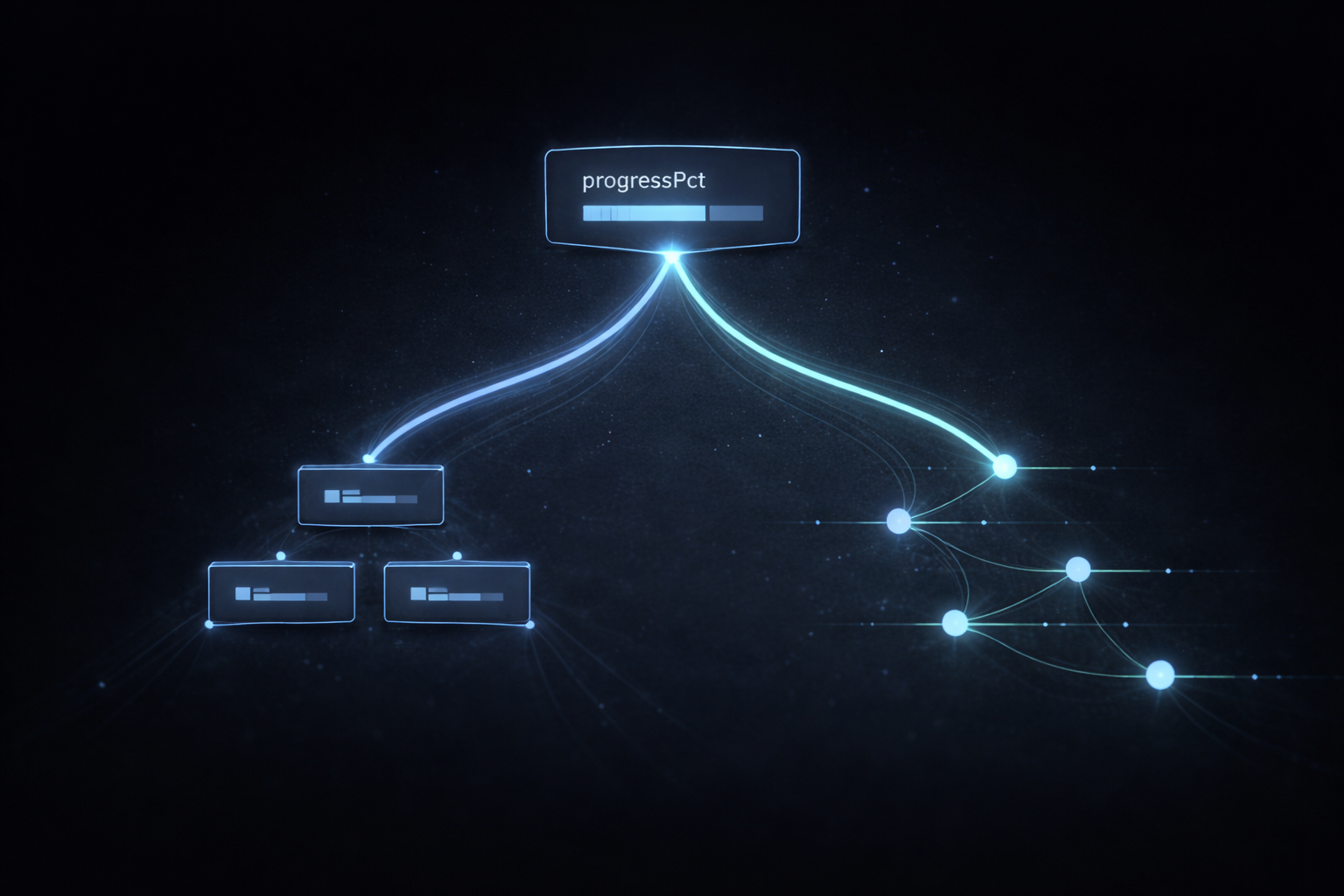
A Single Field, progressPct, That Revealed the Essence of the Design
As the structure began to split, elements that once seemed trivial started to take on entirely different meanings. A representative example of this was progressPct. At first, I assumed without much thought that this value should belong to the Record. It appeared to be information managed at the book level. Progress seemed like a property of the book’s state, so naturally it was included in the Record. This decision felt intuitive, and I moved on without questioning it.
But after separating Session and Event, the placement of this value started to feel wrong. Progress is not a fixed value. It changes every time a reading action ends, and in some cases, it can even decrease. If it is stored in the Record, the current state can be represented, but how that value was formed is lost. On the other hand, if it is stored in the Session, each point in time can be recorded, but the overall state is not immediately visible. This was not just a matter of where to store the data, but how to interpret it.
At this point, a critical shift occurred. Should progress be treated as a “current state,” or as a “snapshot at the end of a session”? Choosing the former leads back to a state-based model, while choosing the latter preserves a time-based model. I chose the latter. progressPct became a value recorded at the end of a session, and the collection of those values forms the overall flow. This decision may seem small, but it locks in the philosophy of the entire system.
In the end, this single field revealed the essence of the design. This was not about where to store a piece of data, but about how to model time. And with this choice, the system gained a clear direction. Should it be centered around state, or around events? At this point, I became certain that I could no longer return to a state-centered approach. The design was becoming clearer, but at the same time, it was also introducing new constraints.
Choosing Local-first — Not a Solution, but the Beginning of Another Problem
As the structure began to stabilize, the next question was where the system should reside. Most services naturally gravitate toward a server-centric architecture. Login, data synchronization, and backup are assumed as defaults. I initially considered this direction as well. But after thinking it through, it felt like an excessive choice for my case. Questions started to arise. Was it necessary to upload personal data to a server? Could a solo developer maintain a server reliably over time? How would the system behave in an offline environment?
Answering these questions gradually led me toward a local-first approach. All core data would reside within the device, and the app itself would be a self-contained system. This approach seemed simple. Reducing the server would reduce operational burden, and synchronization issues would appear to disappear. At first glance, it felt like a very reasonable choice. It even seemed like it would lower implementation complexity. But this decision was also built on a set of assumptions.
A local-first architecture trades simplicity for a different set of constraints. Data consistency must be fully handled on the client side, and state management becomes significantly stricter. Without a server acting as a mediator, all logic must maintain its own consistency. Moreover, when considering future expansion, this structure can become an even greater limitation. At this point, however, I did not fully recognize these implications. I assumed that reducing the server would reduce the problems.
In the end, this choice was also just another design assumption. Like the earlier state-based model, it too would eventually need to be validated. I thought I had solved the problem, but in reality, I had only shifted it in a different direction. The design was becoming more refined, but at the same time, it was creating new uncertainties. And this trajectory would once again be shaken significantly in the next stage.
Conclusion of This Section — I Failed to Properly Define the Problem
If you follow the flow up to this point, one recurring misconception becomes clear. I believed I was continuously solving the problem. I identified the discomfort that “there is no record,” and I tried to resolve it by creating structures, dividing models, and organizing data. Through that process, I was convinced that I was moving toward a more refined design. However, what actually happened was slightly different. I was not solving the problem; I was repeatedly redefining it. And while each redefinition became slightly more precise than the last, none of them were correct from the beginning.
The initial starting point was “there is no record.” This statement feels intuitive, but it does not actually describe the real problem. The next step shifted to “I want to see the flow.” This helped set a direction, but it was still not something that could be directly implemented. After that, the state model broke down, time units were separated, and an event-driven structure began to emerge. This process certainly appears like progress. However, what matters is that none of these changes were planned from the start. They happened because the existing design could no longer hold. In other words, the design did not evolve—it was pushed forward by its own limitations.
At this point, one thing must be made explicit. I did not start by trying to build an app. I did not start by trying to implement features. I started by trying to solve a problem. But I failed to define that problem correctly. As a result, the design kept shifting. I formed one assumption, and when it did not align with reality, I replaced it with another. This cycle may look inefficient, but in reality, it was inevitable. Because until the problem is properly understood, no design can remain stable.
In the end, the conclusion of this section is simple. I started from a fundamentally incorrect state. And that state did not disappear easily. In fact, it became more visible as the design progressed. But this realization is not a failure—it is a starting point. The moment you recognize that the problem was wrongly defined is the moment a real design can begin. This series continues from that exact point. In the next section, I will go deeper into how the domain design—built on top of this flawed problem definition—collapsed once again, and why that collapse was inevitable.
