
Unfamiliar Terms, Familiar Behavior — We Are Already Using Polyfills and Ponyfills
The terms polyfill and ponyfill may feel somewhat unfamiliar at first. At a glance, they might seem like a specific type of library or pattern, or to some, merely informal jargon created by the community. However, these two concepts are far more deeply embedded in the daily lives of JavaScript developers than they appear. We use them every day without even realizing it. We simply don’t recognize them by name.
Developers typically install packages naturally when starting a new project or adding features to an existing one. In this process, we take it for granted that instead of implementing functionality ourselves, we rely on code that someone else has already written. The problem is that these packages do not only contain feature implementations. They also include code designed to handle cases where certain environments may not support specific features, code that guards against unexpected runtime conditions, and code that absorbs differences across various runtimes. In other words, we are not just consuming functionality—we are also consuming code that compensates for the environment.
At this point, an important fact emerges. Most developers do not deeply examine what assumptions the code they use is built upon, or what problems it was originally intended to solve. If the code works well, produces no errors, and implements the desired functionality, that is usually considered sufficient. However, behind this notion of “it works” lies a multitude of hidden assumptions and conditions. Polyfills and ponyfills are precisely the pieces of code that construct these assumptions. They are not simple utilities, but rather mechanisms designed to conceal the uncertainty of the environment.
Ultimately, we arrive at a fundamental question. Why did JavaScript come to require this kind of code? Why have these concepts, which are relatively less visible in other languages, become so naturally embedded in JavaScript? To answer this, we cannot judge from the present alone. We must revisit the environment in which JavaScript first emerged. This article begins from that point. We need to understand what problems these now-familiar pieces of code were originally created to solve.
Why Was This Code Necessary — JavaScript Began in an Incomplete Environment
Today’s JavaScript environment is relatively stable. Most browsers adhere well to standards, and Node.js provides a consistent runtime under a clear LTS policy. Developers can reasonably expect that a given feature will behave consistently across environments. However, this stability was not present from the beginning. In fact, the early JavaScript environment was quite the opposite. There was almost no guarantee that the same code would behave the same way everywhere.
In the early web, each browser implemented its own version of the JavaScript engine, and standards evolved slowly. A feature available in one browser might not exist at all in another, and even when the same API existed, its behavior could differ subtly. Functions we now take for granted—such as array methods or object utilities—were often unsupported. Developers had to check the environment every time they used a feature, and frequently had to implement the same logic in multiple ways. In such a context, the idea of “trusting the standard” was difficult to sustain.
Faced with this reality, developers had two choices. One was to implement every feature manually. The other was to extract reusable functionality and share it. The latter proved more efficient, and naturally, small units of utility code began to emerge. These pieces of code did more than just provide functionality—they ensured that the same behavior would occur across different environments. In other words, code began to take on a dual role: implementing features and handling environmental differences at the same time.
At this point, a critical shift occurred. Developers stopped trusting the environment and began handling it within their code. It became common to check whether a feature existed and, if not, execute an alternative implementation. As this pattern repeated, a structural approach to absorbing environmental differences began to take shape. And it was on top of this structure that the concept of the polyfill emerged. A polyfill was not just a tool—it was the most direct response to an era where the environment could not be trusted.
The First Response — Polyfill, the Most Direct Way to Modify the Environment
Polyfill represents the most intuitive solution within the JavaScript ecosystem. It is code that implements a missing feature in an environment, making it appear as if that feature exists. The core idea is simple. Instead of changing the code, you change the environment. Developers can continue to use standard APIs, maintain the same code structure, and avoid dealing directly with environmental differences. In the context of its time, this was an extremely powerful advantage.
For example, if a browser does not support Array.prototype.includes, a polyfill directly defines that method so that all code behaves consistently. Developers no longer need to write conditional logic to branch based on the environment, and the same code can run everywhere. This approach significantly improved developer productivity while preserving code readability. In other words, polyfills were not just convenience tools—they were a strategic choice to maintain consistency in code.
However, this approach comes with an important assumption. A polyfill modifies the environment itself, meaning it directly affects the runtime. This goes beyond simply adding functionality—it can alter how the existing environment behaves. Modifying object prototypes or adding properties to global objects can introduce unexpected conflicts. If multiple libraries attempt to polyfill the same feature in different ways, the outcome can become unpredictable.
Despite these risks, polyfills remained a core tool in the JavaScript ecosystem for a long time. The reason is straightforward. In the conditions of that era, it was the most practical solution. When you cannot control the environment, adjusting the environment is often more efficient than rewriting the code. However, this choice left behind a structural limitation. Over time, the drawbacks of modifying the environment became increasingly evident. And eventually, these limitations led to the emergence of a new approach.
The Cost of Convenience — Structural Problems Created by Polyfills
Polyfill was undeniably a powerful solution. By modifying the environment, it preserved code consistency and allowed developers to ignore differences across environments. However, this convenience was never free. Because polyfills solved problems by “hiding” them, the cost began to surface in increasingly complex ways over time. What initially appeared to be a simple supplement gradually evolved into something that undermined the predictability of the environment itself.
One of the most representative issues is global namespace pollution. Polyfills operate by modifying global objects or built-in prototypes. While this is effective for adding missing functionality, it also means altering the existing state of the environment. The problem is that these modifications are not always applied in a single, consistent way. When different libraries polyfill the same feature in different ways, the execution environment can no longer maintain a consistent state. Developers find it difficult to determine the actual state of the environment just by reading the code, which significantly increases the difficulty of debugging.
Another issue is conflicts and priority. Polyfills are based on the assumption of “filling in missing features,” but in reality, they sometimes overwrite or extend features that already exist. When the native implementation and the polyfill behave slightly differently, unexpected bugs can occur. As browsers began to support more standards, situations emerged where native implementations and polyfills coexisted. In such cases, it is not immediately clear which implementation is actually being used. As a result, we end up building systems that depend not on the code itself, but on the state of the environment.
These issues go beyond mere technical concerns. As polyfills accumulate, systems increasingly operate on invisible assumptions. Developers can no longer trust the environment, and understanding code behavior requires direct inspection of the runtime state. This makes the development experience more complex and increases long-term maintenance costs. In the end, polyfills solved one set of problems while simultaneously creating new ones. And this naturally leads to the next question: Is it possible to solve the same problem without modifying the environment?
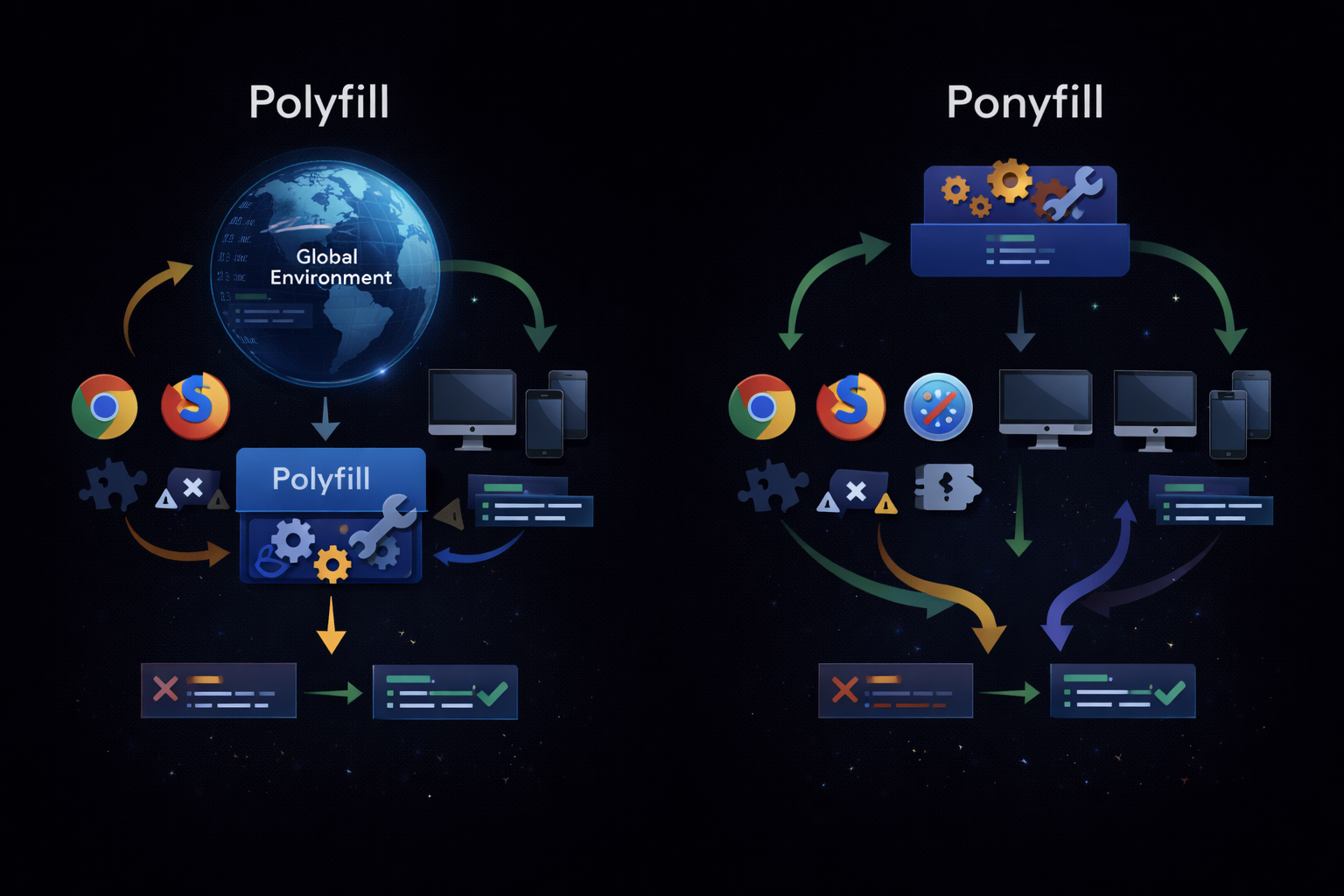
The Second Response — Ponyfill, an Alternative That Avoids Touching the Environment
As the structural limitations of polyfills became apparent, developers began exploring alternative approaches. The result was the emergence of the ponyfill. While ponyfills provide the same functionality as polyfills, they differ fundamentally in their approach. Where polyfills solve problems by modifying the environment, ponyfills choose to explicitly use alternative implementations without altering the environment. In other words, they deliver the same functionality while avoiding direct intervention in the runtime.
The most defining characteristic of this approach is explicitness. Ponyfills are imported as needed, and developers explicitly call them. Because they do not modify global objects or prototypes, the state of the runtime remains predictable. Code behavior is no longer something that “depends on the environment,” but rather something determined by the code itself. This directly addresses the most significant drawback of polyfills.
Additionally, ponyfills significantly reduce the likelihood of conflicts. Even if multiple libraries implement the same functionality, they do not interfere with each other. Each implementation exists independently, and developers can choose which one to use. This reduces system complexity and simplifies debugging. Developers no longer need to trace “who modified the environment,” but can instead understand behavior based solely on the code they are using.
However, ponyfills are not a perfect solution either. Instead of modifying the environment, they solve the problem by increasing the amount of code. The same functionality may exist in multiple forms, and each project selects its own implementation. This leads to code duplication, and the dependency structure remains complex. Developers are no longer simply “using a feature,” but must decide which implementation to adopt.
In the end, ponyfills emerged as an alternative to address the issues of polyfills, but they did not eliminate the root problem. They avoided modifying the environment, but instead worked around it. This was undoubtedly a safer direction, yet it introduced a new kind of complexity. And this complexity raises yet another question: Was the problem we tried to solve really about modifying the environment, or is it rooted in something more fundamental?
A Problem That Seemed Solved — Yet the Structure Remained
The emergence of ponyfills appeared to many developers as a turning point. The idea that the same functionality could be achieved without modifying the environment was seen as a reasonable alternative to avoid the risks of polyfills. In practice, many libraries transitioned to the ponyfill approach, and the principle of “not touching the global scope” began to establish itself as a good design guideline. On the surface, the problem seemed resolved. But a closer look reveals that the situation is not so simple.
The most important fact is that the core issue never disappeared. Both polyfills and ponyfills share the same starting point: the assumption that the environment cannot be trusted. Polyfills attempted to solve this by modifying the environment, while ponyfills approached it by bypassing the environment. However, both approaches ultimately absorb environmental uncertainty into the code. In other words, the method of resolution changed, but the underlying structure remained the same.
The consequences of this are clear. The amount of code does not decrease; it simply grows in different forms. Where polyfills modified the global environment, ponyfills exist as separate modules. Logic for handling environmental differences is still required, only its location and form have changed. As a result, systems continue to include code designed to compensate for the environment, and this becomes part of the dependency structure. We have not removed the problem—we have merely changed how it is expressed.
At this point, we arrive at an important insight. The problem in JavaScript is not simply about how we implement things. More fundamentally, it is about why this kind of code continues to be necessary at all. Whether polyfill or ponyfill, their very existence is based on the assumption of environmental uncertainty. And as long as that assumption persists, similar forms of code will continue to emerge.
Ultimately, we return to the starting point. Understanding the difference between polyfill and ponyfill is important, but even more important is understanding the nature of the problem they were both trying to solve.
Code Without a Name — The Realm of Compatibility Code Beyond Polyfill and Ponyfill
Through the previous discussion, we have examined two major approaches: polyfill and ponyfill. However, if we look a little deeper into the JavaScript ecosystem, we discover that there exists a much broader domain that cannot be explained by these two concepts alone. It consists of code that is neither polyfill nor ponyfill, yet is used far more extensively. These are not written to implement specific standard features, but rather to absorb the uncertainty of the environment itself.
The defining characteristic of this domain is clear: it has no name. It is not a formally defined concept like polyfill, nor is it philosophically distinguished like ponyfill. Instead, this code is scattered across many forms. In some cases, it appears as type-checking logic designed to handle cross-realm issues. In others, it exists as wrappers that defend against the possibility of a polluted global object. It may also take the form of conditional branches that absorb subtle behavioral differences between browsers. Despite their diversity, all of these share the same purpose: to distrust the environment and handle every possibility within the code itself.
One of the most notable characteristics of this code is that it executes only when necessary. In most cases, it is never actually executed. It is designed to run only when specific conditions are met, and in normal environments, it plays no active role. Yet, it is always included. The reason is simple: to prepare for “just in case” scenarios. At this point, we uncover an important structure. A significant portion of JavaScript code does not exist to implement actual functionality, but rather to guard against situations that may never occur.

This compatibility code seeps into systems far more subtly than polyfills or ponyfills. Developers use it without explicitly recognizing it, and in most cases, they are not even aware of its existence. Yet these pieces of code increase system complexity, expand execution paths, and contribute significantly to maintenance costs. Ultimately, we arrive at a clear conclusion. The complexity of JavaScript is not merely a problem of polyfills or ponyfills, but rather the result of countless unnamed compatibility codes accumulating over time.
The Difference Between Three Structures — “Fill vs Avoid vs Defend”
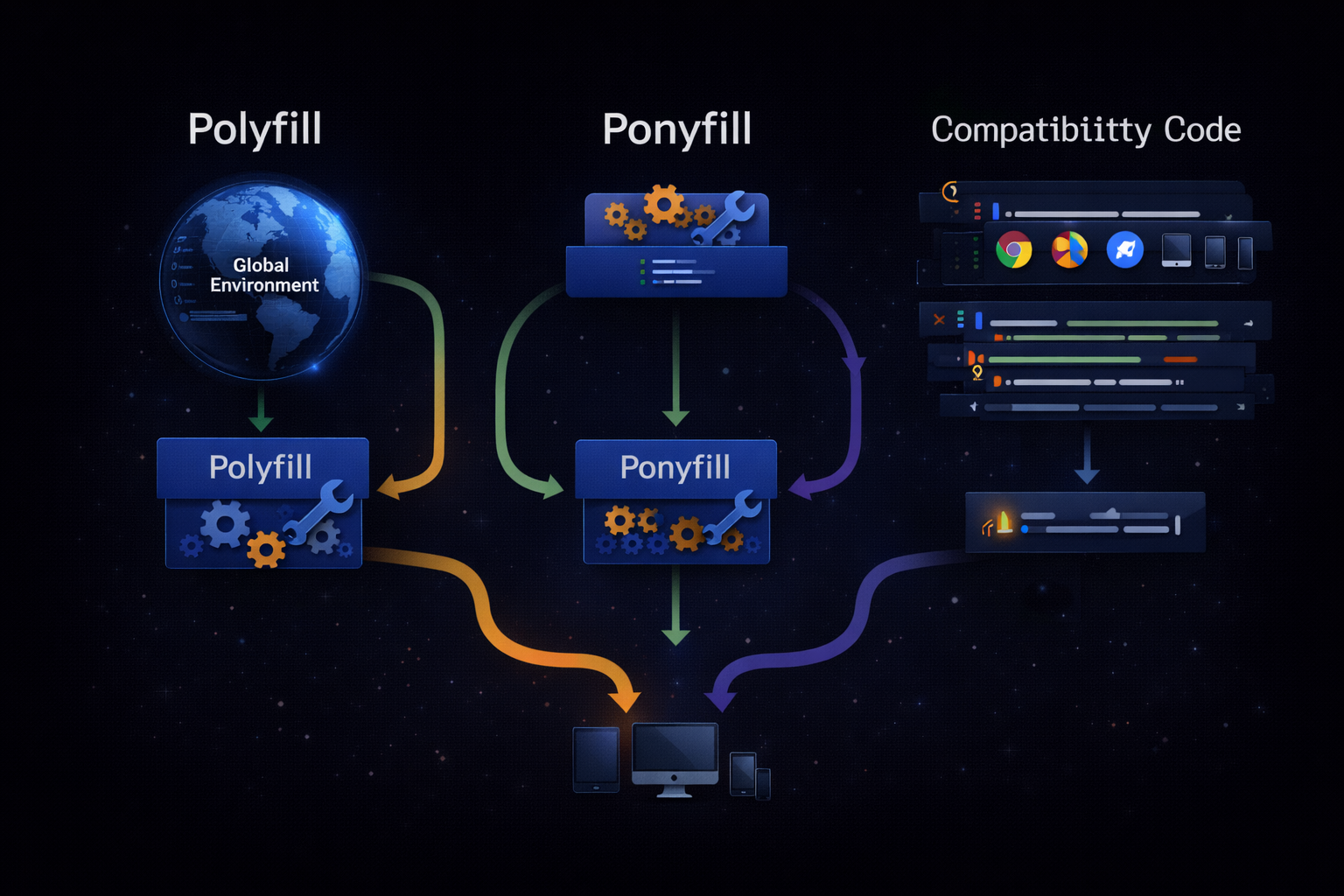
We have now identified three distinct structural approaches: polyfill, ponyfill, and compatibility code. Each solves the problem in a different way, but all share the same starting point: the assumption that the environment cannot be trusted. However, the way this assumption is handled differs significantly, and this difference directly affects both code structure and system complexity. At this point, it becomes necessary to organize these three approaches more structurally.
Polyfill is the most direct approach. It fills in missing functionality within the environment. This modifies the environment itself, meaning that code is not simply layered on top of the environment—the environment is reshaped to fit the code. Ponyfill takes a different direction. It does not modify the environment, but instead provides the same functionality through a separate implementation. This bypasses the environment, allowing code to operate independently of it. Compatibility code, however, exists on an entirely different dimension. It neither modifies nor completely bypasses the environment. Instead, it absorbs all possible variations of the environment directly within the code, handling its variability internally.
These three approaches represent more than implementation differences—they reflect fundamentally different perspectives on the problem. Polyfill operates under the assumption that “the environment can be changed.” Ponyfill follows the principle that “the environment should not be changed.” Compatibility code, on the other hand, accepts that “the environment can change and cannot be predicted.” This distinction is critical, because these approaches are not mutually exclusive—they coexist and collectively shape the system.
In real-world applications, all three approaches are used in combination. Some features are provided through polyfills, others through ponyfills, and on top of them, layers of compatibility code are added. This structure is not a simple layering, but rather a tightly intertwined system. As a result, to use a single feature, developers end up relying on code that combines three different philosophies. What makes this more complex is that developers are often unaware of this structure. The system grows increasingly complex, yet that complexity remains largely invisible.
At this point, we reach an important question. Even though we are solving the problem in so many different ways, why does the system continue to become more complex? Why do these pieces of code not decrease over time, but instead continue to accumulate? This question naturally leads to the next section.
The Bigger Problem — Why Does This Code Never Disappear
Through the discussion so far, we have examined how polyfills, ponyfills, and compatibility code emerged and how they solve problems. However, all of this leads to a more fundamental question: why does this code never disappear? Even as environments improve, standards stabilize, and most browsers support the same features, why do we continue to rely on this code?
The answer lies less in technical issues and more in structural ones. Adding code is easy. When a new feature is needed, we can simply install a package or write a few lines of code. But removing code is an entirely different matter. To prove that a piece of code is no longer necessary, we must verify that its absence will not cause issues in any environment. This goes beyond simple testing—it requires complete trust in the environment. And in most cases, that level of trust is unattainable.
The nature of the open-source ecosystem also plays a significant role. Many packages are maintained by individuals or small teams, and stability is their top priority. There is little incentive to remove code that is already working well, especially if doing so introduces risk. Polyfills and ponyfills, in particular, often fall into the category of code that “does no harm if present, and is not strictly required.” As a result, their removal is consistently deprioritized, and they remain in the codebase. While this decision is rational at the individual level, it leads to the accumulation of technical debt across the ecosystem.
Furthermore, the structure of dependencies reinforces this issue. In systems where one package depends on another, which in turn depends on yet another, predicting the impact of removing a single piece of code becomes extremely difficult. Developers must consider not only their own code but also a vast network of indirect dependencies. In such situations, the safest choice is to change nothing. This leads to the repeated adoption of the strategy: “if it isn’t broken, don’t touch it.” And this strategy accelerates the permanence of code.

At this point, we arrive at a clear conclusion. Polyfills, ponyfills, and compatibility code do not persist because they are necessary, but because they cannot be removed. This structure is not simply the result of technical choices, but of inertia created by the entire ecosystem. And so we return to the original question. Are these pieces of code still truly necessary today, or do they remain simply because they were never removed?
Conclusion — We Are Not Handling Features, but the Uncertainty of the Environment
If we follow the flow so far, a consistent pattern emerges. Polyfills attempted to solve the problem by modifying the environment, ponyfills approached it by bypassing the environment, and compatibility code tried to absorb the many possibilities of the environment within the code itself. These three approaches are built on different philosophies, yet they all share the same starting point. That starting point is the assumption that the JavaScript execution environment cannot be trusted. And this assumption has acted not merely as a technical fact, but as a core element shaping the structure of the entire ecosystem.
At this point, what matters is how naturally we have come to accept this structure. Most developers do not recognize polyfills or ponyfills as anything special. They are simply seen as “code that provides necessary functionality.” However, if we look a little deeper, we begin to see that these pieces of code are not merely implementations of functionality, but rather layers designed to conceal the uncertainty of the environment. We believe we are writing code to implement features, but in reality, we are also performing the task of ensuring that those features behave consistently across all environments.
This structure becomes stronger over time. Every time a new feature is introduced, we must consider how it will behave across different environments. Because we cannot rule out the possibility of issues arising in certain environments, we add yet another layer of defensive code. This process repeats, and the codebase gradually accumulates more and more environment-handling code. In the end, the system evolves from a simple collection of features into a complex structure filled with countless assumptions and exceptions. And this structure creates far greater complexity than the sheer length of the code itself.

At this point, we need to shift the question. Whether polyfill or ponyfill is better is no longer the important issue. The more important question is why we still depend on this kind of code at all. Even though environments have become increasingly standardized and most runtimes now support the same features, we continue to write code based on assumptions from the past. This is not simply a matter of habit, but the result of structural inertia accumulated over a long period of time.
Ultimately, the core message of this article is simple. Polyfills and ponyfills are not merely names of specific techniques, but traces of an era in which the environment could not be trusted. And those traces still remain within our code today. We think we are writing code to implement functionality, but in reality, we are adding more code to handle the uncertainty of the environment. The moment we recognize this structure, the meaning of the code we write begins to look slightly different.
The final question that remains is this. Is our current environment still truly that uncertain? If not, why do we continue to maintain that assumption? And the answer to this question will not simply determine a technical choice, but will shape the direction of how we write code going forward.