
If We Are in the Age of AI, Why Has Software Not Increased?
The fact that AI is changing developer productivity is no longer a subject of debate. Code completion has already become a baseline feature, and the experience of generating working code from natural language requirements is no longer unfamiliar. Some developers claim they can work twice as fast, ten times as fast, or even faster than that. In many cases, simple web applications or automation scripts can now be completed within a matter of hours. If we look only at these changes, it seems as though we have already entered an era where the paradigm of software production has been fundamentally transformed.
Naturally, this leads to a straightforward question. If productivity has increased to this extent, where are the results? If productivity has doubled, then by simple logic, the world should contain twice as much software. We should be seeing a clear increase in new libraries, new services, and new tools. However, when we look at reality, such changes are not easily observable. The major libraries and services we use are still largely the same familiar names, and there is no strong sense that the entire ecosystem has expanded explosively.
At this point, an interesting tension emerges. On one hand, developers clearly report that their development experience has changed. On the other hand, the results of that change do not appear visibly in the broader ecosystem. Is one side wrong? Or are we simply looking for the results in the wrong place? This article begins with that question. And that question goes beyond “Has AI increased productivity?” toward a more fundamental issue: What do we actually define as ‘software production’?
What the PyPI Data Shows — The AI Effect Is Not Visible
The most intuitive way to approach this question is to look at data. If software has truly increased, then it must be recorded somewhere. One commonly referenced metric is PyPI, the central repository of the Python ecosystem. PyPI continuously accumulates data on publicly released packages and their updates, making it a suitable target for observing long-term trends. For this reason, the analysis published by Answer.AI (https://www.answer.ai/posts/2026-03-12-so-where-are-all-the-ai-apps.html) serves as an important starting point for understanding this issue.
The first thing this analysis examines is the growth trend of the total number of packages. The result is not what we might expect. Even after the emergence of generative AI tools such as ChatGPT, there is no clear inflection point in the growth curve of PyPI packages. The curve continues to increase steadily, without any sudden acceleration tied to a specific moment. In other words, there is no visible evidence of an explosive increase in software production following the rise of AI.
What if we shift our focus from the number of packages to their “activity”? The analysis goes further by examining the update frequency of widely used packages. Here, we do observe a slight change. More recent packages tend to have a higher number of updates within their first year. However, this trend does not begin with the advent of AI; it can be traced back several years earlier. It can just as plausibly be explained by factors such as the growing adoption of continuous integration tools.
The truly interesting point lies elsewhere. While there is no significant change across all packages, there is a noticeable increase in update frequency specifically for packages related to AI. In particular, popular AI packages show cases where the number of releases per year has more than doubled. This result seems to support the narrative that “AI has increased productivity,” but at the same time, it raises a new question. Why is this effect concentrated in a specific domain rather than appearing across the entire ecosystem?
At this stage, it becomes difficult to draw a simple conclusion. The data clearly shows that something has changed, but not in the way we initially expected. Instead of a general increase in software production, we see intensified activity within a narrow domain. This leads us to a deeper question. Does the data we are looking at truly represent all software being produced?
Why Intuition and Data Collide
At this point, the situation becomes even more interesting. On one side, developers claim they are writing code faster than ever before. On the other side, the overall volume of software production appears largely unchanged. It is tempting to assume that one of these claims must be wrong, but both are supported by convincing evidence. Anyone who has used AI tools can easily recognize the improvement in productivity. At the same time, it is also true that the visible ecosystem has not doubled in size.
To understand this apparent contradiction, we need to separate what exactly is being measured. The productivity that developers experience is an efficiency at the level of individual tasks. It includes factors such as coding speed, debugging time, and the automation of repetitive work. In contrast, metrics like PyPI measure the number of publicly released packages and their maintenance activity. These two are related, but they are not the same. In other words, changes in the production process do not necessarily appear in the same way within the distribution of outcomes.
Another important difference lies in the notion of completeness. What developers quickly produce with AI is often at the level of a prototype. This includes scripts for solving specific problems, tools for improving personal productivity, or experimental code created for short-term validation. These outputs are certainly useful, but they differ in nature from packages that are maintained over time and reused by others. As a result, even if productivity increases, the outcomes may not be aggregated in the same form.
At this point, a critical insight emerges. We have been treating “software production” as a single unified concept, but in reality, it exists across multiple layers. There is software that is publicly released and maintained, and there is software that is privately created and eventually disappears. These layers are connected, but they do not behave in the same way. And AI does not affect them uniformly. Instead, its impact appears concentrated in specific parts of this structure.
Therefore, the conflict we are observing is not simply a mismatch between data and perception, but a structural phenomenon caused by a mismatch in what is being measured. Once we understand this, the direction of the problem changes. Instead of asking “Has AI increased productivity?”, we must ask “Where is that productivity actually being reflected?” And this question naturally leads us to the next step. What lies in the areas that metrics like PyPI fail to capture, and what kinds of changes are actually occurring there?
The Limits of Measurement — What PyPI Fails to Capture
What has become clear from the previous discussion is simple. The PyPI data is not wrong, but it does not explain the whole picture. The question now becomes more precise. What exactly is PyPI observing, and at the same time, what is it missing? Without answering this, we will continue to arrive at incorrect conclusions. Because if the scope of what is being measured is limited, then the conclusions drawn from it must also be limited.
PyPI is fundamentally an ecosystem centered around “published packages.” Simply writing code is not enough to be included. The code must be structured as a package, organized into a distributable form, and equipped with a level of stability and documentation that allows others to use it. This process is entirely different from writing code itself. In other words, being published on PyPI is not just about production, but about being integrated into an ecosystem.

The problem is that AI does not primarily operate in this part of the process. AI dramatically improves the speed of writing code, but it has a much more limited impact on the process of shaping code into something “publishable.” Many scripts and tools created quickly by individuals never reach this stage. They often fulfill their purpose once a problem is solved and are rarely extended or maintained afterward. These pieces of code clearly exist, yet they are completely invisible in metrics like PyPI.
At this point, we arrive at an important structural understanding. Software does not exist within a single layer. There is a layer of code that is published and maintained, and beneath it, there is a layer of code that is created for personal use and eventually disappears. PyPI captures only a portion of the upper layer. Any attempt to explain the whole using only this data will inevitably lead to distortion.
Ultimately, the issue we are facing is not a lack of data, but rather the narrow scope of the data we rely on. Once we accept this, the earlier conclusion that “there is no visible AI effect” takes on a completely different meaning. It is not evidence that nothing has changed, but rather a signal that the change is occurring in a different layer. Naturally, this shifts our focus. What exactly is happening in the layer that PyPI fails to capture?
The Invisible Growth — The Explosion of Personal Software
When we begin to examine the layer that PyPI cannot capture, an entirely different landscape emerges. The most direct impact of AI tools is not visible in large-scale open-source projects, but in code production at the individual level. Tasks that were previously too tedious to justify—such as automation scripts or small utilities—are now easily implemented. Data processing, repetitive workflows, and simple web interfaces can now be created at a significantly lower cost. This change is not immediately visible, but it is occurring on a wide scale.
The nature of this code is distinct. Most of it is created to solve a specific problem, and once that problem is resolved, it is rarely extended further. There is no need to distribute it to others, nor to generalize it for reuse. As a result, it naturally remains outside of public repositories and package registries. It stays in private GitHub repositories, or sometimes exists only within a local environment before disappearing. Yet this code is undeniably “produced software,” and it is a direct outcome of the productivity gains enabled by AI.
What matters here is that the mode of software production itself is changing. In the past, creating software often implied making something distributable. Now, that assumption no longer holds. Code that solves a problem for a single individual is already valuable enough. AI is dramatically expanding this space. In other words, we are no longer only producing software for everyone—we are now mass-producing software for ourselves.
Because this shift is not externally visible, it leads to misunderstanding. From the outside, the software ecosystem appears largely unchanged. But internally, vast amounts of code are being created, used, and discarded. This entire process is neither recorded nor aggregated, and therefore cannot be observed through traditional metrics. This is where the answer to our original question begins to take shape. The software exists, but it exists in places we cannot see.
At this point, the problem becomes more concrete. Software has increased, but why does it not translate into “products”? Why do so many pieces of code fail to become part of the ecosystem? This question naturally leads to the next step.
The Real Bottleneck — Code Is Easy, but Products Are Not
What AI has changed is undeniable. Writing code is no longer a significant barrier. Requirements can be described in natural language, and working implementations are generated as a starting point. Repetitive tasks are automated, and developers no longer begin from a blank screen. This shift creates a dramatic difference in speed, especially in the early stages of development. The time required to move from an idea to a working prototype has been drastically reduced.
However, this is where a critical misunderstanding arises. Many people equate the ability to produce code with the ability to build a product. In reality, these are fundamentally different problems. A product is not just about functionality—it must deliver a usable and sustainable experience. This involves user experience design, error handling, performance optimization, deployment infrastructure, and ongoing maintenance. While AI can assist in some of these areas, it does not eliminate their complexity. The final structure and decisions still depend heavily on human judgment.
As a result, the structure of development now looks very different. The distance from idea to prototype has shrunk, but the distance from prototype to product remains largely unchanged. This gap is the true bottleneck. A vast amount of code is generated, but only a small fraction evolves into actual products. The rest fulfills a specific purpose and then disappears without further development. This phenomenon is not purely technical—it is also shaped by time, cost, and motivation. Maintaining a product requires continuous investment and responsibility.
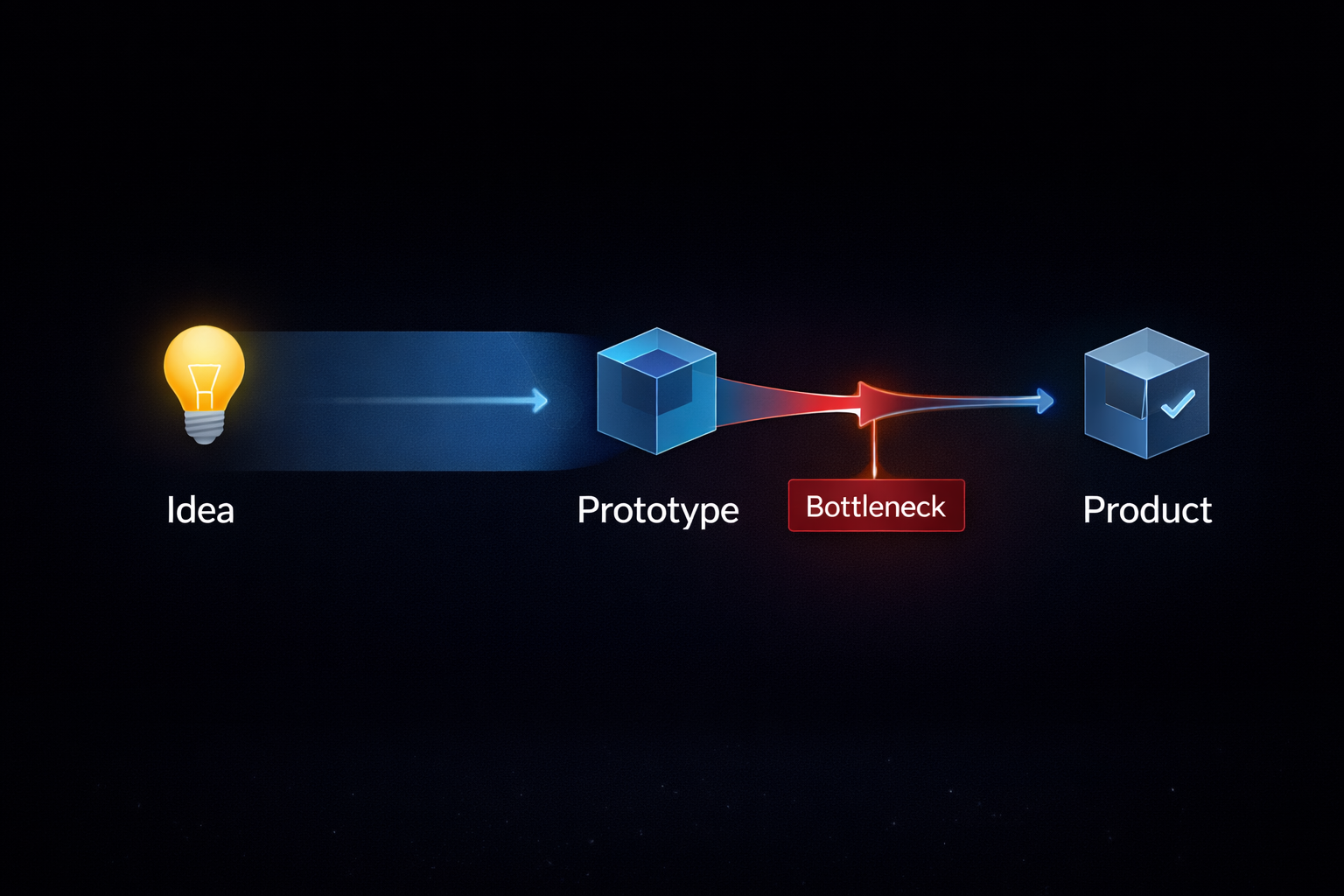
Understanding this structure explains why metrics like PyPI show only limited change. What appears on PyPI is typically product-level code, while what AI has massively increased is prototype-level code. These two layers are connected, but they do not grow at the same rate. This suggests that we have been asking the wrong question from the beginning.
The real question is no longer “Why hasn’t software increased?” Instead, it becomes “Why does so much software fail to become products?”. And to answer that, we must once again reconsider the metrics we rely on to observe these changes.
Why App Store Data Is Not the Answer Either
If we follow the flow of the discussion so far, a natural counterargument emerges. If PyPI is not sufficient, then perhaps we should look at something closer to real user-facing results. In other words, wouldn’t the number of apps released on platforms like the App Store or Google Play provide a more accurate measure of productivity in the AI era? At first glance, this approach seems far more reasonable, because apps represent the final outputs that actually reach users.
However, this intuition overlooks a critical premise. Being published on an app store does not simply mean that code has been written. It means that the software has reached the final stage of productization, which requires a certain level of completeness. A user interface and user experience must be properly designed, platform policies must be satisfied, and the deployment and update processes must be maintainable. In other words, the app store is not a space that reflects “code production,” but rather one that only shows results filtered by product-level completeness.
This structure does not align with the domain where AI has the strongest impact. As discussed earlier, AI significantly improves code writing and early implementation stages, but its influence is relatively limited when it comes to full product completion. Therefore, even if code production increases, it is entirely natural that this does not directly translate into an increase in app releases. In fact, if a large portion of generated code never reaches the product stage, then app store metrics may show little to no change at all.
Another important factor is market saturation. App stores already exist in an environment where millions of applications are available. Adding a new app does not guarantee that it will reach users. In this situation, developers do not release apps simply because they can build them. They must consider discoverability, maintenance costs, and the difficulty of acquiring users. As a result, even though AI has lowered the barrier for writing code, publishing an app remains a high-cost decision.

At this point, the conclusion becomes clear. App store data does not show “how much code AI has helped produce,” but rather “how much of that code has been completed into products.” Therefore, we are still facing the same problem. If we want to measure the increase in code productivity, we must capture changes at an earlier stage—before productization. This leads us to reconsider the question once again.
The Real Shape of the AI Effect — Not Expansion, but Concentration
Let us return to the starting point once more. The most noticeable change observed in PyPI data was not an overall increase, but a concentrated change within a specific domain. In particular, update frequency increased sharply only for AI-related packages. This result cannot be fully explained by simply saying “AI has improved productivity,” because the effect is not distributed evenly across the ecosystem.
To understand this phenomenon, we must abandon the idea that productivity is a force that increases uniformly. AI does not impact all developers equally. Instead, it operates much more strongly in certain problem domains, especially those that directly involve AI itself. Developers who build systems around AI models are also the ones most capable of leveraging AI tools effectively. For them, the change is not just a marginal productivity gain, but a shift in how they work altogether.
However, even this explanation is not sufficient. If this were purely a matter of “developers who use AI well,” then we would expect to see similar increases across all AI-related packages. But the actual data shows that the increase is concentrated in popular AI packages. At this point, we must consider factors beyond technology alone. These include capital, attention, and market demand.
AI is currently one of the most heavily funded and widely discussed areas in technology. As a result, certain projects receive more resources, more contributors, and more time investment. This leads to faster iteration cycles and more frequent updates. In this sense, the observed increase in update frequency is less about pure productivity gains and more about the effects of concentrated resources. It is not that AI has made developers superhuman, but that it has drawn more developers into a specific area.

Ultimately, what we are observing is not a broad expansion, but a localized surge. AI has not uniformly increased software production. Instead, it has concentrated energy into particular domains, creating visible changes only within those areas. While this differs from the intuitive expectation, it provides a more accurate explanation of the current reality.
A New Perspective — What Have We Been Looking at Wrong?
When we bring all of these discussions together, it becomes clear that the issue is not merely a misinterpretation of data, but a flaw in how the question itself was framed. We asked whether AI has increased software production, and we attempted to answer this by examining metrics such as PyPI and app store data. However, this question implicitly assumed that software must exist in a published, distributed, and ecosystem-integrated form.
AI challenges this assumption. Software no longer needs to be publicly released to be valuable. Code created to solve a specific problem can already serve its purpose without ever being shared. Tools for personal productivity, scripts that support internal systems, and code written for one-time analysis are all forms of software, yet they are rarely captured by traditional metrics. In other words, we have been evaluating the entire landscape based only on “visible software.”
From this perspective, the confusion we observed earlier becomes inevitable. We attempted to measure a change in productivity, but we looked in the wrong place. AI has not simply expanded the existing ecosystem; it has created a new layer. This layer consists of code that is rapidly generated, quickly consumed, and often disappears without leaving a trace. And this layer is not properly captured by any of the metrics we have traditionally relied on.
At this point, the question must be reframed. Instead of asking “How much software has increased?”, we should ask “What kinds of software are being created, and where do they exist?”. This shift moves the focus away from purely quantitative growth and toward a deeper understanding of how software itself is evolving. Only by making this transition can we begin to properly understand the changes brought about by the AI era.
Practical Limitations — What AI Cannot Change
Through the discussion so far, we have confirmed that AI is significantly transforming certain parts of software production. At the same time, it has become equally clear that this transformation is not one that restructures the entire system, but rather one that strongly accelerates specific segments. In particular, there has been an overwhelming improvement in the code-writing stage, while the later stages of development still largely follow existing structures. At this point, we are forced to confront an important reality. AI is not a tool that solves every problem in development, but a tool that solves certain problems extremely well.
The most representative limitation appears in the process of productization. For software to reach actual users, it requires far more than just functioning code. Users do not consume functionality—they consume experiences, and those experiences are not completed by code alone. They require interface design, optimization of user flows, proper handling of errors, and continuous updates and operations. While AI can assist in some of these areas, it does not fundamentally eliminate their complexity. The final decisions and structural design still remain the responsibility of humans. Therefore, even though writing code has become easier, building a product has not become equally easy.
Another limitation lies in the issues of responsibility and sustainability. The many tools created by individuals using AI are often highly useful in the moment, but they are not maintained over time. Without continuous management and improvement, such code quickly becomes obsolete. In contrast, packages published on PyPI or products released on app stores assume a certain level of ongoing maintenance. This difference is not merely technical—it stems from differences in responsibility and cost structures. AI can generate code rapidly, but it does not create the structures that take responsibility for that code.
In addition, challenges related to organizations and collaboration still remain. While productivity gains are clearly visible at the individual level, they do not simply scale at the team or organizational level. Maintaining code quality, designing consistent architectures, and coordinating collaboration among multiple developers still require significant effort. There is also the unresolved issue of how to validate and integrate AI-generated code within a broader system. In the end, AI increases the speed of individuals, but it does not reduce the complexity of the system as a whole.
All of these limitations converge toward a single conclusion. AI has accelerated parts of development, but the process of turning software into a “finished state” still remains largely human-centered. Therefore, there is no need to overestimate AI, nor to underestimate it. What matters is understanding exactly where its influence reaches, and where it stops. With that understanding, we can now return to the broader discussion and bring the argument to its conclusion.
Conclusion — AI Did Not Increase Software
Let us return to the beginning. AI is said to have significantly improved developer productivity, and many developers genuinely feel that change. At the same time, we have observed that expected changes do not appear in metrics such as PyPI. These two facts initially seemed contradictory, but through our discussion, it has become clear that they are not in conflict. Instead, they describe phenomena occurring at different layers.
AI has indeed enabled the creation of more software. However, that software does not appear in the forms we traditionally measure. It is not packaged for distribution, not submitted to app stores, and not integrated into public ecosystems. Instead, it is generated and consumed within personal workflows, internal systems, and one-time problem-solving processes. In this sense, AI has not increased the “quantity” of software so much as it has changed the “way” software exists.
This shift forces us to reconsider how we define and observe software itself. In the past, publicly shared and reusable code formed the core of the ecosystem. Now, personalized and immediately generated code has taken on a significant role. These two domains do not compete; they coexist with different purposes. And AI is dramatically expanding the latter. Without recognizing this, we remain trapped in the question of “why no change is visible.”
Ultimately, the core message of this article is straightforward. AI did not increase software. Instead, it dramatically increased software that never becomes visible to the world. This statement may seem counterintuitive, but it provides the most accurate explanation of the observations we have examined. It also points toward a direction for the future. We can no longer rely solely on visible outputs to understand change. Instead, we must learn to recognize and interpret what is happening in the invisible layers.
At this point, the original question returns in a new form. In the age of AI, what should we build, and where should it exist? The answer is not yet fully defined, but one thing is clear. Software is still increasing. It is simply that our way of seeing it has not yet caught up.