
A Small Symbol We Use Every Day
Anyone who has spent even a little time using a terminal eventually becomes familiar with a certain symbol: the pipe, |. At first, it may seem like nothing more than a way to chain commands together, but over time it becomes something you use almost unconsciously. For example, when sorting a list of files, you might use a command like ls | sort, and when searching for a specific program among running processes, you might use ps aux | grep nginx. In this way, the pipe naturally appears in everyday shell usage. However, most people think of it as just a convenience feature and rarely consider the design and historical context behind it. In reality, this single small symbol provides an important clue to understanding how the Unix system was built.
Although it looks like simple syntax on the surface, the | symbol is closer to an invention that fundamentally changed how we think about programs. In most operating systems, programs are built as self-contained tools. A single program reads input, processes data, and produces output on its own. But Unix introduced a different approach. A program does not need to do everything—it only needs to do one thing well. And by connecting multiple programs, larger tasks can be accomplished. The pipe is what made that connection possible.
Thanks to this small symbol, Unix became more than just an operating system that executes commands—it became a system for solving problems by composing programs. Data flows from one program to another, and each program performs only its role within that flow. This structure later became the foundation for design patterns seen in data processing systems, log pipelines, and even stream processing platforms. For this reason, the pipe has become an important concept in software design, going far beyond simple shell syntax. In this article, we will take a deeper look at how the pipe emerged and why it came to play such a crucial role. This story naturally takes us back to Bell Labs in the 1970s.
The Environment of Unix and Bell Labs in the 1970s
The computing environment we use today is mostly centered around individuals. We have laptops or personal desktops, and each person operates their own system. But the computing environment of the early 1970s, when Unix was created, was completely different. At that time, computers were extremely expensive, so they were often shared in research labs or universities. In institutions like Bell Labs, it was common to use a time-sharing system where multiple users accessed a single computer simultaneously. In such an environment, operating systems needed to be designed as simply and efficiently as possible.
Unix was born in this context. Ken Thompson and Dennis Ritchie were not trying to build a massive operating system from the beginning. Instead, what they wanted was a system that was small, simple, and useful. Rather than putting complex functionality into a single program, they believed it was far more flexible to create small tools and combine them to perform larger tasks. As a result, early Unix programs were mostly designed to perform very simple functions. Programs like ls, which lists files, grep, which searches text, cat, which displays file contents, and sort, which organizes data, are typical examples.
These programs all shared a common characteristic: each performed a specific task. ls outputs file listings, grep searches for strings, and sort arranges data. Instead of one program handling everything, each program was responsible for a single job. This approach was highly effective in keeping programs simple. However, it also introduced an inconvenience. When tasks required multiple programs, an extra step was needed to store intermediate results.
For example, if you wanted to sort a list of files, you would first run the ls command and save the result to a file, then pass that file as input to the sort program. As tasks became more complex, this approach became increasingly cumbersome. Each program worked well on its own, but they were not directly connected to one another. This problem naturally led to an important question. If these small programs are already well designed, couldn’t they be connected directly and used together? This very question led to the birth of the Unix pipe.
The Idea of Connecting Programs
The idea of connecting programs feels very natural today. But at the time, it was not an obvious concept. Most programs were designed as independent tools that take input, process it, and produce output. It was not common for one program to directly use the output of another. As a result, when multiple programs were used together, intermediate results usually had to be stored in files. While this approach worked functionally, it became increasingly inefficient as workflows grew longer.
For example, suppose you wanted to sort a list of files. You would first run the ls command to generate the file list and save the result to a file. Then you would run the sort command and use that file as input. The task itself was simple, but the process became unnecessarily long. In workflows involving multiple steps, these intermediate files accumulated, making the overall process more complex. It was while observing this problem that Ken Thompson came up with an idea.
His idea was remarkably simple. Instead of saving a program’s output to a file, what if it could be passed directly as input to another program? This idea fundamentally changed how programs were used. Rather than viewing programs as independent tools, it introduced a perspective in which programs act as components cooperating within a flow of data. One program generates data, another processes it, and yet another organizes the results. With this approach, intermediate files are no longer necessary, and workflows become much simpler.
This concept was soon implemented as the Unix pipe. The output of program A was directly connected to the input of program B. In the shell, this was expressed with a single symbol: |. The user simply writes command1 | command2, and the two programs are connected. Behind the scenes, however, the operating system performs a more complex task—it creates a data channel between the two programs and connects their input and output to that channel. Beneath this simple syntax lies a design at the operating system level.
This idea became a core part of the Unix philosophy. A program does not need to do everything on its own. Instead, by connecting small programs with specific functions, a much more powerful system can be built. At this point, Unix evolved beyond a simple operating system into an environment where problems are solved by composing tools. In the next section, we will look at how this idea was actually implemented and how the pipe became an integral part of the Unix system.
The Birth of the Unix Pipe
The question of whether programs could be connected to one another eventually took shape as a concrete feature. Within Bell Labs, the idea of linking programs together was already being discussed. In particular, Doug McIlroy, a researcher at the lab, had long advocated for an environment where small programs could be combined to perform larger tasks. He believed that programs should be able to exchange data with each other, and that such a connection model would become the core of the Unix tool ecosystem. Ken Thompson took this idea and implemented it as an actual system feature—this became the beginning of the Unix pipe.
Ken Thompson did not leave this idea as a mere concept. He decided to build a structure at the operating system level that could directly connect a program’s output to another program’s input. At the time, Unix was still a very small system, so adding new functionality was not as complex as it would be today. Rather, it was an environment where a developer who understood the entire system could directly implement core features. According to a well-known story, Ken Thompson came up with the idea one day and completed an initial implementation of the pipe in just a few hours at the lab the next day. While the exact accuracy of this anecdote is uncertain, it clearly illustrates how fast and experimental the Unix development culture was at the time.
The core concept of the pipe was remarkably simple. Instead of writing a program’s output to a file, the output would be directly connected so that another program could read it immediately. In other words, the output of program A becomes the input of program B. In the Unix shell, this connection is represented by a single symbol: |. The user simply enters a command like command1 | command2, and the shell internally executes both programs and creates a data channel between them. The key point is that the two programs do not need to call or even know about each other. One program simply produces data, and the other simply consumes it—the operating system handles the connection in between.
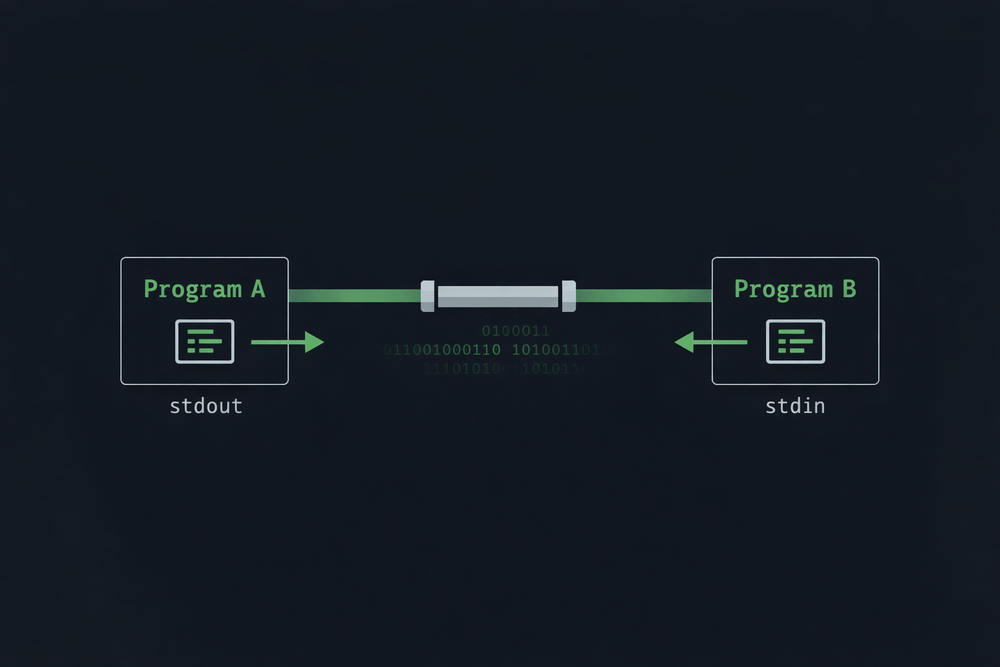
Understanding this structure reveals how distinctive the design of Unix pipes truly is. Programs are not tightly coupled to one another. Instead, they are loosely connected through a shared interface: data. Thanks to this design, new combinations can be created without modifying existing programs. Although the pipe may appear to be a simple feature, it is in fact a structure that allows programs to cooperate within a single flow of data. And this is one of the key reasons why the Unix system has been able to endure for decades.
A Powerful System Built by Small Programs
With the introduction of pipes, the way Unix programs were designed began to change noticeably. Previously, programs were independent tools, and when multiple programs were used together, users had to manually manage intermediate data. But after pipes were introduced, programs could be naturally connected. This change meant more than just the addition of a convenient feature—it fundamentally altered how programs were built. Programs no longer needed to implement every function themselves. Instead, it became sufficient to do one thing well.
Consider the task of analyzing web server logs. Searching for a specific error code in a log file, sorting the results, and calculating frequencies might seem like a complex program. However, in Unix, this can be handled by breaking the task into several small programs. cat reads the file, grep searches for a specific string, sort organizes the data, and uniq counts duplicate entries. Each program performs only a simple role. Yet when these programs are connected with pipes, they become a powerful data processing tool.
This approach is one of the clearest examples of the Unix philosophy. Programs should be designed to do one thing well and to work together with others. One of the most frequently quoted lines describing this philosophy emphasizes exactly this principle: “Write programs that do one thing well. Write programs to work together.” This statement, articulated by Doug McIlroy of Bell Labs, became one of the most widely cited expressions of Unix philosophy. It was not merely a slogan, but a design principle that runs through the entire Unix system.
The pipe was the tool that made this philosophy practical. Programs do not need to know about each other—they simply cooperate through the flow of data. As a result, new programs can be introduced and seamlessly connected with existing ones. This structure made the program ecosystem flexible and gave users the freedom to create their own workflows. Ultimately, the pipe evolved beyond a simple shell feature into something that turned Unix into a composable collection of tools.
How Does a Pipe Work Internally?
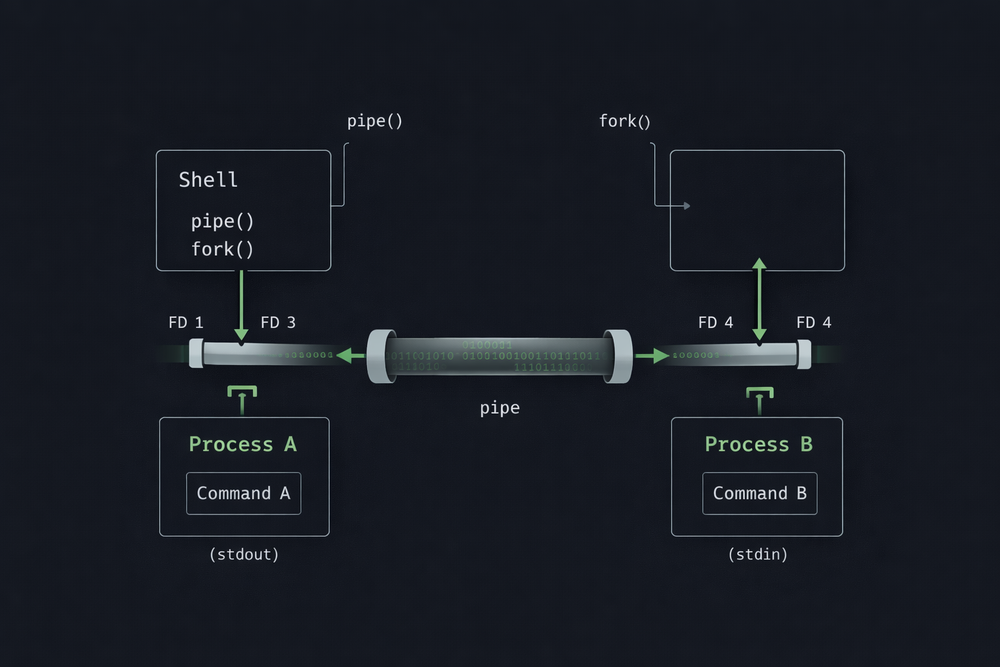
When you enter a command like ls | sort in the shell, what you see is just simple syntax. However, when this command is executed, quite a number of operations take place inside the operating system. The shell does not simply run two programs in sequence—it must create a data channel between two processes and connect their input and output to that channel. This process is built on top of the Unix process model and file descriptor structure. To understand pipes, you ultimately need to understand the Unix I/O model.
The shell first uses the pipe() system call to create a new pipe. This call returns two file descriptors: one for writing data and one for reading data. These two descriptors are connected through an internal buffer in the operating system, allowing one process to write data while another process reads it. Once the pipe is created, the shell uses the fork() system call to create new processes. One of these processes executes the ls program, while the other executes the sort program.
However, simply launching two processes is not enough to complete the pipe. Each program’s standard input and output must be connected to the pipe. The system call used for this is dup2(). The shell connects the stdout of the ls process to the writing end of the pipe, and connects the stdin of the sort process to the reading end of the pipe. Once this setup is complete, the data produced by ls is automatically passed through the pipe, and sort reads that data as its input.
Understanding this process makes it clear that a pipe is not just shell syntax—it is a feature built on top of the Unix I/O model. In Unix, files, devices, pipes, and other I/O targets all use the same interface. A program simply reads from and writes to file descriptors, without needing to know where the data comes from or where it goes. Thanks to this design, pipes, redirection, and file I/O can all be implemented in the same way.
At this point, a natural question emerges, leading into the next topic. When the shell executes a command, how do system calls like fork, exec, and dup2 actually work under the hood?
Why Pipes Changed Unix Design
As discussed in the previous sections, the pipe is more than just a convenient way to connect two programs. After its introduction, the way Unix programs were designed changed noticeably. Before that, much of software was built as a single program containing multiple functions. In other words, reading data, processing it, and producing output all happened within one program. While this structure could be easier to manage since everything was centralized, it also led to increasing complexity. As more features were added, the code grew larger and maintenance became more difficult. At this point, Unix chose a different path.
The pipe made it possible to design programs as smaller, more focused components. Programs no longer needed to include every function. One program could generate data, another could transform it, and yet another could analyze the result. What mattered was not what a program did internally, but what data it accepted as input and what data it produced as output. Connections between programs were handled through pipes, allowing programs to evolve independently. Even if one program was modified or a new one was introduced, the overall system could continue to operate reliably.
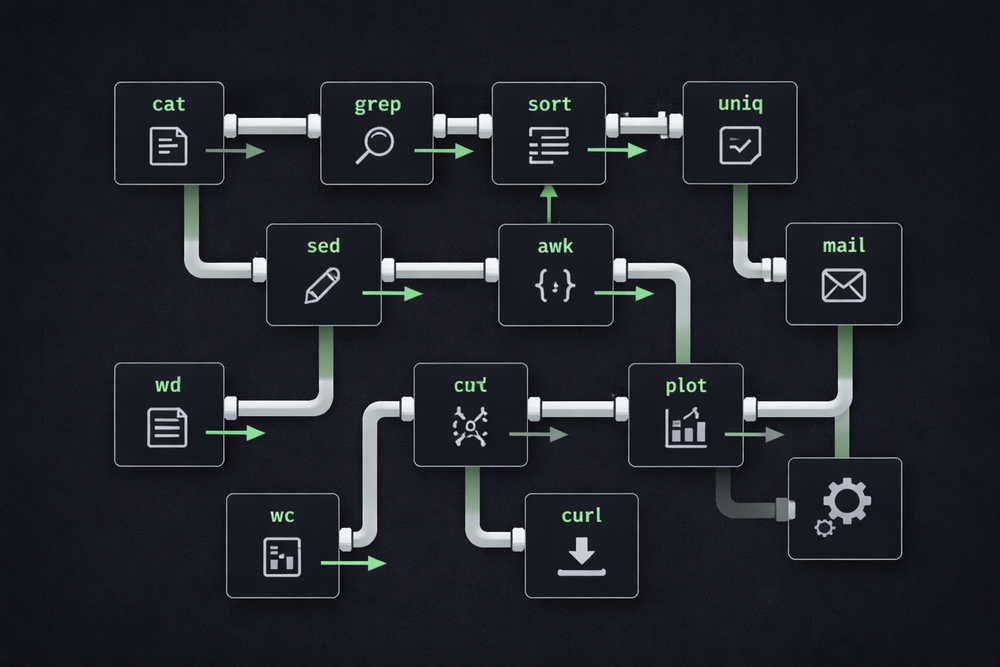
This design approach is ultimately summarized as the Unix philosophy. Programs should do one thing well and be designed to work together with other programs. This philosophy was not just an abstract development principle—it emerged naturally from the structure of the operating system itself. The pipe was the key tool that made this philosophy practical, acting as the mechanism that allowed programs to cooperate through the flow of data. As a result, Unix became not a collection of large, monolithic programs, but an ecosystem of small, composable tools. And it is precisely this ecosystem structure that made Unix such a flexible system.
Another interesting aspect is how this structure influenced users as well. Unix users became accustomed not just to running programs, but to solving problems by composing them. The act of connecting multiple commands with pipes in the terminal became a form of problem-solving in itself. This approach ultimately gave users the ability to construct systems on their own. Although the pipe may seem like a simple feature, it fundamentally changed the way both developers and users think.
The Idea of Pipes Is Still Alive Today
The pipe was introduced in the early 1970s, but its core concept is still used in many forms today. Anyone who uses the Linux shell still relies on the | symbol as one of the most fundamental tools. It remains highly useful for tasks such as analyzing log files or filtering data. The fact that the same syntax is still in use decades later shows how enduring the Unix design has been. However, the influence of pipes extends far beyond the shell environment.
Similar structures can be found in modern data processing systems. For example, log processing systems and stream processing platforms are typically built around pipeline structures where data flows through multiple stages. One system generates data, another processes it, and yet another stores or analyzes the results. This type of architecture is fundamentally centered around the flow of data. The Unix pipe follows the same principle—one program produces data, and another program processes it.
This structure becomes even more apparent when looking at stream platforms like Kafka or various data pipeline systems. Data flows from producers to consumers, passing through multiple stages of processing. This flow is similar to chaining multiple commands together with pipes. Of course, modern systems are far more complex and operate in distributed environments, but the underlying concept remains largely the same. Data flows, small processing tasks are performed at each stage, and the results are passed along to the next stage.
Seen in this light, the Unix pipe is not just a shell feature—it is closer to a prototype of modern data processing systems. The approach of building systems around data flow while minimizing tight coupling between components has influenced countless software designs. And that influence continues to this day. It is quite fascinating that many systems we use in cloud environments today resemble ideas that first appeared in Unix over 50 years ago.
The Change Brought by a Single Small Symbol
When we type the | symbol in the terminal, we rarely give it much thought. We simply see it as syntax for connecting two commands. But behind this small symbol lies a surprisingly deep design story. The Unix pipe changed the way programs cooperate, and as a result, it transformed how programs are designed. Programs no longer needed to implement every feature themselves. Instead, small tools could be connected to create more complex functionality. This structure turned Unix from a simple operating system into an ecosystem of tools.
The feature implemented by Ken Thompson may have seemed like a small improvement at first. However, its impact was far greater than expected. Thanks to pipes, Unix programs could remain small and simple, and even as new programs emerged, they could naturally integrate with the existing system. This structure became one of the key reasons Unix was able to endure for so long. Rather than concentrating complex functionality into a single program, combining simple tools proved to be a far more flexible approach.
Pipes also brought an important change to users. Users no longer simply executed programs—they began solving problems by composing them. The act of connecting multiple commands in the terminal is, in a sense, a form of lightweight programming. Users can create their own data processing flows and use them to perform a wide variety of tasks. In this way, the pipe goes beyond being a simple feature and begins to shape the way users think.
Ultimately, the single | symbol we casually use in the terminal carries a long history of technology and design philosophy. The simple yet powerful design choices made by Unix continue to influence many systems even today. And these ideas become even more interesting as we explore other Unix features. In the next article, we will look at another closely related topic: what actually happens when the shell executes a command, and how system calls like fork, exec, and dup2 form the Unix process model.
Next Topic: Shell Redirection and the Unix Process Model
So far, we have explored how the Unix pipe emerged and why it carries meaning beyond simple shell syntax. On the surface, it looks like inserting a single | symbol between commands, but in reality, the operating system performs complex work behind the scenes—creating multiple processes and connecting file descriptors. The structure in which the output of one program naturally flows into the input of another is made possible by the Unix I/O model and process model. At this point, a natural and interesting question arises: what actually happens when we execute a command in the shell?
For example, consider the moment you type a simple command like ls in the terminal. From the user’s perspective, it is just a single command. But internally, the shell creates a new process and prepares to execute the program. This process involves system calls such as fork() and exec(). The fork() call duplicates the current process to create a new one, and exec() runs the actual program within that process. Thanks to this structure, the shell can execute user commands as independent processes. The same mechanism applies when using pipes. When a command like ls | sort is executed, the shell creates two processes and connects their inputs and outputs.
A key element in this process is the use of file descriptors and redirection. In Unix, there are three basic I/O channels: stdin, stdout, and stderr. Programs read from and write to these channels by default, and the shell can redirect them to files or pipes as needed. Redirection syntax such as > or < is simply a way to change these connections. Pipes operate on the same principle—they connect output and input, but use a pipe instead of a file. Because of this design, files, pipes, and devices in Unix are all handled in the same way.
Once you understand this internal structure, it becomes clear that the shell is not just a command execution tool—it is a small process management system. The shell interprets user input, creates the necessary processes, and connects their I/O appropriately. All of this is built on a few fundamental system calls. Calls such as fork, exec, and dup2 are at the core of the Unix process model, and features like pipes and redirection are ultimately implemented through them.
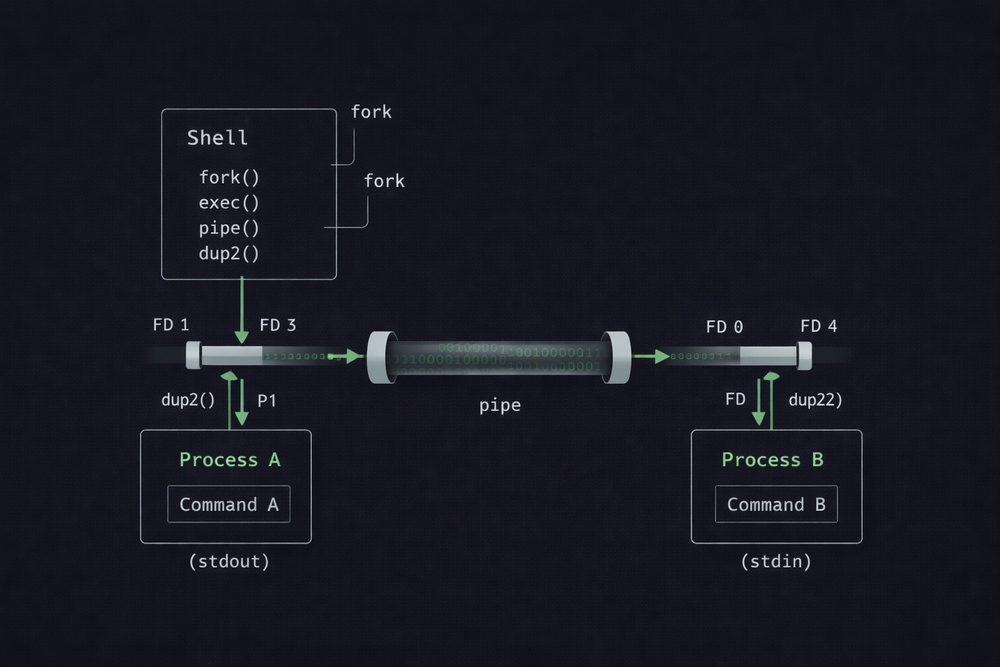
In the next article, we will explore this area in more depth. We will examine the exact sequence of system calls the shell uses when executing commands, how fork and exec create new processes, and how dup2 rearranges file descriptors. If pipes define how programs are connected, then these system calls are the engine that makes that structure actually work. In other words, behind the single line of command we type into the terminal lies a far more sophisticated process model than it might seem.
In the next post in this series, “How Shell Redirection Actually Works — The Unix Process Story Behind fork, exec, and dup2” we will follow that internal mechanism step by step. Once you understand how the shell constructs pipes and connects processes and file descriptors, the behavior of Unix commands becomes much clearer. And at that moment, a single line typed into the terminal may start to feel like a small operating system experiment in itself.