The Strange Statement: “Everything Is a File”
Among the many phrases used to describe Unix, one of the most well-known is this: “Everything is a file.” Translated into Korean, it means exactly that—everything is a file. For someone encountering this statement for the first time, it often raises confusion. When we think of a file, we usually imagine something stored on disk—text files, image files, or executable programs. These are what we commonly understand as files. Yet in Unix, keyboard input is treated as a file, the terminal display is treated as a file, and even network connections are handled as if they were files. At first, this may sound like an exaggerated metaphor or perhaps an odd expression from an old system. But this statement is not just a philosophical slogan—it describes a very concrete technical choice that runs through the entire design of Unix.
To understand this idea, it helps to first consider how complex the computer systems we use actually are. An operating system must manage many different types of devices simultaneously. Reading and writing data to disk, handling keyboard input, sending data over a network, and displaying information on a screen are all fundamentally different kinds of tasks. In most systems, these devices are accessed through different interfaces and rules. There are separate APIs for disk I/O, for network communication, and for terminal input/output. As functionality increases, this structure makes the system more complex. Programmers must understand different rules for each type of device, and whenever a new device appears, they must learn a new interface.
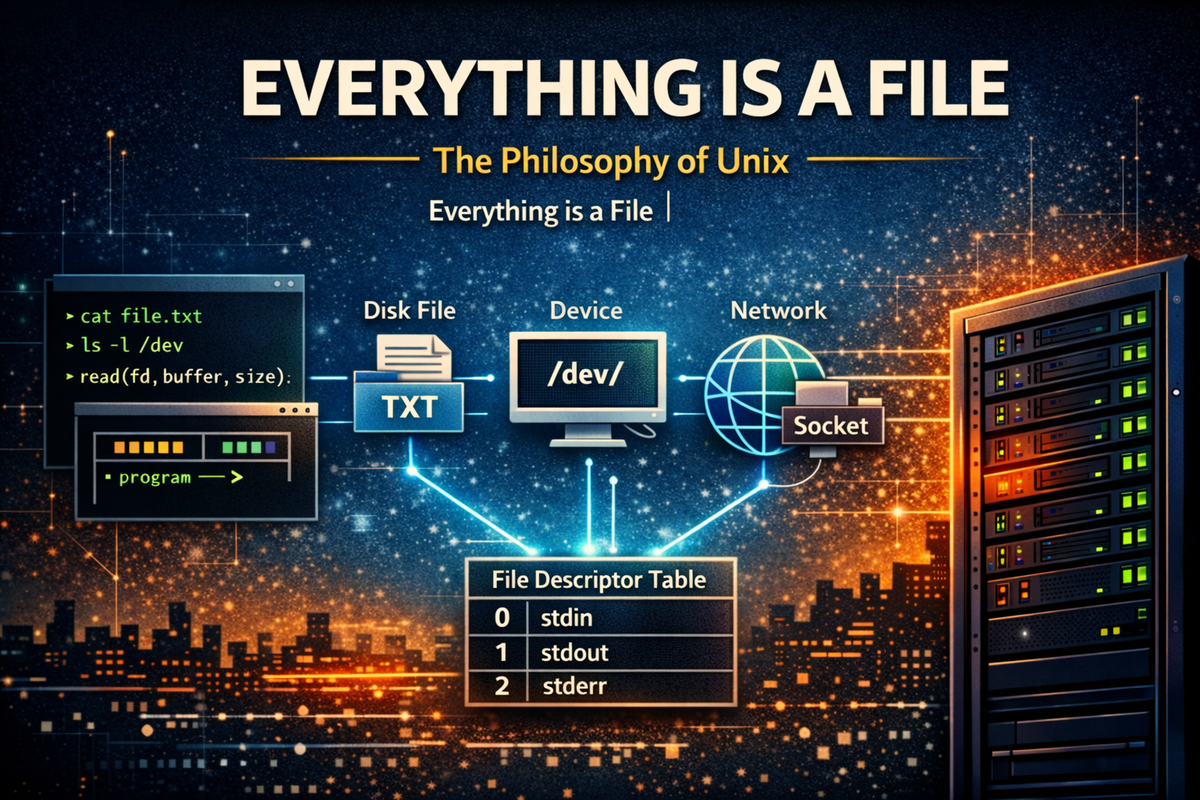
The designers of Unix chose to solve this problem in a completely different way. Instead of continually adding more complex interfaces, they tried to represent as much as possible through a single, simple model. That model was the file. Not just disk files, but terminals, pipes, devices, and network connections were all made to appear as files. With this approach, programs no longer need to worry about what kind of object they are interacting with. They can always use the same interface to read and write data. As a result, the system becomes much simpler, and programs can operate more easily across different environments and devices.
At this point, a natural question arises. How did Unix actually implement such a model within its system architecture? And why has this approach survived longer than those of many other operating systems? To answer these questions, we need to take a closer look at the computing environment in which Unix was originally created.
The Computing Environment of the 1970s — The Problems Before Unix
The computing environment of the early 1970s was very different from today. Computers were massive machines, and most users accessed systems remotely through terminals. Operating systems had to manage a variety of hardware devices simultaneously, and each device operated in its own distinct way. Disk drives read and wrote data in blocks, printers received streams of characters and printed them onto paper, keyboards acted as input devices, and tape drives processed data in yet another manner. The problem was that all of these devices required different interfaces.
In many operating systems of that time, each device had its own dedicated API. To read a file from disk, a program had to use a specific system call. To send output to a printer, it needed a different interface. Communication with terminals followed yet another set of rules. As systems grew larger, this structure became increasingly difficult to manage. Every time a new device was introduced, a new interface had to be designed, and programs had to handle more and more exceptional cases. As a result, operating systems became collections of complex features, and the programs running on top of them grew increasingly complicated as well.
At Bell Labs, where Unix was being designed, Ken Thompson and Dennis Ritchie took a different perspective on this problem. Instead of building an operating system as a large collection of features, they aimed to construct it around a small set of core concepts. Rather than handling each type of device separately, they wanted to create a model in which all devices could be accessed in the same way. This was not just a decision to reduce code complexity—it was a design strategy to make the system more flexible.
The core idea was remarkably simple. Whether it was a disk file, a terminal, or a device, all of them shared a fundamental property: they were sources or destinations of data. If that was the case, was it really necessary to treat them differently? If all devices could be accessed through a single interface, programs could become much simpler. Even when new devices were introduced, existing programs could continue to work with minimal or no modification. This line of thinking led to the famous Unix design philosophy: “Everything is a file.”
This philosophy was not just a statement—it was a design principle deeply embedded in the structure of the Unix kernel. However, to make this idea work in practice, one critical problem had to be solved. To handle different devices and resources in a unified way, there needed to be a simple yet powerful interface between programs and the kernel. That interface became the Unix file model.
The Core Idea of Unix — A Unified Model Called “File”
In Unix, the concept of a file is much broader than what we typically think of. For most users, a file is a unit of data stored on disk. But from the perspective of the Unix kernel, a file simply means anything that can be read from or written to as a stream of bytes. In other words, a file does not refer to a specific storage medium—it represents an interface through which data can be transferred. A program does not need to know the actual type of file; it only needs to know that it can read and write data.
This model is implemented through a very simple system call interface. Unix programs use read() to read data and write() to write data. These same functions are used whether reading from a disk file, receiving data from a pipe, or communicating through a network socket. Programs do not need to care about where the data comes from or where it is going—the kernel handles those differences.
Thanks to this structure, Unix programs could remain very simple. Programs did not need to include complex device control logic. Whether data came from a file, a terminal, or a pipe, it could be handled in the same way. This design greatly increased the reusability of programs. The same program could process file data, network data, or the output of another program without modification.
This model also made Unix systems easy to extend. When a new device was introduced, the kernel could expose it through the same file interface, allowing existing programs to use it without any changes. This is one of the key reasons Unix has survived across such a wide range of environments for decades. Instead of solving complexity by adding more features, Unix organized the entire system around a single, simple model.
At this point, it becomes clear that the statement “Everything is a file” is not just a metaphor—it reflects an actual system design. To understand how this model is implemented in real programs and within the operating system, we need to move to the next step: examining the file descriptor structure, which serves as the core mechanism behind this model.
File Descriptors — The Core Structure of the Unix I/O Model
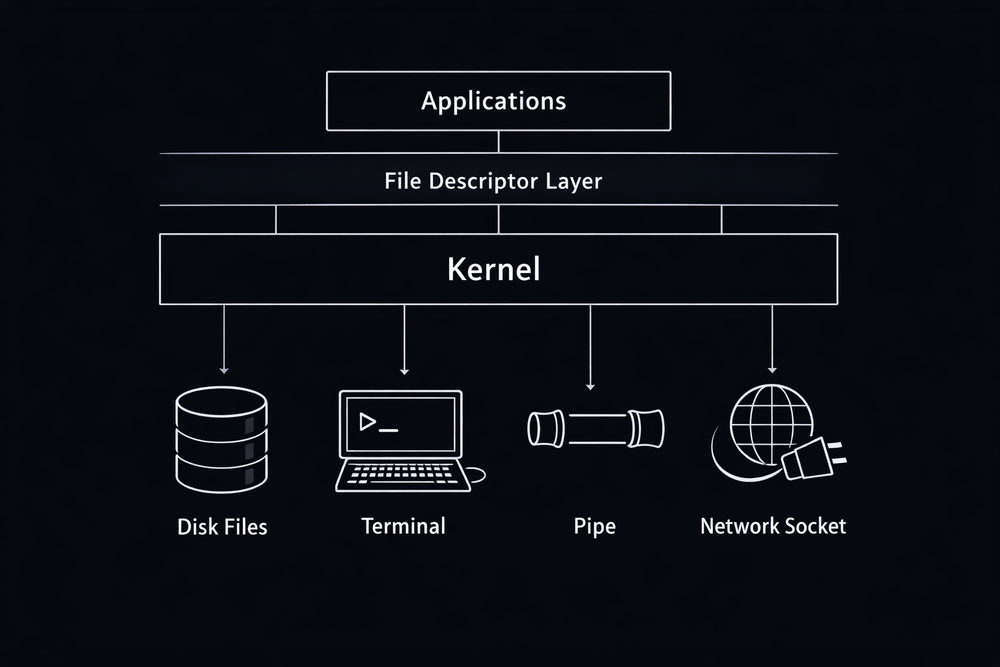
As discussed earlier, Unix aimed to unify various devices and resources under a single file interface. However, for this philosophy to work between programs and the operating system, a concrete mechanism was required. There needed to be a way to manage which file a program was using, which device it was connected to, and where data should be read from or written to. Unix solved this problem with a very simple idea: the file descriptor.
A file descriptor is, quite literally, a small integer that refers to a file. When a program opens a file, the kernel creates an internal structure for that file and returns a number that can be used to reference it. From that point on, all I/O operations are performed through this number. System calls like read(fd, buffer, size) or write(fd, buffer, size) do not care about the type of file. They simply instruct the system to read from or write to whatever object that number refers to. That number might point to a disk file, a pipe, or a network socket—but from the program’s perspective, there is no need to distinguish between them. Thanks to this simple abstraction, Unix programs can achieve a highly flexible structure.
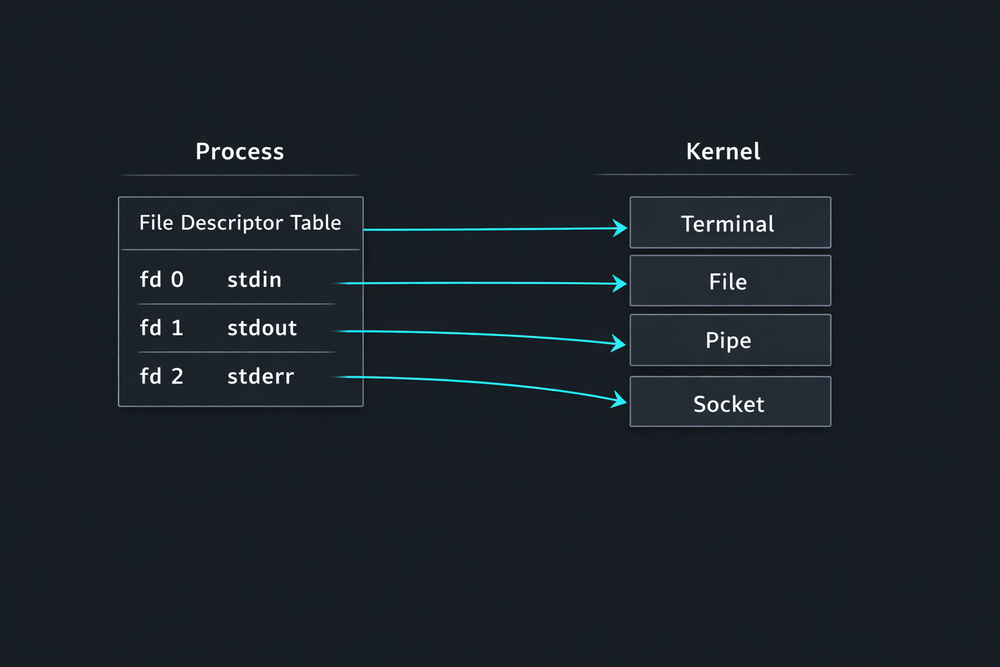
One particularly important detail is that every process starts with three file descriptors already open. These correspond to standard input (stdin), standard output (stdout), and standard error (stderr). In other words, as soon as a program starts, its basic input and output channels are already prepared. When a program writes data to stdout, that data appears on the terminal. However, if the shell redirects stdout to a file, the same program will write to that file without any modification. This structure is essential for understanding concepts such as the separation of stdout and stderr, as well as redirection syntax like 2>&1. The file descriptor model enables powerful I/O reconfiguration in Unix, forming the foundation of the flexible input/output combinations we experience in the shell environment.
Terminals and Device Files — What the /dev Directory Represents
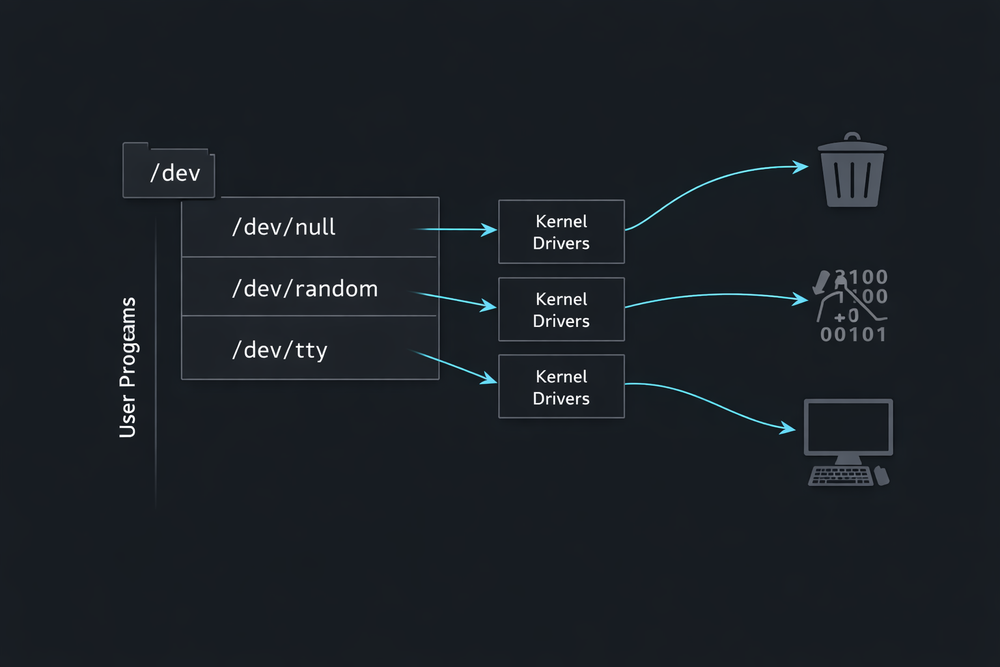
In Unix systems, the place that most clearly demonstrates how the philosophy “Everything is a file” is actually implemented is the /dev directory. For someone seeing it for the first time, it can feel unfamiliar. This directory contains many files, but most of them are not data files in the usual sense. Instead, they represent actual hardware devices or kernel-level functions. For example, files like /dev/null, /dev/random, and /dev/tty do not store data on disk—they point to specific device interfaces inside the kernel.
The core idea of this structure is to make devices appear as files. For instance, /dev/null is a device that discards data. When a program writes to this file, the data is not stored anywhere—it simply disappears. However, the program does not need to know this. It just writes data as if it were writing to a regular file. Similarly, /dev/random behaves in a comparable way. When a program reads from this file, the kernel returns randomly generated data. From the program’s perspective, there is no need to use a special API for random number generation—it simply reads from a file. This design greatly simplifies the boundary between device drivers and user programs.
This device file model highlights an important characteristic of Unix design. Instead of exposing new functionality through entirely new interfaces, the operating system integrates them into the existing file interface. Programs only need to know how to work with files. They do not need to distinguish whether a file represents data on disk, a device provided by the kernel, or some other system feature. Thanks to this design, a wide variety of tools in Unix can operate in the same way. For example, a command like cat /dev/random works because cat simply reads from a file and writes to standard output—the fact that the file is a random number generator is irrelevant to the program.
This structure also greatly improves the extensibility of Unix systems. When a new device is introduced, the kernel can expose it through the file interface, allowing existing programs to use it without modification. This is possible because device drivers implement file operations within the kernel. In this sense, the /dev directory is not just a list of files—it is a space where Unix philosophy is realized as an actual system structure.
Pipes and Streams — The Unix Philosophy of Connecting Programs
One of the most well-known features that demonstrates the power of Unix philosophy in practice is the pipe. A pipe connects two programs, allowing the output of one program to become the input of another. While this concept feels very familiar to modern developers, it was a highly innovative feature when it first appeared. This is because it introduced a new way of thinking about programs—not as isolated execution units, but as components that can be connected together.
The way pipes operate is also built on top of the file descriptor model described earlier. When the kernel creates a pipe, it produces two file descriptors: one for reading and one for writing. The first program writes data to the pipe’s write descriptor, and the second program reads data from the read descriptor. In this structure, the programs do not even need to know that they are using a pipe. They simply read from or write to file descriptors, while the kernel handles the data transfer between them internally.
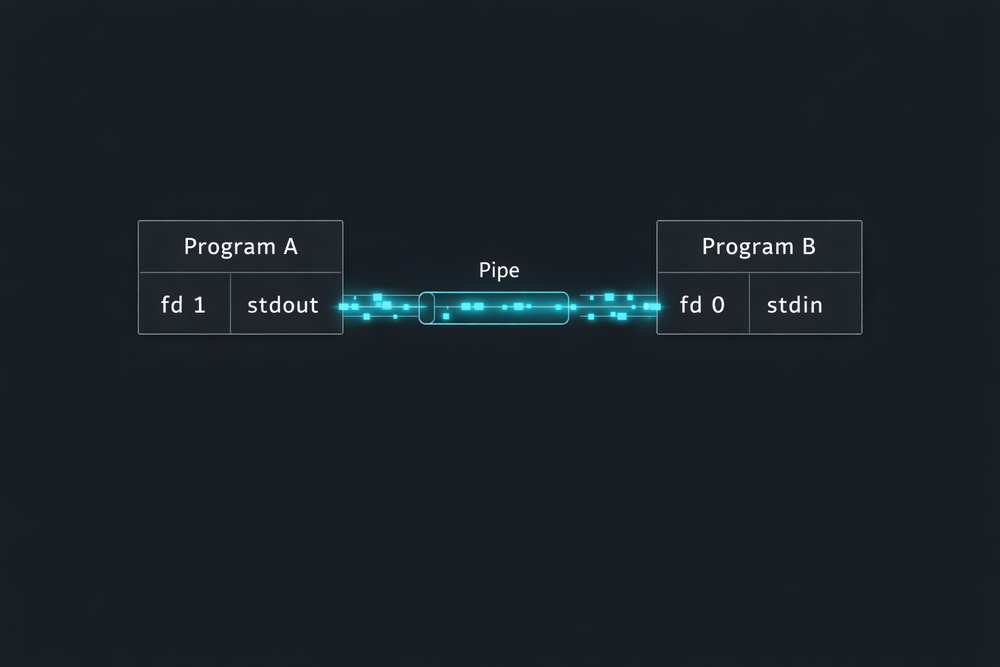
This design is closely tied to one of the core statements of Unix philosophy: “Write programs that do one thing well.” In Unix, small programs perform individual tasks, and when needed, they are connected through pipes to accomplish larger goals. Tools like grep, sort, uniq, and wc each provide very simple functionality, but when combined through pipes, they become powerful data processing tools.
An important characteristic of pipes is that data flows as a stream. Programs do not need to process all data at once. They can begin processing as soon as input arrives, and their output can be passed to the next program in real time. This stream-based structure allows Unix systems to provide highly efficient data processing environments. And ultimately, all of this is made possible because Unix unified all input and output into file descriptor–based streams.
Network Sockets Are Also Files — An Extension of the Unix Philosophy
Once you understand file descriptors, device files, and pipes, a natural question arises: how far can this model be extended? It is already fascinating that disk files, terminals, and kernel devices can all be treated as files, but Unix design did not stop there. Unix extended this same model into an entirely different domain—network communication. The result is that sockets are also represented as file descriptors. At first, this may seem surprising, since network communication appears fundamentally different from file operations. But from the perspective of Unix designers, a network connection is simply another stream of data that can be read and written.
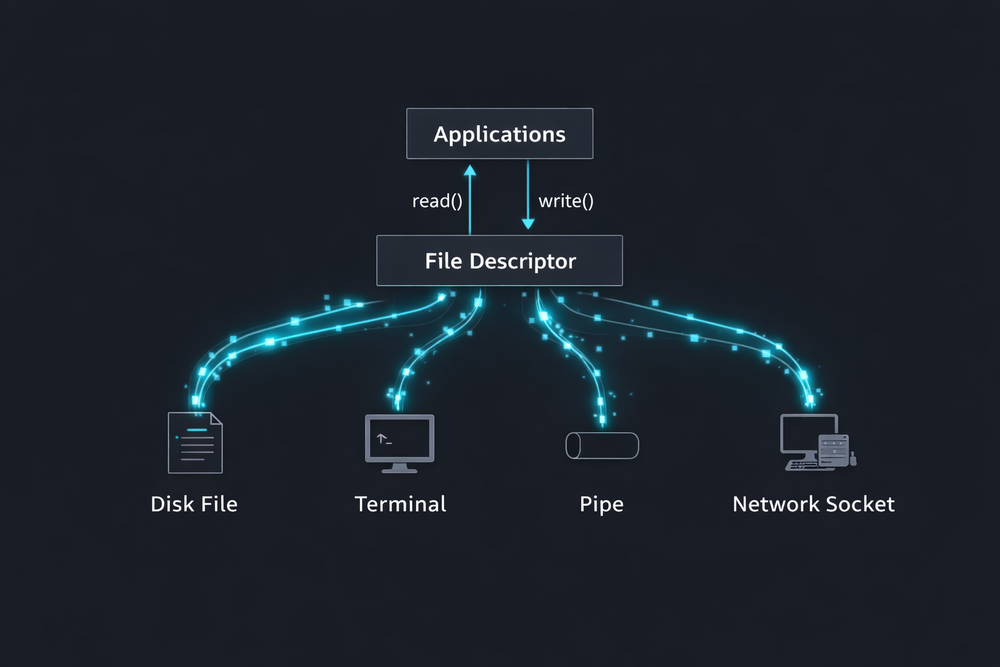
The fact that network sockets are represented as file descriptors has significant implications. Programs do not need a completely different interface to send data over a network. When a socket is created, the kernel returns a file descriptor, and the program can use read() and write() on that descriptor. In other words, from the program’s perspective, there is little difference between network communication and file I/O. Thanks to this structure, programs that were originally designed to process file data can often handle network data with little or no modification. For example, a program that reads input from standard input can work the same way even if that input is connected to a network socket instead of a file. This flexibility played a key role in making Unix the foundation for many server applications and network tools.
This design is a clear demonstration of the strength of Unix philosophy. With the simple abstraction of file descriptors, disk files, terminals, pipes, devices, and network sockets can all be accessed through the same interface. This not only simplifies programming, but also reduces the overall complexity of the system. Programs do not need to worry about the specific nature of their input and output—the kernel handles those differences internally. As a result, Unix systems can operate consistently across a wide variety of environments, and this structure has become the foundation of modern server software and network services.
Why This Design Has Survived for Decades
The Unix philosophy of “Everything is a file” may seem like a simple idea, but its significance becomes much deeper when we consider why this design has endured for so many decades. Unlike many software systems that grow increasingly complex over time and are eventually replaced by entirely new architectures, the Unix I/O model has remained almost unchanged since the 1970s. The reason is that it is based on abstraction rather than tied to any specific technology or device. As disk technologies evolved, networks advanced, and computer architectures changed dramatically, the Unix file model could remain intact because it abstracts the flow of data itself, not the behavior of individual devices.
Another key reason is that this design makes systems extremely easy to extend. Whenever a new device or feature is introduced, there is no need to create an entirely new interface. Instead, the existing file interface can be reused, with new device drivers implemented inside the kernel. User programs do not need to understand how the device works internally—they can interact with it in the same way as any other file. This structure has allowed countless tools and programs in the Unix ecosystem to remain usable for long periods of time. Even a program written 20 years ago is likely to continue working in a new environment as long as it relies on the file interface.
This design also provides developers with powerful composability. Because the system is built around the file interface, connecting programs becomes straightforward. Features like pipes and redirection are built directly on top of this model. Programs only need to read and write data, while the shell and kernel handle how that data flows between components. This simplicity has led to an ecosystem of small, specialized tools that can be combined in flexible ways. In the end, the philosophy of “Everything is a file” is more than just an interface unification—it is the foundational design that made the entire Unix tool culture possible.
Influence on Modern Systems — A Philosophy That Extends to Containers and the Cloud
At this point, an interesting question naturally arises: does a design created in the 1970s still matter in today’s computing environment? Surprisingly, the answer is very close to yes. Even in modern cloud environments and container platforms, the Unix file-based I/O model continues to play a crucial role. A representative example is the container logging system. Platforms like Docker and Kubernetes recommend sending application logs not to files, but to standard output (stdout) and standard error (stderr). The container runtime then collects these streams and forwards them to a logging system. This approach directly leverages the Unix standard stream model.
This structure is not just a convention—it is a highly practical design. Applications do not need to worry about where logs should be stored; they simply write to stdout or stderr. The container runtime and orchestration system take responsibility for collecting, storing, or forwarding that data to a centralized logging system. This approach reduces the coupling between applications and infrastructure, allowing logs to be handled consistently across different environments. In other words, the standard stream model introduced in Unix remains a valid abstraction even in modern distributed systems.
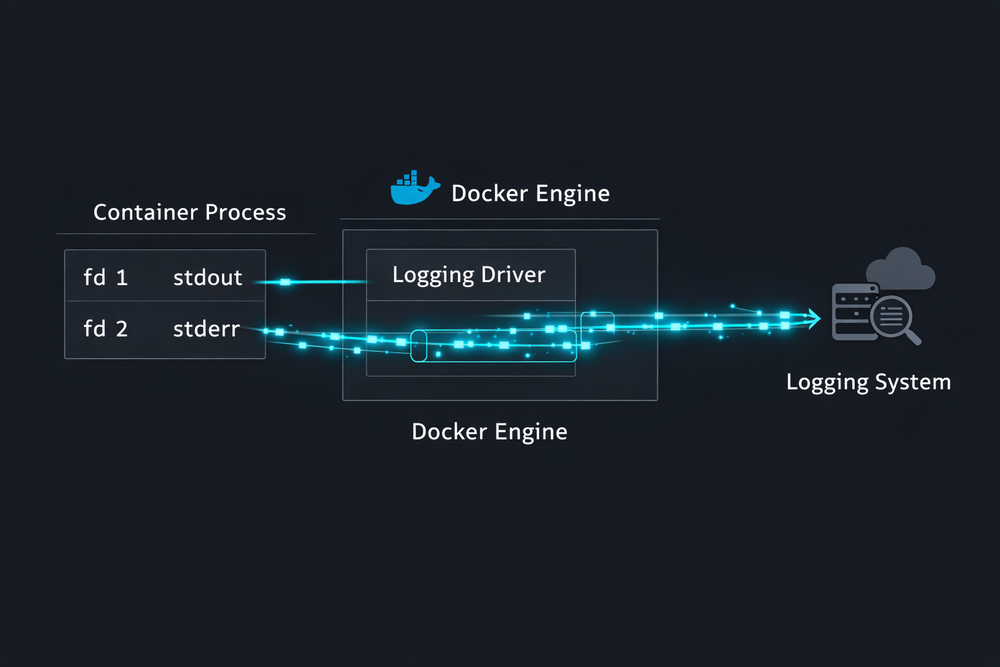
This demonstrates the long-lasting impact of Unix design. The simple idea of file descriptors and stream-based I/O continues to be used in new technological environments decades later. Ultimately, the philosophy of “Everything is a file” is not just an operating system design principle—it is a concept that has deeply influenced modern software architecture. And this becomes even clearer in the next article. By examining why so many systems in the container era still rely on stdout-based logging models, we can better understand just how powerful the Unix I/O design truly is.
A Simple Abstraction with a Massive Impact — The Meaning of Unix Philosophy
Looking back at everything we have explored, a clear pattern emerges. The philosophy of “Everything is a file” chosen by Unix designers was not merely a technical decision for implementation convenience inside the operating system. It was a design philosophy aimed at simplifying the way we understand and interact with systems. Computer systems are inherently complex. Disks operate as block devices, networks transmit data in packets, and terminals function as input/output devices for users. Each of these components follows a different operational model, and exposing them directly would require programs to use entirely different interfaces for each one. Unix, however, chose a different path: it hid this complexity within the kernel and provided a single, simple file interface on top.
This design fundamentally simplified the structure of the system. Programs only need to know how to read from and write to files. They do not need to know whether a file resides on disk, is connected to another process through a pipe, communicates with a remote system via a network socket, or represents a kernel device. Because of this structure, programs in Unix can be easily combined. The output of one program naturally becomes the input of another, and the shell can freely construct these connections using redirection and pipes. Ultimately, the reason small Unix tools can scale into powerful systems lies in this simple I/O model.
This philosophy also demonstrates what kind of design can survive through technological change. Since Unix first appeared, computing environments have changed dramatically. Personal computers emerged, the internet connected the world, and cloud and container technologies created entirely new infrastructure models. Yet through all of these changes, the core Unix I/O model has remained almost unchanged. The reason is that this design is not tied to any specific technology or device—it is built around the universal concept of data flow. Whether dealing with disk files or network streams, programs ultimately read, process, and write data. Unix captured this reality with a simple interface, and that is why the design has endured for decades.
From this perspective, the phrase “Everything is a file” is not just a technical description—it is a statement that represents the essence of Unix philosophy. Instead of continuously adding new interfaces to handle complexity, it reflects an approach that solves problems within an existing, simple model whenever possible. This philosophy explains why Unix tools compose so well together, and it has influenced many modern system designs. Similar principles can be seen in microservices architectures and stream-based data processing systems today, where complex systems are broken into small components connected by simple data flows.
At this point, we can return to the original questions. Why did Unix separate stdout and stderr? Why were pipes introduced? Why does redirection exist? All of these features ultimately operate on the same I/O model. Thanks to the simple structure of file descriptors and streams, Unix made it possible to connect programs freely, and this composability is what gives the Unix environment its powerful productivity.
In the next article, we will explore how this I/O model reappears in modern container environments. By understanding why systems like Docker and Kubernetes still rely on stdout and stderr for logging, it becomes even clearer that Unix design is not just a relic of the past—it is an idea that is still very much alive today.