
A Strange Recommendation in the Container Era
Developers who have operated applications in a container environment have likely encountered a similar piece of advice at least once. When reading documentation related to Docker or Kubernetes, there is a recommendation that appears almost without exception: do not write application logs to files—output them to stdout instead. For developers accustomed to traditional server environments, this advice can feel somewhat unfamiliar at first. After all, for decades, it has been taken for granted that server applications write logs to files. Most server software has been built around log files, and operators have managed systems based on those files.
However, in container environments, this perspective changes. Applications still generate logs, but the responsibility for storing those logs no longer belongs to the application itself. Instead, the container runtime or orchestration system takes on the role of collecting and storing logs. The application simply outputs logs to stdout and stderr, and everything that follows is handled by the platform. At first glance, this may seem like a matter of operational convenience, but in reality, it is deeply connected to a much older system design.
At this point, an interesting question emerges. Why do container platforms recommend outputting logs through stdout instead of having applications manage log files directly? Is it simply because container environments are different, or is there a deeper, older reason behind it? If we follow this question further, we eventually arrive at the way the Unix operating system was designed. The concepts of stdout and stderr are not just about console output—they are the fundamental interfaces through which programs and systems exchange data. And that same interface is being reused in container environments today.
This article begins at that exact point. Why are Docker logs based on stdout, and why does this structure feel so natural? To answer this question, we first need to revisit the file-based logging approach that we have taken for granted for so long. To understand logging in container environments, we must first understand what we have always assumed to be obvious.
The Era of Log Files
Long before container technologies emerged, the fundamental tool of server operations was the log file. Almost all server software—web servers, databases, message queues, and application servers—generated various logs during execution and wrote them to files. For example, the Apache web server records request logs and error logs in separate files, and Nginx also clearly separates access logs and error logs. These log files are typically stored under the /var/log directory, and operators analyze them to understand system status and diagnose issues.
This approach remained stable and widely used for a very long time. Servers typically ran on a single physical or virtual machine for extended periods, so it was natural for logs to be stored on that system. Operators could connect to the server via SSH, inspect log files directly, or monitor logs in real time using commands like tail. Tools such as logrotate, which automatically rotate log files when they grow beyond a certain size, were also commonly used. All of these tools were built around the assumption that logs are stored as files.
However, the log file approach had clear limitations. As the number of servers increased, logs from each server had to be managed individually, and collecting logs from multiple systems into a single place for analysis became difficult. In large-scale environments, separate log collection systems had to be built. This often involved setting up syslog servers or installing log collection agents on each machine. In other words, while the log file approach worked well in single-server environments, the operational burden grew significantly as systems scaled.
Despite these limitations, the approach persisted for a long time. The reason is simple: servers were relatively stable and ran for long periods in fixed environments. Applications were installed on specific machines, and logs remained on those machines. Operators could simply access the machine to check the logs. In such environments, file-based logging did not pose significant problems. However, as system architectures began to change, this situation also started to shift.
The Operational Model Changed by Containers
With the introduction of container technologies like Docker, the way applications are run has changed significantly from traditional server environments. In the past, applications were installed on a single server and ran for long periods. Log files accumulated continuously on that server. However, in container environments, applications are no longer tied to a fixed machine. Containers are ephemeral execution environments—they can be created when needed and removed at any time.
This characteristic directly impacts how logs are managed. If an application writes logs to files, those files are stored inside the container’s filesystem. But when the container stops or is deleted, that filesystem may disappear as well. In other words, the lifecycle of the logs becomes tied to the lifecycle of the application. From an operator’s perspective, this is highly inconvenient. When an issue occurs and logs are needed for debugging, the container—and its log files—may already be gone.
Another issue is scalability. In container-based systems, a single service may run across dozens or even hundreds of containers simultaneously. If each container generates its own log files internally, operators would have to manage a large number of separate files. As containers move between nodes or restart, the location of these logs can also change. In such environments, traditional file-based logging becomes difficult to manage effectively.
As a result, it becomes more practical for the platform, rather than the application, to take responsibility for log management. Applications simply output their results, and the container runtime collects, stores, or forwards that output to external systems. This is where the long-standing Unix concept of stdout reappears. The idea that programs write data to stdout and the system handles that output was already established decades ago in Unix.
In this sense, the container logging model can be seen as an application of that old model to a new environment. When an application writes logs to stdout, the container runtime captures that output and sends it to a logging system. This approach separates the lifecycle of logs from the lifecycle of containers, while also enabling reliable log collection in large-scale systems. And all of this works naturally on top of the Unix I/O model we are already familiar with.
At this point, the question becomes clearer. Why does stdout-based logging work so naturally in container environments? And how does Docker actually implement this structure in practice? In the next section, we will take a closer look at that mechanism.
The Approach Chosen by Docker — Using stdout as Logs
The way logs are handled in container environments takes a significantly different approach from traditional server operations. Docker does not recommend writing application logs to files. Instead, it encourages applications to output logs to stdout and stderr, while the container runtime directly collects those streams. At first glance, this may seem like a simple implementation choice, but it is actually closely tied to the nature of containers as an execution environment.
In Docker, a container is essentially a process. Running a container is, in practice, similar to running a specific process within an isolated environment. Like any Unix program, this process starts with three standard streams: stdin, stdout, and stderr. Docker builds on this fact. It intercepts everything the process inside the container writes to stdout and forwards that data to a logging system. In other words, when an application writes logs to stdout, Docker automatically captures them.
Looking at this structure more closely, the container logging system is effectively capturing a process’s standard output stream at the platform level. The application simply emits logs, and Docker reads that output stream, either storing it as a file or forwarding it to an external logging system. Docker supports various logging drivers: by default, logs are stored in JSON format, but they can also be sent directly to systems like syslog, Fluentd, or journald. The key point is that the method of log storage is determined by the platform configuration, not by the application itself.
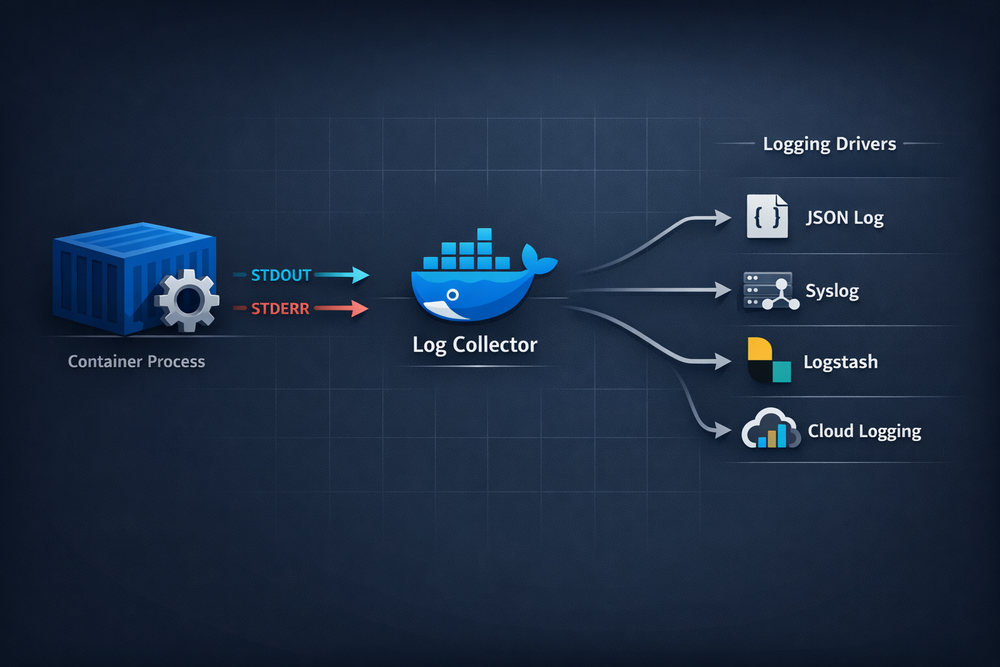
This design provides major advantages in container environments. Applications do not need to worry about where or how logs are stored—they simply write to stdout. Whether logs are saved to files, sent to a centralized logging system, or forwarded to a monitoring platform is entirely controlled by Docker’s configuration. This separation clearly defines the roles of the application and the operational platform, making log management far more flexible.
At this point, an interesting fact becomes clear. Docker did not invent a new logging system. It simply reused the existing Unix interface of stdout at the platform level. This same structure is carried forward almost unchanged in orchestration systems like Kubernetes. And at that point, the Docker logging model begins to connect with a much larger system architecture.
Logging Architecture in Kubernetes and Cloud Environments
If Docker established a stdout-based logging model in single-container environments, Kubernetes extended that model to large-scale distributed systems. In a Kubernetes cluster, countless containers run simultaneously across multiple nodes. In such environments, the key challenge is not just storing logs, but reliably collecting logs generated across many nodes and delivering them to a centralized system.
Like Docker, Kubernetes uses stdout and stderr as the default sources of logs. When an application inside a container writes logs to stdout, those logs are captured by the container runtime on the node. They are then written to the node’s filesystem or read by a log collection agent and forwarded to a centralized logging system. In this process, the application does not need to be aware of the logging infrastructure at all—it simply writes logs to stdout.
In Kubernetes environments, log agents typically run on each node. These agents read container log files stored on the node and send them to a central logging system. Common tools include Fluentd and Fluent Bit, which forward logs to platforms such as Elasticsearch, Loki, or Splunk. Thanks to this architecture, operators can view logs from hundreds of containers through a single interface.
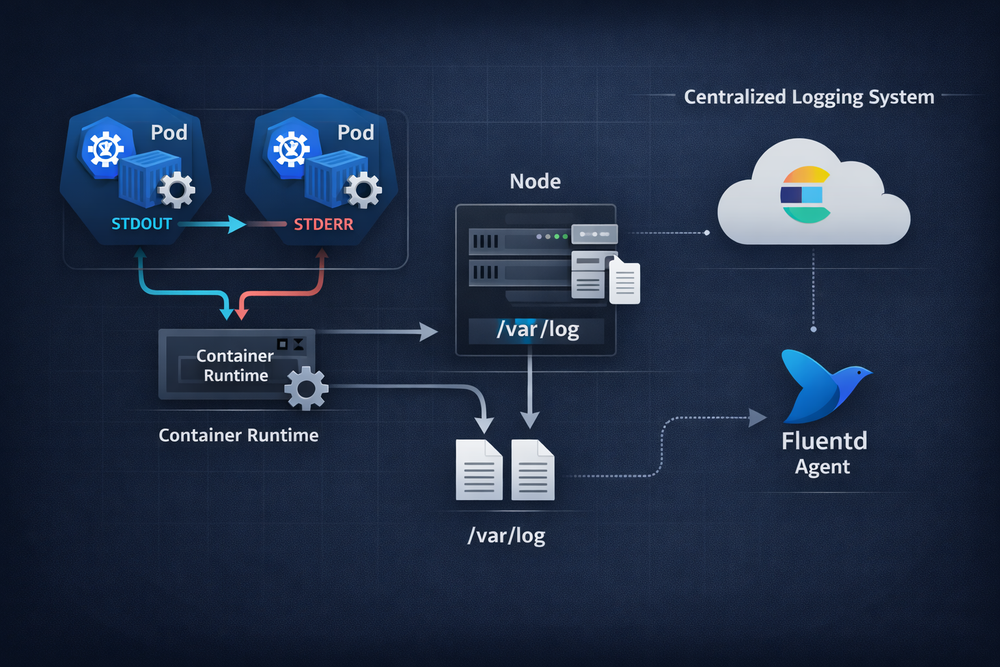
The key aspect of Kubernetes logging is the complete separation between application logging and log collection. Applications do not need to decide where logs should be stored. Logs written to stdout are automatically collected and processed by the platform. This design works reliably even in environments where containers are constantly created and destroyed, because logs are managed by the platform rather than by the containers themselves.
At this point, an important realization emerges. The way Kubernetes logging works is not a new idea—it is simply the application of the Unix stream-based I/O model to modern distributed systems. And this naturally leads to the next question: why has the Unix I/O model remained valid for so long?
In Fact, Docker Didn’t Invent Anything New
If you look closely at the logging systems of Docker and Kubernetes, their structure is surprisingly simple. A container process writes logs to stdout, and the platform collects that stream. At first glance, this may appear to be a design created specifically for container environments. But with a deeper look, it becomes clear that this structure is actually a direct extension of the Unix I/O model.
In Unix, programs were originally designed to output their results to stdout. That output could then be passed to other programs. Tools like grep, sort, and awk all write their results to stdout, and those results are delivered to the next program through a pipe. This structure is one of the core principles of Unix. Programs simply receive data as input and produce data as output, while the system connects those data flows as needed.
The logging model chosen by Docker is built directly on top of this idea. Applications inside a container write logs to stdout, and Docker captures that stream and forwards it to a logging system. In other words, Docker did not create a new interface—it reused the interface that Unix programs had always used. This is exactly why Docker’s logging system feels so natural.
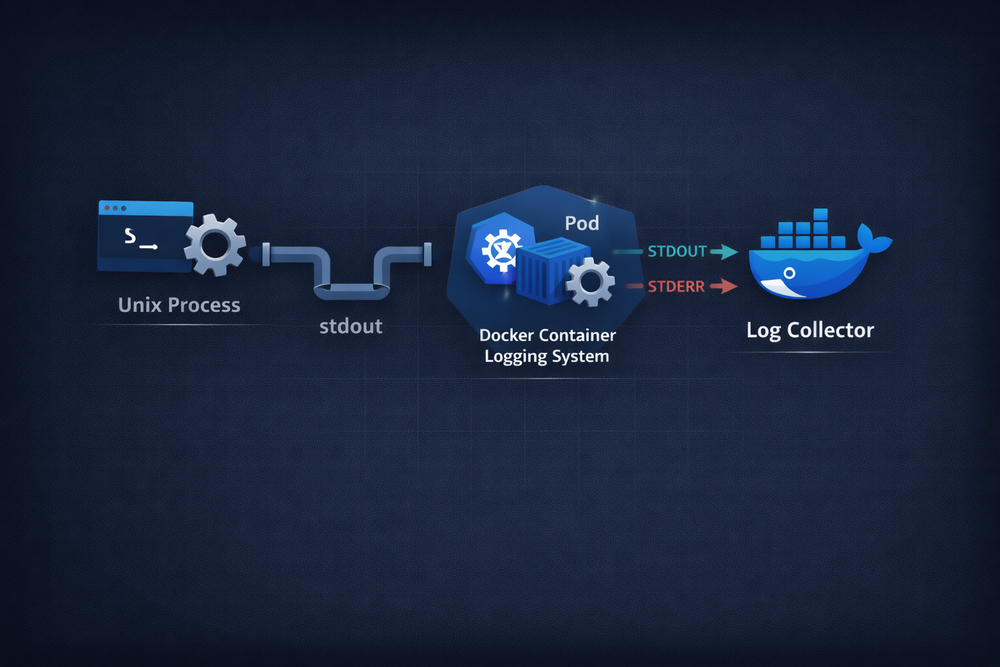
From this perspective, Docker’s logging approach is not a new invention, but rather a reuse of an older design. Unix was designed for programs to “speak” through stdout, and Docker simply uses that stdout as logs. As a result, the simple Unix I/O model continues to live on in container environments.
At this point, we arrive at a broader question. Why has this simple Unix model remained valid for so many decades? And how was it able to extend into the foundation of modern infrastructure? In the next section, we will explore these questions by taking a deeper look at the scalability and design philosophy of the Unix I/O model.
The Remarkable Scalability of the Unix I/O Model
Following the discussion so far, a natural question arises: why has the Unix I/O model survived for so long with almost no fundamental changes? Computing environments have evolved dramatically over the decades—from mainframes to personal computers, and then to internet servers and cloud infrastructure. Yet the model in which programs exchange data through stdin, stdout, and stderr remains unchanged. Even the logging systems of Docker and Kubernetes continue to rely on this decades-old structure.
The reason for this longevity lies in the fact that the Unix I/O model is both extremely simple and designed to solve a very general problem. Programs receive input, process it, and produce output. This structure does not depend on any specific technology or environment. Whether dealing with files, terminals, or network sockets, the same interface can be used to read and write data. This abstraction allows Unix programs to be reused across a wide range of environments. Programs do not need to know where the data comes from or where it is going—they simply process data through streams.
The stream-based I/O model also makes it easy to connect data flows naturally. When pipes (|) were introduced in Unix, they were more than just a way to connect two programs. They transformed programs into components of a data processing pipeline. By connecting the stdout of one program to the stdin of another, programs can work together as if they were part of a single, larger system. This idea later influenced data processing systems and stream processing architectures. Modern log processing systems and data pipelines are built on essentially the same concept.
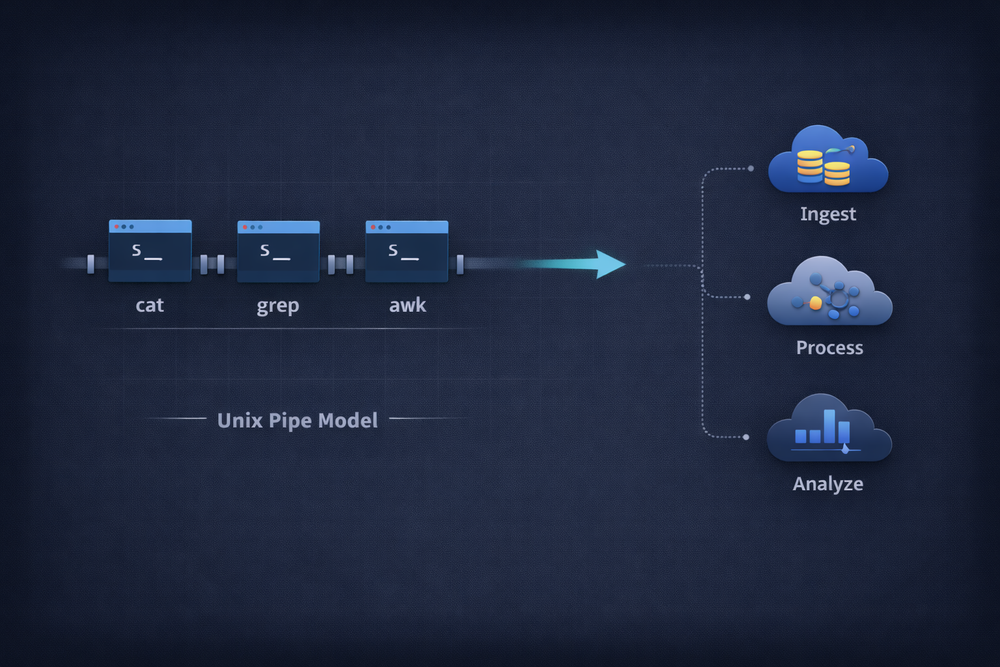
From this perspective, the Unix I/O model is not just an operating system feature—it is a general way of handling data flow. Programs take input, process it, and produce output, which can then serve as input for another program. This structure is not tied to any particular era of technology; it is a universal model that applies to almost all software systems. The reason Docker’s logging model is built around stdout is precisely because this approach has already been proven to work.
A Small Unix Design That Shaped Modern Infrastructure
When we examine the logging systems of Docker and Kubernetes, an interesting insight emerges. Many technologies we consider part of modern cloud infrastructure are not entirely new inventions, but rather the reuse of existing ideas at a different scale. The way Docker captures a container process’s stdout and forwards it to a logging system is fundamentally not very different from how Unix pipes program output to another program. The only difference is that the destination is no longer another process, but a log collection system.
Container platforms break applications into small execution units and connect them through networks and message streams. At first glance, this may seem like a highly complex distributed system, but in reality, it closely resembles the philosophy Unix adopted long ago. Programs perform a single function and are connected to form a larger system. Just as Unix tools like grep, sort, and awk are connected through pipes, modern microservices are connected through APIs or message streams.
Container logging follows the same principle. Applications simply output messages to stdout. That output is captured by the container runtime and then forwarded to a centralized logging platform through a log collection system. In this process, the application does not need to know where logs are stored or how they are collected. This separation is a crucial design feature, as it clearly divides responsibilities between the application and the operational infrastructure.
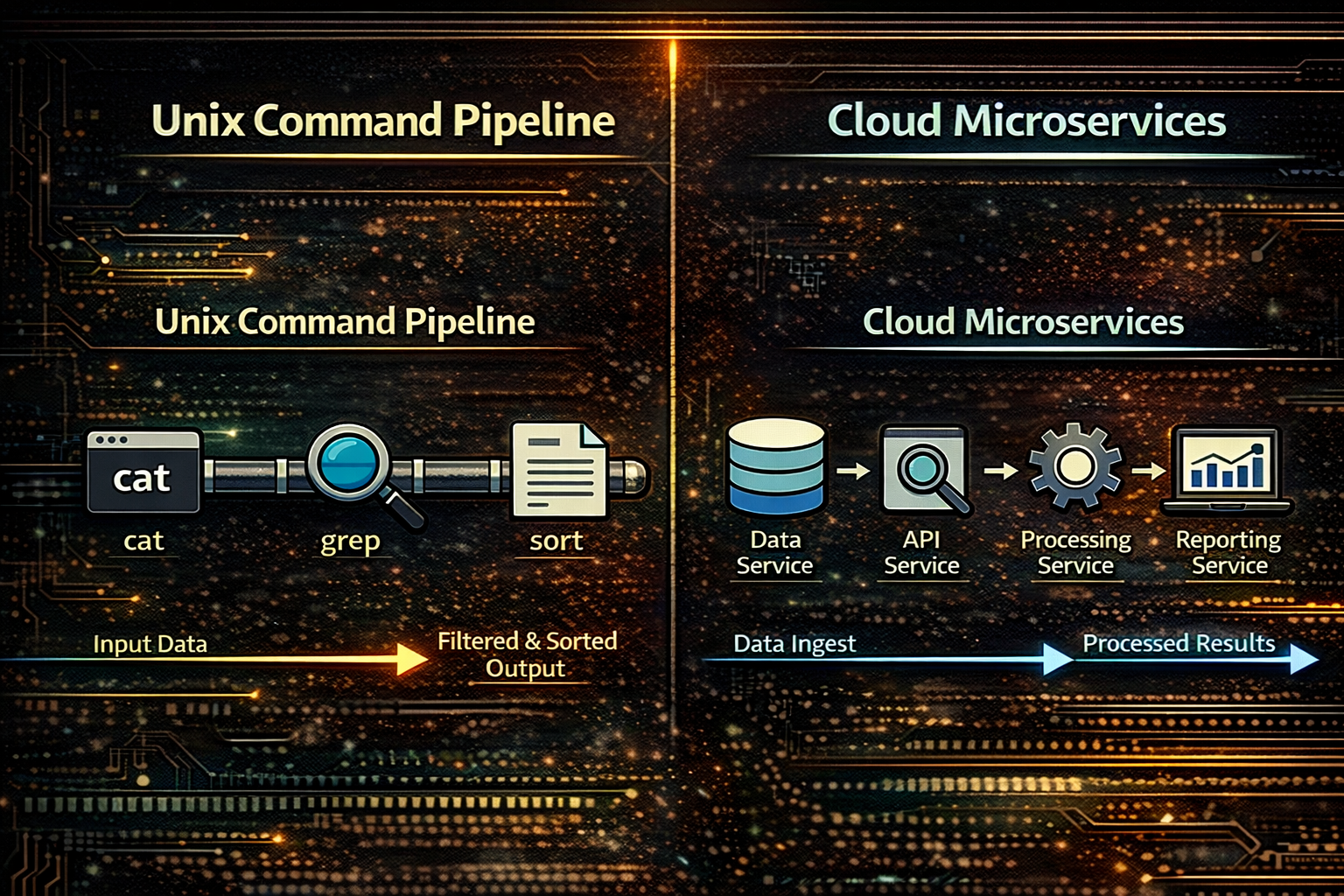
This similarity is not accidental. Unix was designed from the beginning to break programs into small components and connect them through data streams. Docker and Kubernetes apply the same philosophy at a different scale. Programs produce data, and the system is responsible for delivering it. This simple model has continued to expand over decades, eventually forming the foundation of today’s cloud infrastructure.
Conclusion — An Interface That Survived 50 Years
Looking back at everything we have discussed, a clear thread emerges. We began with a simple question: why do Docker logs use stdout? Following that question eventually led us back to the Unix I/O model. The Docker logging structure is not a completely new system—it is essentially an extension of the Unix standard output model at the platform level. The idea that a program writes data to stdout and the system processes that data dates back to the 1970s.
The reason this structure has survived to the present day is simple: it solves a sufficiently general problem. Programs take input and produce output. The system determines where that output goes. This separation of responsibilities does not easily break over time. In fact, as new technologies emerge, this simple interface becomes even more powerful. The Docker logging system works naturally in complex distributed environments precisely because of this simplicity.
Unix designers defined only how programs produce output. They left it up to the system and the user to decide how that output would be used. This design proved to be remarkably flexible. stdout can be redirected to a file, piped to another program, or transmitted over a network. And now, container platforms forward that same stdout to logging systems.
At the beginning of this series, we started with a small shell expression: 2>&1. That expression introduced us to the concepts of stdout and stderr. From there, we explored pipes and the process I/O model to understand how Unix turned programs into composable tools. Finally, through the Docker logging model, we saw that the same design is still in use within modern cloud infrastructure. And this leads us to a clear conclusion.
Unix’s small interfaces were simple—but it is precisely that simplicity that allowed them to scale over decades. Many of the systems we use today may appear to be entirely new technologies, but beneath the surface, the same Unix design philosophy still flows. And even a small concept like stdout has endured as part of that philosophy.