
The World Before Docker — Why Deployments Always Broke
One of the most strangely recurring phrases in software development was this: “But it works on my machine.” This sentence was not just a joke, but the most accurate expression of the structural problems embedded in development environments at the time. Developers would write code and run it successfully in their local environment without issues. However, the moment the same code was deployed to a server, unexpected errors would occur. This problem was not simply due to configuration mistakes, but rather stemmed from the fundamental separation between development and production environments. Differences in operating system versions, installed libraries, environment variables, and even subtle variations in file system structures could produce entirely different outcomes.
This problem could not simply be dismissed as a few developers making mistakes. In fact, as software systems became more complex, the issue appeared more frequently. As web applications increasingly relied on diverse libraries and frameworks, the number of conditions required to run a single application grew exponentially. Developers were forced to spend significant time not only writing code but also aligning the environment necessary for that code to run. This process was often documented in lengthy installation guides spanning dozens of pages, and within teams, the success of deployment often depended on how precisely these documents were followed.
The problem did not end there. Even when developers followed the same documentation, it was common for identical environments not to be reproduced. Minor differences in library versions, operating system patch levels, or even the order of dependency installation could lead to different results. This lack of reproducibility created persistent uncertainty for developers. Eventually, deployments began to fail more often due to environmental issues rather than code problems, becoming one of the primary factors slowing down development speed.
During this period, developers spent more time fighting the environment than writing code. Troubleshooting involved analyzing logs, comparing server and local environments, and aligning library versions repeatedly. What mattered most in this process was not purely technical knowledge, but experience and intuition—knowing which library might cause issues and which configuration might affect the system. In other words, deployment was less a systematic process and more an area dependent on the instincts of experienced developers. And it was precisely at this point that software development began to hit a fundamental limitation.

The Limitations of Existing Solutions — Why Virtual Machines Were Not the Answer
The first attempt to solve this problem was to replicate the environment itself. In other words, the idea was to recreate exactly the same environment as the production server on the developer’s local machine. This approach naturally led to virtualization technology. Tools like VMware and VirtualBox allowed multiple virtual machines to run on a single physical machine, each with its own independent operating system. Developers could now create a local environment identical to the production server and test their applications within it.
This approach certainly addressed many of the earlier issues. It reduced the differences between development and production environments and allowed applications dependent on specific operating systems or libraries to run more reliably. However, this solution introduced a new set of problems. Virtual machines were inherently heavy. Running a single application required booting an entire operating system along with all necessary components, resulting in images that were several gigabytes in size and required significant time to start. Managing multiple environments simultaneously demanded substantial system resources.
Furthermore, virtual machines were not well-suited for rapidly evolving development environments. Each time an application changed, developers often needed to rebuild or reconfigure the VM environment, which slowed down the development process. As microservices architecture began to emerge, where systems were split into multiple independently deployable services, VM-based approaches became increasingly inefficient. Managing dozens of virtual machines quickly became a significant operational burden.
In the end, virtualization solved one problem while exposing another limitation. Replicating the entire environment ensured stability but lacked flexibility and speed. Developers still needed a solution that was lightweight, fast, and capable of guaranteeing identical environments. At this point, a fundamental question resurfaced: was it truly necessary to replicate an entire operating system to achieve environmental consistency?

The Idea of Containers — A Technology That Already Existed but Was Hard to Use
The answer to this question had already existed. There was a way to isolate processes without replicating an entire operating system. This capability came from features provided by the Linux kernel. Technologies such as cgroups and namespaces made it possible to run processes in isolated environments, making them appear as if they were running on independent systems. This concept is what we now call containers.
Containers, unlike virtual machines, share the underlying operating system. This makes them significantly lighter and faster to execute. Since they only include the application and its required libraries, container images are small and can start almost instantly. In theory, this structure provided an ideal solution for ensuring identical environments between development and production. However, the challenge was that this technology was too complex for developers to use directly.
Early container technologies such as LXC existed, but leveraging them required a deep understanding of Linux systems. The setup process was complicated, and defining environments was not intuitive. In other words, the technology was there, but the tooling was not. Developers still had to manually configure environments, and in many cases, using containers was actually more difficult than traditional approaches.
At this point, what mattered was not the technology itself, but how easily it could be used. Containers were already a powerful concept, but they had not yet been transformed into something accessible to everyone. As a result, developers were still forced to choose between virtual machines and manual configuration, with no complete solution in sight.
And it was precisely at this moment that a turning point emerged. A tool appeared that restructured existing technology in a completely new way, making it practical and usable for developers. That tool was Docker.
The Emergence of Docker — What Was Different
As discussed earlier, the concept of containers already existed before Docker. The problem was that this technology did not function as a practical solution for developers. Handling containers directly required deep knowledge of the Linux kernel, and configuring environments remained complex and inconvenient. Ultimately, developers were stuck in a gap between “possible technology” and “usable tools,” still carrying the burden of unresolved problems. It was precisely at this point that Docker appeared.
Docker’s core innovation was not the creation of new technology, but the reconfiguration of existing technology in a fundamentally different way. The concept of the Dockerfile illustrates this transformation most clearly. Developers no longer needed to write lengthy documents describing how to set up an environment. Instead, they could define the execution environment with just a few lines of code. By specifying the base image, required libraries, and execution commands, Docker could automatically reproduce the exact same environment. At this moment, the environment was no longer dependent on human memory or documentation, but became a reproducible and fixed state.
Docker also introduced the concept of images as a portable unit of environment. Once created, an image behaves identically regardless of where it is executed. An application that runs on a developer’s local machine can run exactly the same on a server or in a cloud environment. The most important shift here was the disappearance of the idea of “matching environments” and the emergence of the idea of “bringing the environment with you.” This distinction was not merely about convenience—it marked a turning point that fundamentally changed the paradigm of software deployment.
Another key feature of Docker was its layered image structure. A Docker image is not a single monolithic entity but is composed of multiple layers. This structure allows systems to share a common base while adding or modifying only what is necessary. As a result, build times become faster and storage is used more efficiently. In other words, Docker did not simply standardize execution environments; it also provided a way to manage them efficiently.
In this way, Docker abstracted away technical complexity and allowed developers to focus on solving problems. By transforming the concept of containers into a usable tool, Docker set the stage for a deeper shift in how software is developed. This shift extended beyond tools and began to redefine the entire process of building and deploying software.
“Environment as Code” — How Docker Changed Development Practices
The most significant impact of Docker was not just technical efficiency, but the way it changed how developers perceive environments. Previously, environments were something that had to be manually configured and maintained. Developers followed installation guides, adjusted settings step by step, and investigated logs when issues arose. Docker completely inverted this process. Instead of manually configuring environments, developers could now define them in code and generate them automatically.
This shift had a profound impact on the entire development workflow. Developers could now version-control not only their application code but also the execution environment. It became possible to reproduce the exact environment of any point in time, which brought enormous advantages to debugging and testing. For example, reproducing a bug from the past no longer required rebuilding the environment from scratch. Running the corresponding Docker image would instantly recreate the exact same conditions.
This structure became even more powerful when combined with CI/CD pipelines. When code changes were made, Docker images could be automatically built, tested, and deployed. In this process, issues caused by environment inconsistencies were nearly eliminated. Development, testing, and production environments all ran on the same image, ensuring consistency across the entire pipeline. As a result, deployment transformed from a risky event into a repeatable and stable process.
Ultimately, Docker introduced a crucial concept: “the environment is code.” This idea goes beyond technical convenience and influences how software systems are designed. As environments became codified, the boundary between infrastructure and application began to blur. Developers were no longer just writing code; they were also responsible for designing the environments in which that code runs. This transformation laid the foundation for what would soon be recognized as DevOps culture.
The Realization of DevOps — When Docker Became Culture
The concept of DevOps existed long before Docker. The idea that development and operations should collaborate to deliver software faster and more reliably had been discussed for years. However, in practice, this concept was difficult to implement. Development and operations teams used different tools, operated in different environments, and had clearly separated responsibilities. The question of “who manages the environment” often became a source of conflict, and collaboration remained limited.
Docker began to fundamentally change this situation. As environments became defined in code, developers gained a clear understanding of how their applications would run in production. More importantly, they could deliver that exact environment directly to operations teams. Operations teams no longer needed to recreate environments from scratch; they simply had to run the images provided by developers. This naturally reshaped the boundaries of responsibility between the two teams.
This transformation extended beyond technical efficiency and began to influence organizational structure and culture. Deployment cycles became shorter, and it became possible to deploy multiple times a day. Rolling back changes became simpler, and new features could be tested more rapidly. In this way, Docker turned DevOps from an abstract philosophy into a practical and functioning system.
At this point, however, another challenge began to emerge. As container-based applications increased, managing them efficiently became a new problem. Instead of dealing with a single application, systems were now composed of dozens of containers running simultaneously. The question shifted to how these containers should be orchestrated and managed at scale. Docker itself did not solve this problem, but it was the catalyst that created it. And to address this new challenge, the next stage of technology would soon emerge—Kubernetes.
The Emergence of a New Problem — Containers Multiplied, and Management Became Necessary
The changes brought by Docker were extremely powerful, but those changes quickly gave rise to new problems. In the era when a single application ran on a single server, aligning environments was sufficient. However, as deployment became easier with Docker, developers began breaking applications into smaller pieces. Instead of one large system, it became natural to divide it into multiple smaller services. What is known as microservices architecture thus became a realistic choice.
The problem started from this point. As services were divided, deployment units also increased, and each service became an independently running container. At first, there were only a few containers, but as services expanded, their number grew rapidly. Now the problem was no longer “how to align environments,” but rather “how to operate dozens or hundreds of containers.” Running a single container was simple, but maintaining them reliably was an entirely different challenge.
Containers can fail at any time, network connections can break, and traffic can suddenly spike for a particular service. In such situations, manually managing each container becomes practically impossible. Developers were now placed in a position where they had to manage the state of the entire system, not just write code. In other words, Docker solved the deployment problem, but at the same time made operational complexity far greater.
This shift raised another critical question. Instead of running containers one by one, could the entire system be managed as a single unit? Could there be a system that automatically maintains service state, scales when needed, and recovers on its own when failures occur? Efforts to answer this question began, and in that process, a new tool emerged.
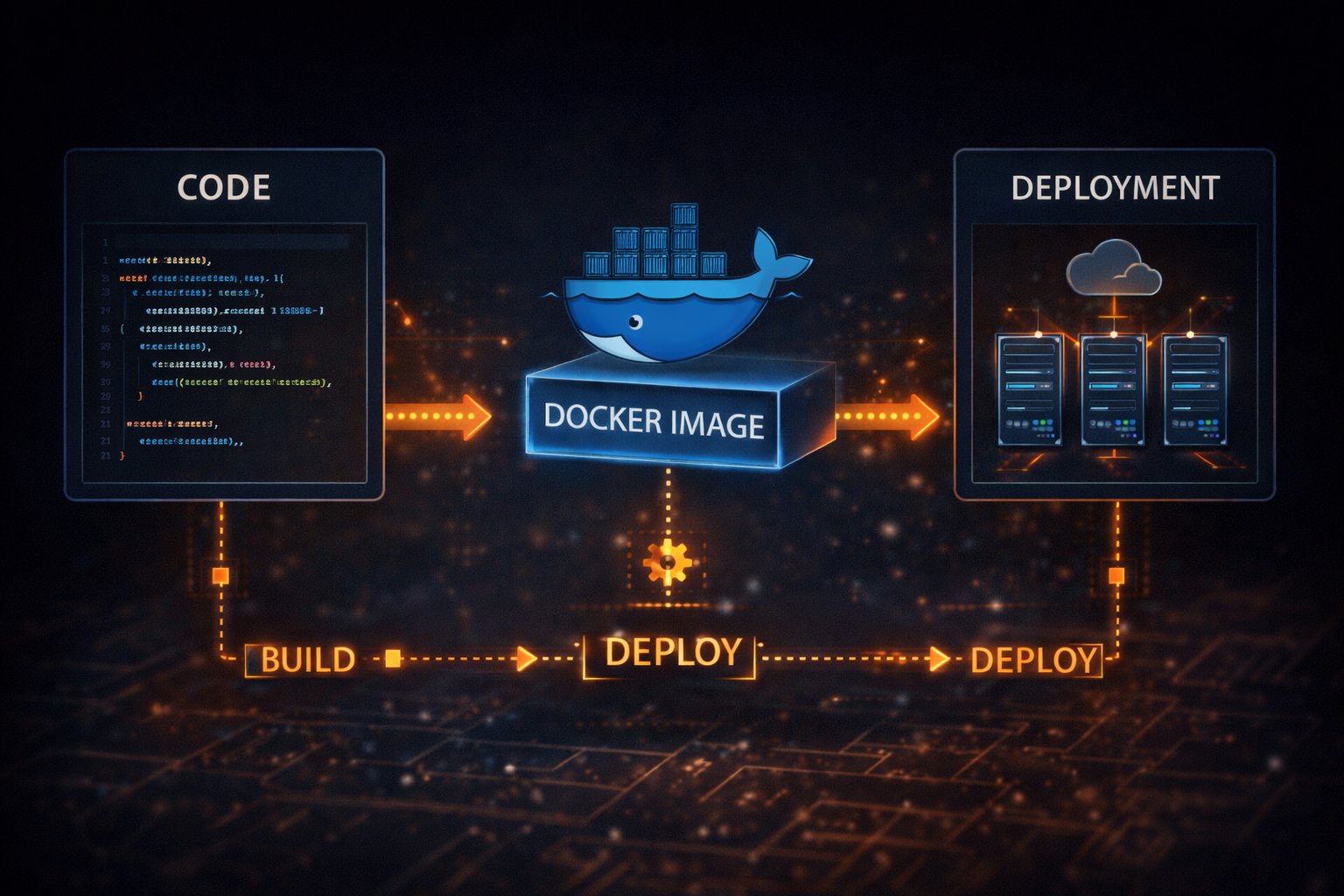
The Emergence of Kubernetes — The World After Docker
The most powerful answer to this problem came from Google. Google had already been operating a massive number of services internally and had built systems to manage them long before. One of the most representative systems was Borg. Borg was designed to automatically schedule applications, efficiently use resources, and recover from failures without human intervention. This concept was later released to the public and evolved into what is now known as Kubernetes.
Kubernetes was not simply a tool for running containers. It was a system for “managing containers.” Developers no longer needed to run specific containers on specific servers. Instead, they could declare a desired state, such as “I want this application to run in multiple instances,” and Kubernetes would ensure that the system maintained that state. This approach was fundamentally different from traditional command-based operations. Systems were no longer driven by instructions about what to execute, but by definitions of what state should be maintained.
This shift had a profound impact on operations. When a service fails, it is automatically recreated. When traffic increases, the system scales up automatically. When resources are no longer needed, they are scaled down. Additionally, Kubernetes handles networking between services, meaning developers no longer need to manage low-level infrastructure details. In this sense, Kubernetes not only solved the problems created by Docker but also introduced a new level of automation.
As a result, Docker and Kubernetes became a standard combination. Docker handled the packaging of applications, while Kubernetes managed their execution and lifecycle. This combination quickly became the industry standard and formed the foundation of most modern cloud environments. More importantly, this evolution did not just represent an advancement in tools, but a redefinition of how software is designed and operated.

The Birth of Cloud Native — The Era Where Infrastructure Became Code
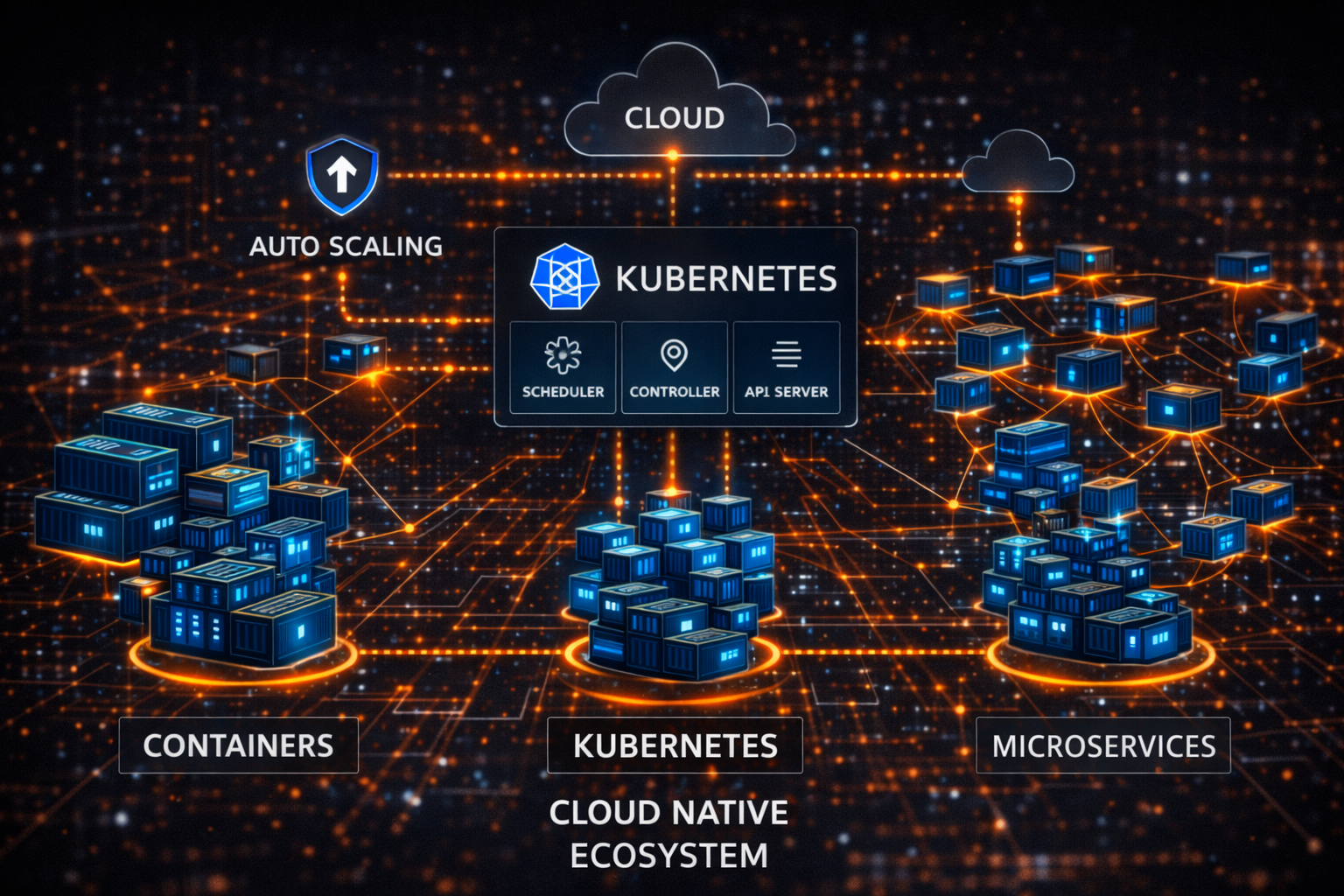
The combination of Docker and Kubernetes ultimately created a new paradigm known as Cloud Native. This concept does not simply mean using the cloud. It refers to designing applications from the ground up to be optimized for cloud environments, deploying them using containers, and building systems that assume automatic scaling and recovery. In other words, Cloud Native is not just a collection of technologies, but a fundamentally new way of thinking about software.
In this paradigm, the boundary between infrastructure and application almost disappears. Servers are no longer fixed resources but entities that are created and destroyed as needed. Applications are no longer tied to specific machines but run across clusters. Developers shift their focus away from “where something runs” to “what state the system should maintain.” This transformation fundamentally changes how software systems are designed.
Furthermore, in a Cloud Native environment, deployment is no longer a special event. Continuous deployment and updates become the default, and systems are constantly evolving. Failures are no longer treated as exceptions but as expected conditions. As a result, systems are designed not to avoid failures, but to withstand and recover from them. This philosophy requires a completely different approach compared to traditional system design.
Ultimately, the transformation that began with Docker was completed through Kubernetes and took shape as Cloud Native. This progression represents not just technological advancement, but a fundamental shift in how software is built. Most modern services already operate on top of this structure, and future technologies will continue to evolve along this path. Software is no longer just a program; it has become a continuously evolving system.
What Docker Left Behind — It Was Not a Tool, but a Paradigm
Following the flow we have examined so far, it becomes clear that Docker represents far more than just a tool that makes containers easier to use. At first, it appeared as a solution to reduce the gap between development and production environments, but its impact extended far beyond that scope. Docker made software deployment faster, environments more stable, and blurred the boundary between development and operations. However, what matters more is that Docker changed the way developers perceive software itself.
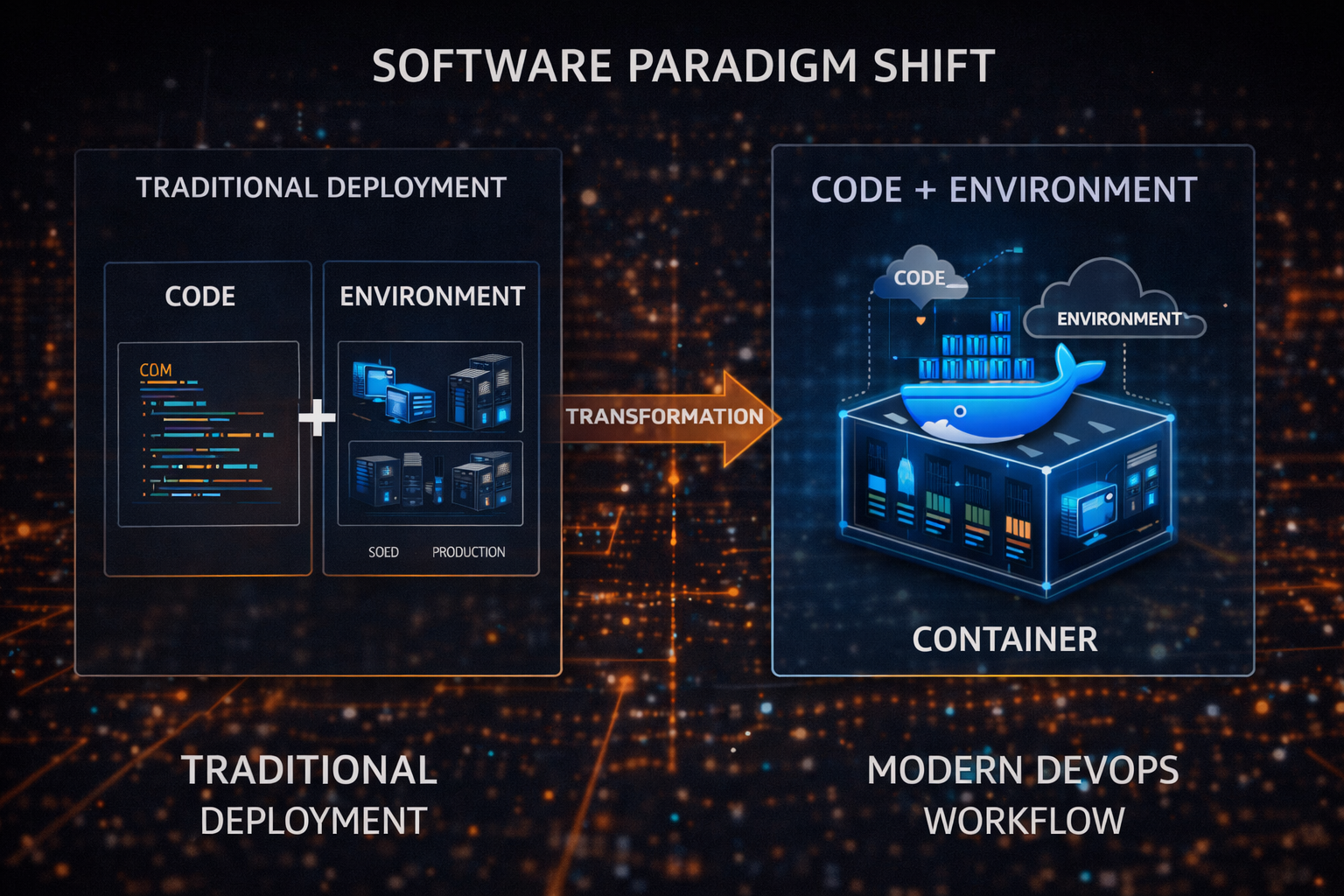
Previously, software existed in a state where code and environment were separated. Code was managed through version control systems, but environments relied on documentation and experience. There was always uncertainty between these two domains, and as a result, deployment was perceived as a risky operation. Docker fundamentally transformed this structure. As environments became defined in code, software was no longer just code but began to be managed as a fully executable state. This shift was not merely a matter of convenience; it redefined the fundamental unit that composes software.
This transformation naturally led to the concept of Infrastructure as Code. Infrastructure was no longer something manually configured by humans, but something defined in code and automatically provisioned. Docker was the starting point of this movement, and many tools and platforms that followed evolved on top of this concept. The modern reality where servers are created in the cloud, networks are configured, and storage is connected—all through code—is a direct extension of the changes initiated by Docker.
Docker also changed how we think about development speed. In the past, deployment was slow and risky, so the best strategy was to do it as infrequently as possible. However, the combination of Docker and CI/CD transformed deployment into a fast and repeatable process. As a result, software began to be deployed more frequently and evolved more rapidly. This shift was not just a technical improvement; it influenced product development methods and organizational structures. An environment that allows rapid experimentation and iteration made it easier to validate new ideas, ultimately leading to faster innovation.
Another significant impact of Docker was standardization. As development, testing, and production environments all began to operate on the same image, concerns about environmental differences gradually disappeared. This standardization made collaboration significantly easier. Even when a new developer joined a project, they could use the exact same environment simply by running a Docker image, without going through complex setup procedures. In this sense, Docker not only solved technical problems but also transformed the way teams collaborate.
When all of these changes are considered together, it becomes evident that Docker started as a tool but ultimately became a paradigm. While container technology existed before, Docker made it accessible and practical for everyone, thereby redefining the standards of software development. Developers no longer see themselves as tied to specific environments but instead take it for granted that applications should run consistently anywhere.
And this transformation does not stop here. On top of the standard that Docker established, Kubernetes emerged, and from there, a new world called Cloud Native was formed. Software is no longer just a program that runs—it has become a system that continuously scales and evolves. In this flow, Docker was both the starting point and a critical turning point that continues to influence the present.
In the next article, we will continue this journey by examining how Kubernetes, the technology that completed the post-Docker world, redefined the cloud. By following how Kubernetes solved the problems created by Docker and what new standards emerged as a result, the structure of modern cloud infrastructure will become much clearer.