
Why the Choice to Not Build a Server Felt Natural
When first designing Readium, the initial assumption was simple. Avoid building a server if possible. This decision was not so much a technical challenge as it was an attempt to eliminate unnecessary complexity. When looking at the problem of reading records, most of the data belongs to the individual user. What books were read, when they were read, and how far they were read are not pieces of information that need to be shared externally. From this perspective, a server does not appear as something that expands functionality, but rather as something that increases the burden of management. The moment authentication, data storage, synchronization, backup, and security come into play, the scope of the problem expands rapidly. So at the beginning, the intention was to deliberately exclude all of these concerns. The starting point of the design itself was “do not build a server.”
This judgment was not based on pure idealism, but on a structure that was actually implementable. Mobile devices had already become sufficiently powerful, and by using a local database, most states could be managed entirely within the device. In particular, a SQLite-based structure was already a proven choice in terms of stability and performance. An application that works without a network clearly offers advantages in terms of user experience. Even when the connection is lost, records remain, input is not blocked, and the app continues to behave consistently. These characteristics align well with the act of reading. Reading happens anytime and anywhere, and an experience that does not depend on network conditions feels more natural. As all these conditions aligned, the conclusion that “removing the server is the right decision” gradually solidified into certainty.
The problem was not that this judgment was wrong, but that it felt too natural to be questioned. There was a moment when it shifted from “not building a server” to “believing that a server is unnecessary.” This difference may seem small, but it becomes decisive at the point where the design begins to collapse. At the time, this choice felt like a more refined design. It removed unnecessary layers, clarified data ownership, and kept the system simple. However, this simplicity only holds under certain conditions. The moment those conditions are not clearly defined, and only the conclusion “a server is not needed” remains, the design is already vulnerable.
At this point, what matters is not what was built, but what was excluded. Choosing to remove the server is not just about reducing components, but about redefining the scope of problems the system must solve. But that redefinition was incomplete. Some problems disappeared, but others had simply not yet appeared. And those problems would soon surface.
What the Local-First Architecture Actually Solved
Instead of removing the server, the chosen structure was a local-first architecture. This structure is not merely about storing data locally, but about shifting the center of the system into the device itself. In Readium, all core data structures exist within the local database. Reading state, session records, and timeline events are all created and stored within the device. The network is only an optional element, not a required component. This structure is simple yet powerful. The app maintains a consistent state at all times, and its functionality is not constrained by external environments.
The effectiveness of this structure was repeatedly confirmed during implementation. Starting and ending a reading session can be fully handled without any network requests. Even if the user closes the app while reading, the state is restored exactly as it was when reopened. The timeline is also constructed purely from local events, without synchronization with a server. All of these flows are reflected immediately without delay, resulting in a much more natural experience for the user. Since there is no need to wait for network requests, interactions are never interrupted. At this stage, the local-first strategy did not just seem like a choice, but like the correct answer.
In particular, managing both state and events locally carries significant architectural implications. In a serverless structure, there is no need for complex synchronization logic to maintain data consistency. There is no need to resolve conflicts, nor to design retry strategies for network failures. The system becomes much simpler, and the scope of problems is reduced. This simplicity accelerates development and reduces maintenance overhead. As a result, this structure continued to reinforce confidence. The belief that “this app can be fully completed without a server” naturally took shape.
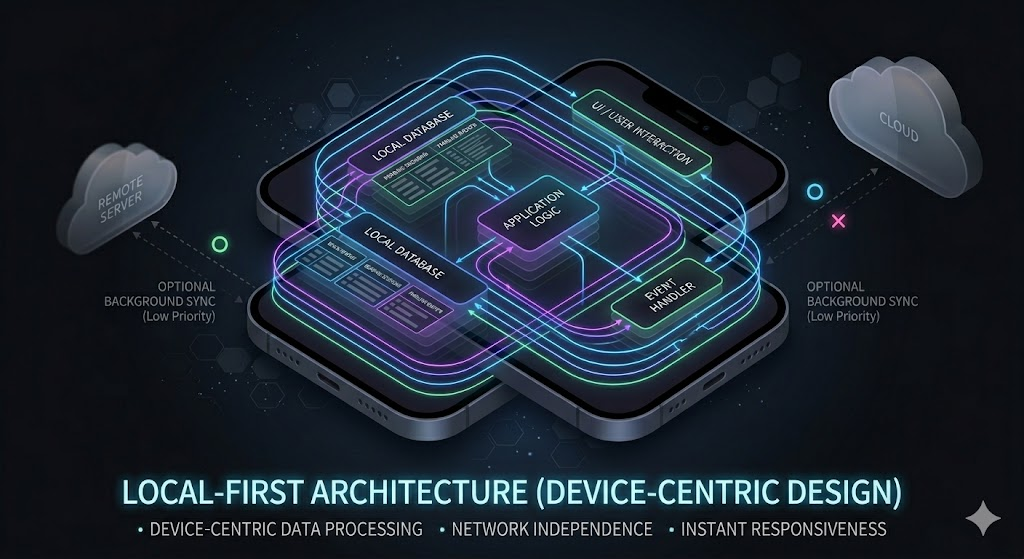
However, the problem begins the moment the boundary between what this structure solves and what it does not solve is not clearly distinguished. Local-first provides an answer to “where should data be stored,” but it does not answer “where should data come from.” This distinction is not apparent at first. As long as the app operates only on data it already has, there is no issue. But the moment the user tries to input new data, the limitations of this structure begin to emerge.
At this stage, the design had not yet collapsed. It even appeared close to completion. But that sense of completeness was built on certain conditions. The problem was that those conditions had not been clearly defined. And those conditions would be broken by a very simple user action.
The First Crack: The Problem of “Choosing a Book”
In order to record a reading activity, there is a prerequisite step that must occur. The user must choose which book they are reading. This step is so obvious that it is not initially recognized as part of the design. The user enters a book title into a search field and selects one from the list. A cover image is displayed, along with the author and publisher information. This experience has been repeated across countless services, so it is accepted without much thought. The problem is that this familiar experience cannot be created using only local data.
When the app is first launched, there is no book data available. In order to display results based on the user’s input, the corresponding data must exist somewhere. But the local database does not contain this information. If the user has previously read the book, some data might remain, but the moment a new book is searched, this structure offers no help. It is at this point that the first gap in the design becomes visible. The local-first structure is powerful when dealing with already existing data, but it provides no answer for creating or retrieving data that does not yet exist.
This problem cannot be solved simply by adding a single feature. Book metadata contains a vast amount of information and is continuously updated. Collecting and managing data for millions of books is beyond the scope of an individual project. In other words, this is not a question of “how to implement it,” but “who has this data.” And the answer is clear. It already exists externally.
At this moment, the focus of the design shifts. Until now, the central question had been “how to record.” Now it becomes “what data should be used to start the recording.” This change may seem small, but it alters the boundary of the system. A structure that was previously closed within internal data now transitions into one that depends on external data. This transition is the first crack.
This crack does not immediately collapse the system. Instead, it naturally leads to the next decision. Use an external API. By leveraging an already existing database, the problem can be easily solved. This judgment is not wrong. But the fact that this choice introduces another problem only becomes visible in the next stage.
The Moment of Confronting the Reality of External Book APIs
After recognizing the problem of book metadata, the available choices were simpler than expected. This was because leveraging already existing data was the most realistic approach. Services such as Kakao Books API or Google Books API have already built massive book databases, and with a simple search request, they return information such as cover images, authors, publishers, and ISBNs. These APIs are not merely convenience features, but are in fact closer to “the only viable solution for services that do not own data.” A structure where an individual collects, refines, and continuously updates such data is not sustainable in terms of maintenance cost. Therefore, using external APIs was not a choice, but a decision that was almost inevitable.
At this stage, the design still does not appear to be significantly shaken. The local-first structure remains intact, and the external API is simply added as a “tool for fetching data.” The mobile app can directly call the API, receive the response, and display it on the screen. This approach is simple to implement and does not significantly conflict with the existing structure. The app continues to operate centered around local data, and the external API only assists with initial input. At this point, the overall structure even appears more complete. It feels as though a missing piece of the puzzle has been filled.
However, there is an important assumption hidden within this decision. It assumes that a structure relying on external APIs is safe and sustainable. On the surface, this assumption does not seem problematic. Most sample code and tutorials also demonstrate calling APIs directly from mobile applications. In the early stages of development, this approach is the fastest and most intuitive. In practice, it is also not difficult to implement. You send an HTTP request and parse the JSON response. This simplicity actually obscures the problem. Despite the existence of structural risks, the ease of implementation hides those risks from view.
At this point, the design has not yet collapsed. It continues to flow naturally. Placing an external API on top of a local-first structure is intuitive and accelerates development. However, this structure accepts one assumption without any verification. That assumption is the question: “Is it acceptable for the client to directly call external APIs?” This question soon rises to the center of the problem.
The Problem with Calling APIs Directly from Mobile
A structure where a mobile app directly calls an external API appears to have no issues at first. You obtain an API key, include it in the request header, and the data is returned correctly. However, this structure inherently contains a vulnerability. The API key is embedded in the client. This key may be just a simple string, but it represents access rights to the entire service. And this string is easier to expose than expected. Extracting the key is not difficult through methods such as analyzing the APK file or capturing network traffic.
This problem does not end at the level of a simple security vulnerability. The exposure of the API key means that the origin of requests can no longer be controlled. If someone obtains this key, they can call the API directly without going through the app. The number of requests may increase, and once usage limits are reached, the API provider may block the key. In severe cases, the service itself may be disrupted. In other words, this structure is one that will inevitably break at some point. It is not merely a possible issue, but something closer to a matter of time.
More importantly, this problem is not one that can be resolved through technical measures alone. Code obfuscation or network encryption does not provide a fundamental solution. Any information embedded in the client will eventually be exposed externally. In this structure, the API key is an “asset that cannot be protected.” And building a system that depends on an unprotectable asset is a flawed design choice. At this point, it can no longer be viewed as an issue of implementation. The conclusion is reached that the structure itself is wrong.
The moment this problem is recognized, the previously smooth flow of design comes to a halt. The approach of layering an external API on top of a local-first structure can no longer be maintained. Data must be fetched from external sources, but the path cannot be the client. This contradiction cannot be resolved through simple modifications. It reaches a point where the design itself must be redefined.
The Collapse of the Design: It Was Not About Removing the Server, but Redefining It
At the beginning, the goal was to avoid building a server. However, this goal could no longer be maintained when confronted with the reality of external APIs. The issue was not that a server had to be added, but rather “how the role of the server should be defined.” Simply introducing a traditional backend system was an excessive choice. A conventional server that stores user data and processes business logic does not fit this structure. The core data of Readium must still remain local, and the server must not intrude upon that structure.
At this point, the design changes direction. Instead of removing the server, it is redefined with a strictly limited role. The server does not hold state. It does not have a database. It does not store user information. Instead, it performs only one role. It calls external APIs on behalf of the client and securely delivers the results. This role may appear small, but structurally it carries significant meaning. It creates a boundary between the client and the external world.
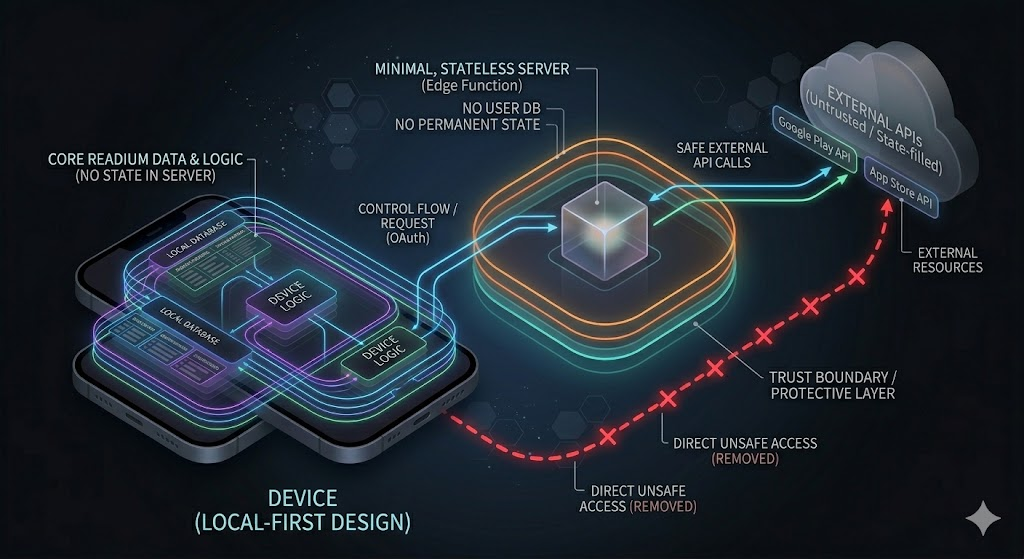
This server is not just a simple proxy. It goes beyond relaying requests and defines the boundary of the system. The API key no longer exists in the client, but is managed only within the server. The client does not directly depend on specific external APIs, but uses only the interface provided by the server. This structure does more than just strengthen security. It reduces the coupling of the entire system. Even if external APIs change, the client remains unaffected.
This change is not merely an adjustment at the level of “adding a server.” The center of the design has shifted. If the initial goal was to remove the server, the focus now becomes how to define boundaries. The server is no longer the center of the system, but a minimal mechanism for maintaining boundaries. At the moment this transition occurs, the local-first strategy is redefined into a more stable form. It becomes clear that the true goal was not to eliminate the server, but to control the scope of its influence.
Backend as a Protective Layer
After redefining the role of the server in the direction of minimizing it, the structure begins to take shape more clearly. The mobile app no longer calls external Book APIs directly. Instead, it calls the Readium Backend, which has a single fixed endpoint. The server receives this request, internally calls the external APIs, processes the result, and then returns it to the client. On the surface, this may look like simple mediation, but in reality, this is where the separation of responsibilities within the system occurs. The client no longer needs to be aware of the existence of external APIs, and the server absorbs any changes in those external APIs internally.
This structure does more than simply strengthen security. By breaking the direct connection between the client and external APIs, the coupling of the system is significantly reduced. For example, even if the response structure of a particular API changes or the service is discontinued, the client code does not need to be modified. Adjustments can be made solely within the server. Additionally, this structure naturally provides a foundation for expansion into combining multiple APIs. Even if only one API is used initially, it can later evolve into a system that sequentially calls multiple APIs or merges results from different sources. All of these changes are handled transparently from the client’s perspective.
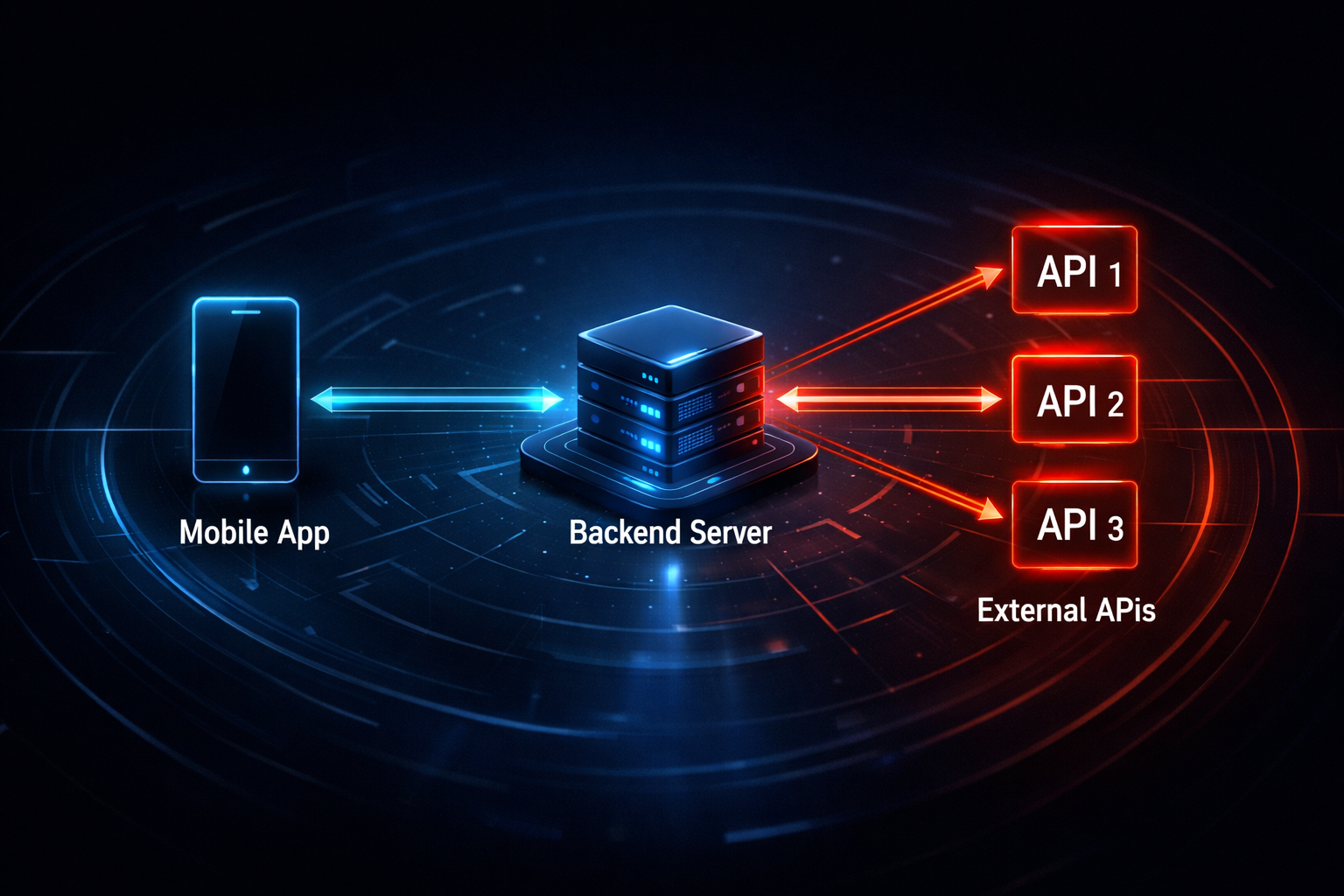
At the code level, this structure can be simplified into the following flow:
Client → Readium Backend → External APIsThis representation is simple, but it carries important architectural meaning. A constraint is introduced where all external requests must pass through the Backend, and this constraint itself creates system stability. The API key exists only within the server, and the client has no knowledge of it. Since the form of requests is controlled by the server, the usage pattern of external APIs can also remain consistent. Ultimately, this Backend is not just a relay layer, but becomes a protective layer that simultaneously handles security and abstraction.
At this point, the server is no longer something that “should be removed.” Instead, it becomes a structural component that is necessary to maintain system stability. However, its role is still limited. It does not store data and does not hold state. It performs only the role of maintaining boundaries. Because of this limitation, the server does not grow or become complex. And this characteristic continues to influence subsequent decisions.
Why Fastify Instead of Express
As the role of the server becomes clear, the choice of technology stack also naturally narrows. This server does not process complex domain logic. It has no database and does not manage state. It simply receives requests, calls external APIs, and returns the results. This simplicity changes the criteria for choosing a framework. In a typical backend system, ecosystem size or extensibility may be important, but here, lightness and a predictable structure are more critical.
In the Node.js environment, the most widely used framework is still Express. It has long been considered a de facto standard, with abundant resources and examples available. However, Express does not enforce structure due to its flexibility. In smaller projects, this flexibility can actually harm consistency. If the shape of requests and responses is not clearly defined, the code gradually becomes loose and difficult to maintain. The Readium Backend is small in scale, but its structure needed to be clear.
At this point, Fastify appeared to be a more suitable choice. Fastify allows defining requests and responses based on schemas, and validation and serialization are automatically handled based on those schemas. This is not just a convenience feature, but a mechanism that firmly defines the server’s interface. Because the contract between the client and server is expressed at the code level, it becomes easy to identify the impact scope when changes occur. Additionally, its internal JSON serialization performance is very fast, reducing unnecessary overhead even in simple request handling.
Its integration with TypeScript was also an important factor. When schemas are defined, request and response types are automatically inferred, eliminating the need to repeatedly define types separately. Even for a small server, type safety remains important. In fact, the simpler the structure, the more easily the entire flow can collapse when types break. Fastify naturally compensates for this. Ultimately, this choice was not about “wanting to use a new technology,” but about selecting the tool that best fits the current structure.
This decision also influences how the server evolves in the future. Because the structure is clearly defined, even when new features are added, the existing interface can be easily maintained. And this consistency directly contributes to the overall stability of the system. In the end, choosing a framework was not merely a matter of technical preference, but a decision that extended from the design itself.
A Choice to Not Operate Servers: Cloud Run
After constructing the server, the remaining question was “how to operate this server.” The moment a server exists, a new responsibility called operations arises. Managing a VM directly requires handling operating system updates, security patches, log management, and scaling. All of these tasks are separate from application development, yet they continuously demand time in practice. In a personal project, this burden accumulates quickly. When the cost of maintaining the server exceeds that of developing features, the project naturally comes to a halt.
To avoid this problem, Cloud Run was chosen. Cloud Run is a serverless platform that operates based on container images. Developers only need to create and upload a Docker image, and the platform automatically handles execution and scaling. The core of this structure is request-based execution. Containers run only when requests come in, and when there are no requests, no resources are used. In other words, the server exists, yet at the same time, it can remain in a state of non-existence.
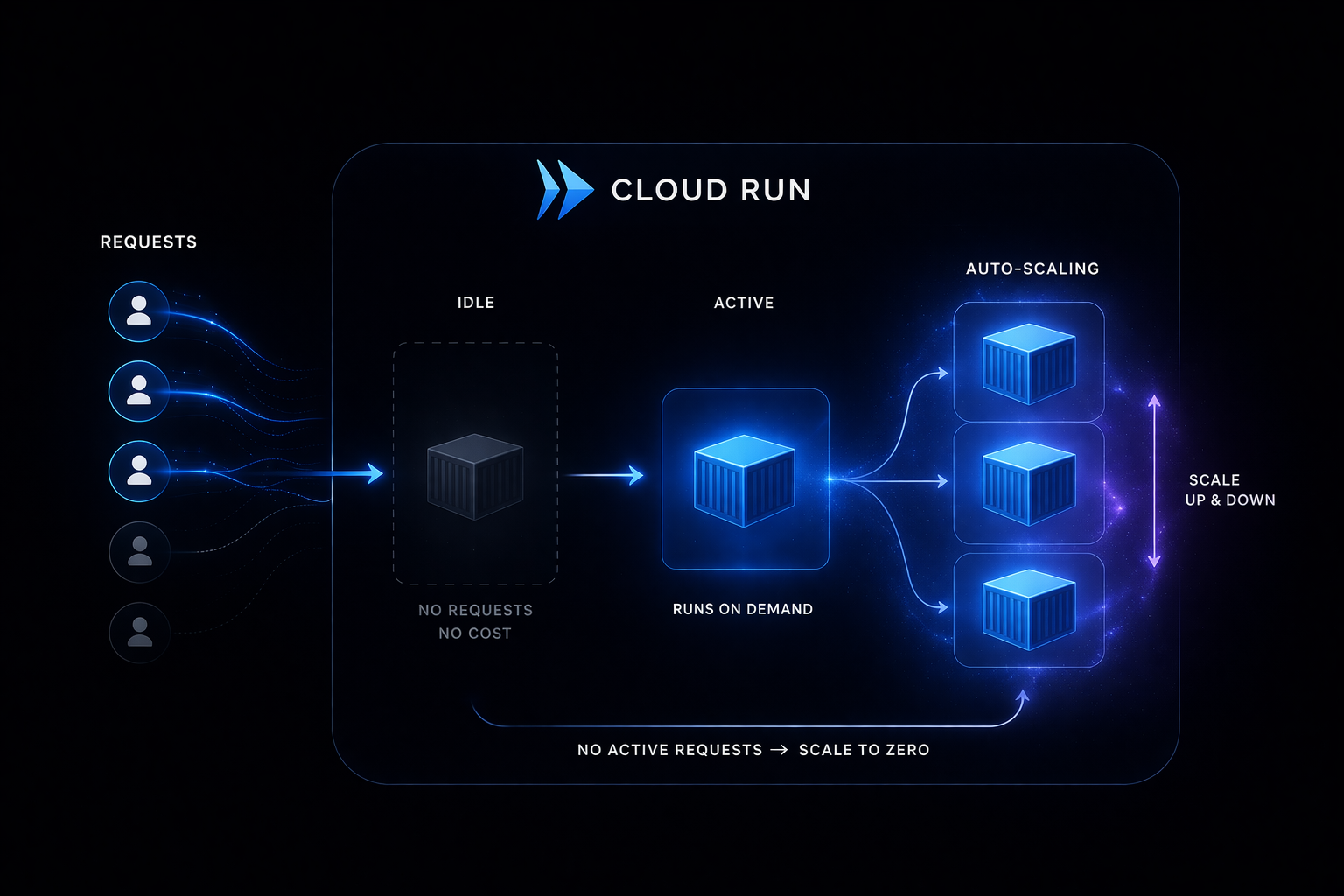
This approach aligns well with the characteristics of the Readium Backend. When traffic is low, costs are almost nonexistent, and resources are used only when needed. Additionally, since there is no need for direct server management, developers can focus solely on application code. This is not just a matter of convenience, but is directly tied to the sustainability of the project. The less operational burden there is, the more time can be spent on feature development and structural improvements.
This choice is also a design decision. It is a decision to have a server, but not to operate it. A physical server exists, but it is excluded from the domain of management. This approach does not conflict with the local-first strategy. The server still performs only a minimal role, and the infrastructure is also kept minimal. In the end, Cloud Run is not just a deployment environment, but another structural choice made to minimize the presence of the server itself.
Authentication as the Second Boundary: Firebase Authentication
Even after introducing the server, the structure was not yet complete. While the issue of protecting external API keys had been resolved, another question naturally followed. Who is allowed to use this server? If the API is exposed without any restrictions, this server would no longer function as a protective layer but would instead become a public proxy that calls external APIs on behalf of anyone. If someone discovers this endpoint and begins sending arbitrary requests, the server would end up handling unintended traffic. Eventually, this leads back to the same outcome as before. API usage increases, limits are reached, and the entire service becomes affected.
At this point, the server must go beyond simply “forwarding requests” and take on the role of determining the origin of those requests. In other words, the server must now handle two boundaries simultaneously. One is the boundary that protects external APIs, and the other is the boundary that protects the server itself. The solution chosen to establish this second boundary was Firebase Authentication. The mobile app performs user authentication through Firebase, and once authentication is complete, it receives an ID Token. This token is not just a simple string, but signed data that can identify a specific user and session.
When the server receives a request, it also receives this token and processes the request only after verifying it. This process goes beyond simply checking whether the user is logged in. It becomes the basis for determining whether the request originated from the actual app and whether it was generated by a valid user session. Through this structure, the server is no longer an endpoint open to everyone, but an interface that can only be accessed within a restricted scope.
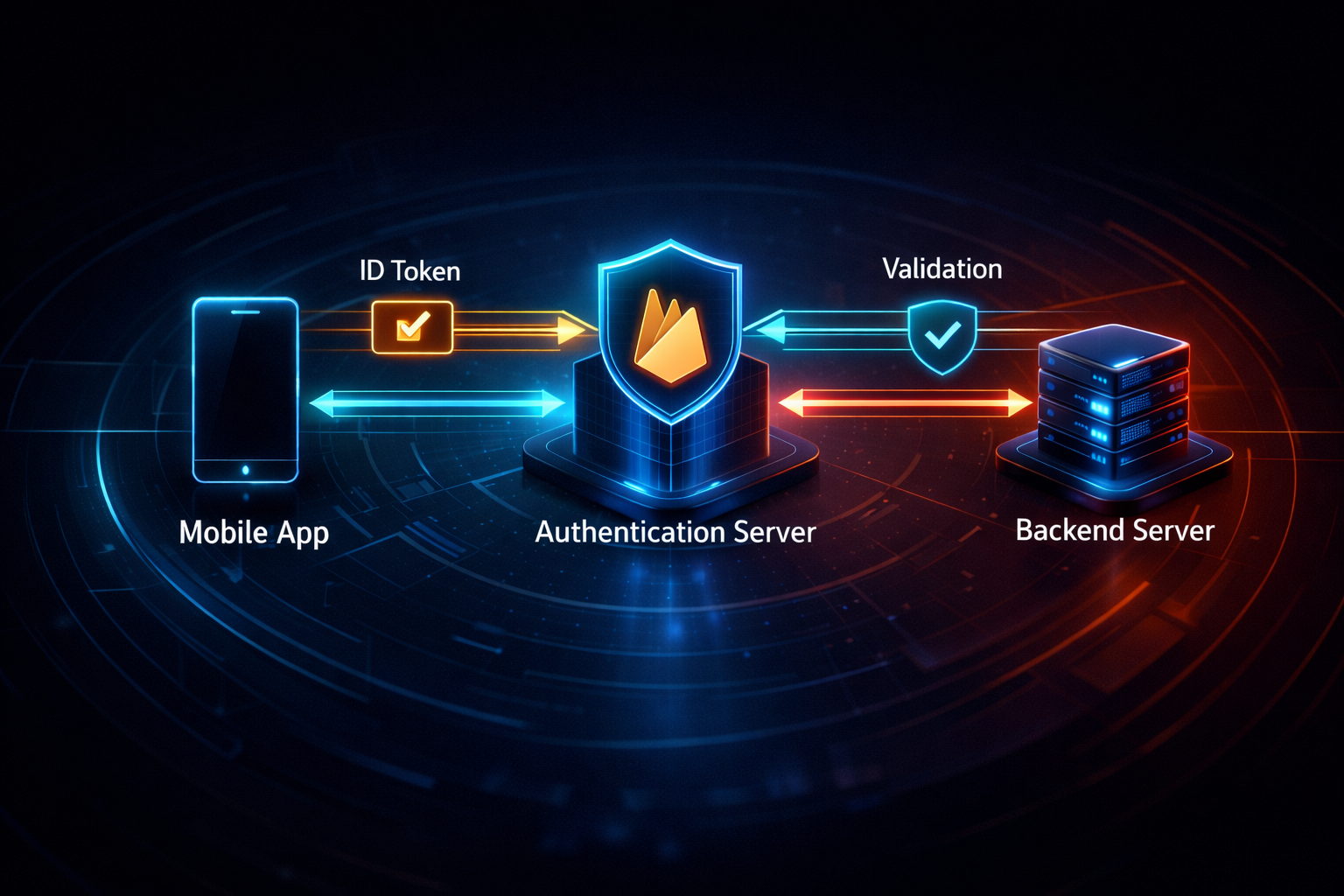
This decision carries structural significance. The server evolves from a simple protective layer into a gateway that simultaneously handles security and request control. Protecting external APIs alone was not sufficient; the server itself also needed protection in order for the entire system to remain stable. With this second boundary in place, the Backend finally takes shape as an independent system.
Why This Server Is Small but Important
The Readium Backend constructed in this way is very small in scale. It has no database and no complex domain logic. The types of requests it handles are also limited. However, when viewed structurally, the importance of this server exists on an entirely different level than its size might suggest. This server is not the center of the system, but rather defines the boundaries of the system. And these boundaries determine the stability of the entire structure.
The client no longer connects directly to external APIs. All requests are routed through the server, which validates and processes them. In this process, security, request control, and API abstraction are all handled simultaneously. Even if external APIs change, the client remains unaffected, and unauthorized requests are blocked at the server. Additionally, combining or replacing multiple APIs can be handled entirely within the server. All of these changes remain transparent to the client.
From a system-wide perspective, this server functions more like a gateway than a traditional backend. The data still resides locally, and the server does not own any data. Instead, it controls the connection points with the outside world and manages all incoming requests into the system. This role is not immediately visible, but structurally, it is one of the most critical components.
Ultimately, this server is defined not by its size, but by its role. It is not simple because it is small; it remains small because its role is deliberately constrained. And this constraint is the key factor that stabilizes the structure. At this point, it becomes clear that it is more important to define the server in such a way that it does not need to grow, rather than trying to prevent it from growing after the fact.
Redefining the Design: It Is Not About Eliminating the Server, but Reducing the Boundary
The initial goal when designing Readium was clear. Avoid building a server as much as possible. This goal was partially maintained, but it was not realized exactly as intended. Instead, it was redefined into a completely different form. Rather than eliminating the server, the structure shifted toward limiting the server’s role as much as possible. This change was not a compromise, but a natural result of a deeper understanding of the design.
Attempting to completely eliminate the server may seem ideal, but in real systems, a boundary with the external world is always necessary. Data can remain internal, but not all inputs and outputs can stay within the system. The moment external data is involved, the more important question becomes how to define that boundary. In Readium, the server remained as the minimal mechanism responsible for that boundary. It was possible to add more roles to the server, but this was intentionally avoided.
This decision ultimately strengthens the local-first strategy. What matters is not the absence of a server, but that the server does not intrude upon core data. Data ownership remains with the client, and the server only handles issues that arise externally. This structure is both simple and extensible. If necessary, the server’s role can gradually expand, but the fundamental boundary remains intact.
At this point, the discussion returns to the original question. Is a server necessary? The answer is no longer simple. A server may or may not be necessary. What matters is not its existence, but the role it plays. The Readium Backend represents one answer to that question. It is not about removing the server, but about redefining what the server means.
And on top of this structure, another problem emerges. Is a system that depends on a single API truly stable? How should failures in search be handled, and how should different data sources be combined? These questions still remain. In the next article, we will explore in more detail the Provider and Fallback strategies introduced to address these issues.
Next Step: Is One API Enough?
Based on the structure so far, the Readium Backend appears to have reached a sufficiently stable form. External API keys are securely protected within the server, and the client no longer directly depends on external services. Through authentication, the origin of requests is controlled, and the server maintains the boundaries of the entire system while performing only a minimal role. Looking at this state alone, the design feels as though it has been fully organized. In practice, when using a single Book API, the system operates without major issues. A search request returns results, and the user can select one of them to begin recording their reading activity.
However, this structure still maintains one underlying assumption. It assumes that a specific external API will always return correct results. At first, this assumption is rarely questioned. Most searches work normally, and for common book titles, sufficiently accurate results are provided. But the situation changes as soon as the user attempts slightly different forms of input. When a book title is entered only partially, contains typos, or when data is insufficient depending on language or region, search results may be empty or inaccurate. This is not merely an edge case, but a factor that continuously disrupts the actual user experience.
At this point, another question emerges. Is a structure that depends on a single API truly stable? External APIs are systems beyond our control. Response formats may change, services may temporarily go down, or certain data may be missing. Up to now, the dependency has been “hidden” through the server, but the dependency itself has not been reduced. In other words, the structure has become safer, but it is still tied to a single point of failure.

This problem cannot be solved simply by adding another API. The moment multiple APIs are introduced, a new design is required. Decisions must be made about the order in which APIs are called, how results are combined, and what strategy should be used when failures occur. In other words, the concept of a “search strategy,” which was not considered in a single API structure, now emerges. This strategy is not just an implementation detail, but is directly connected to user experience. The quality of the application depends on which results are shown first and how failures are handled.
Ultimately, at this point, the structure expands once again. The server is no longer just a layer that forwards requests, but also takes on the role of selecting and combining multiple data sources. However, this expansion does not occur in the same way as before. Instead of arbitrarily increasing the server’s responsibilities, it proceeds by layering a new strategy on top of the existing concept of a protective layer.
The next article will address this exact point. It will explore how multiple Book APIs can be integrated into a single search experience, and how to design a structure that assumes failure as a given. Through the abstraction of Providers and the introduction of a Fallback strategy, we will examine in detail the process of moving away from dependency on a single API.