
Even when validation is not complete, we stop

Right after deployment, a screenshot of the error rate graph is posted in the team channel. The error spikes that had been occurring consistently just a few hours ago have noticeably decreased, and the person in charge says, “It seems stabilized for now,” based on that graph. The people in the meeting each check their dashboards again, zoom into the same time window, and confirm that the change is real. At that moment, someone says, “Isn’t this good enough?” and no one objects. No one checks which cases have disappeared, whether the disappeared errors were actually resolved, or whether they have simply moved to a different path. It is not that the state is unchecked, but rather that it is judged to be a state that does not need to be checked. That judgment quickly leads to the next task, and the change is recorded as “effective.” In that process, missing input conditions or unreproduced cases are no longer addressed, and the remaining issues are treated as if they do not exist.
This scene is familiar. Improved metrics are shared immediately, the shared metrics replace judgment, and that judgment functions as a signal to end validation. The choice to check only part of the system instead of the whole is repeated, and that choice appears reasonable every time. There is always not enough time to verify all cases, and the pressure to show results is always present, so validation does not end—it gets cut off. Once cut off, validation is never resumed, and subsequent changes accumulate on top of that state. From this point on, the system no longer has a “confirmed previous state,” and the baseline for comparing what has changed disappears as well. It is not that validation has stopped, but that the stopped state is approved as the standard.
We are not finishing validation, we are approving the moment at which we stop
Without a comparison baseline, change cannot be interpreted
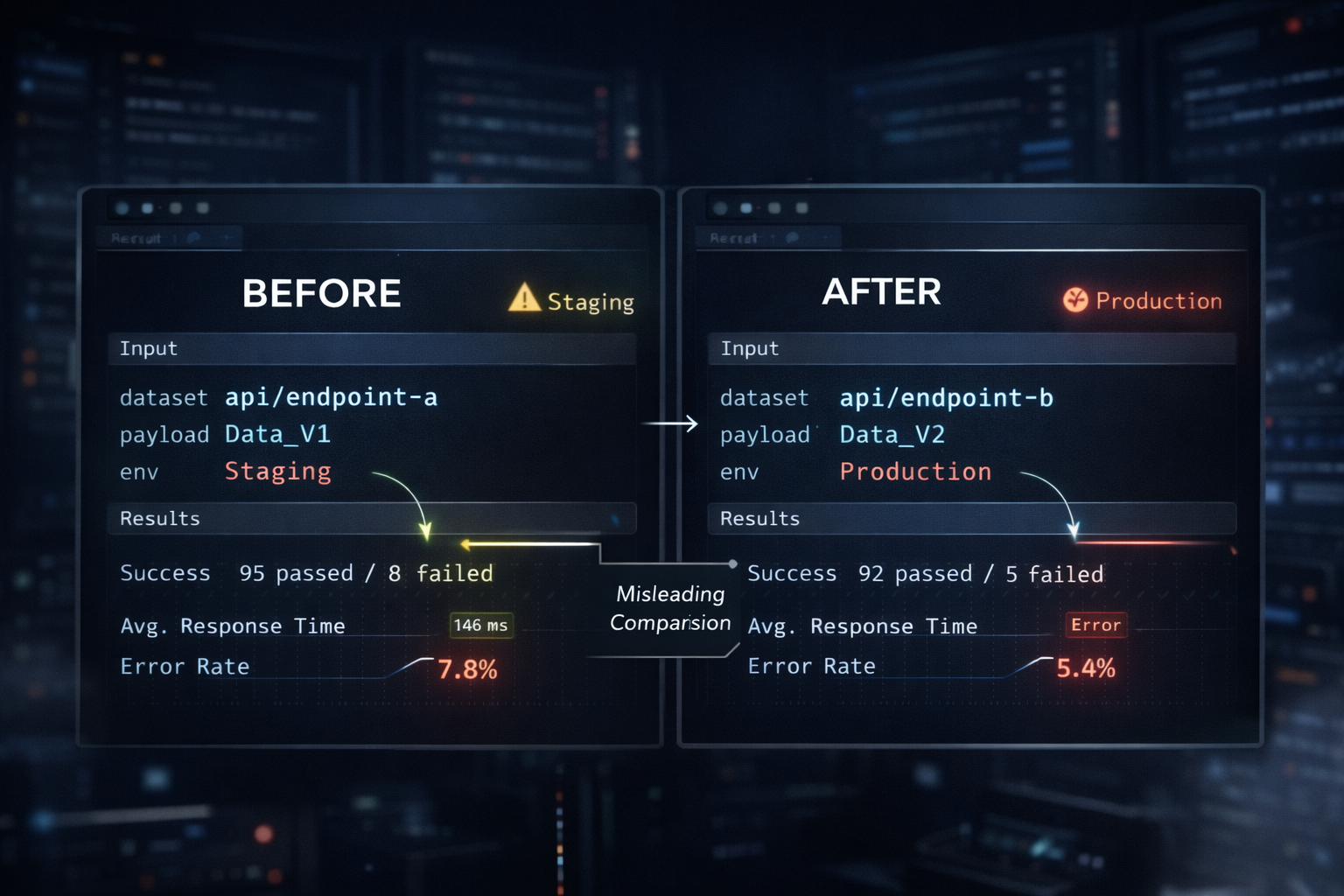
A few days later, a similar issue is reported again. This time, the response time for a specific request has become abnormally long. The person in charge immediately modifies the code and repeatedly calls the same request a few times. A case that previously failed now returns a normal response, and he captures the result and shares it. With the statement “It works now,” the change is deployed, and the issue is treated as resolved. However, that test was not conducted under the same conditions as before. The request parameters are partially different, the execution environment already reflects other changes, and there is no record of repeatedly executing the exact same input. Under what conditions it failed before, and under what conditions it succeeds now—those differences are not verified. Because there is no baseline to verify against, the act of verification itself is omitted. Only the result remains, and there is no baseline to interpret that result.
This pattern also repeats. A single case of “something that didn’t work now works” is quickly shared, and that case is accepted as evidence of change. Maintaining comparisons under identical conditions becomes increasingly difficult, and the cost required to preserve those comparisons is naturally eliminated. If the environment is not fixed, inputs are not recorded, and repeated executions are not performed, then no change can be connected to the previous state. Changes exist, but there is no way to determine in which direction they are acting. In a state where judgment is impossible, interpretation is also impossible, and when interpretation is impossible, decisions are made in a different way. Instead of comparing results, the method of producing results itself begins to change.
Change without a comparison baseline is not interpretation, but speculation
Because we cannot interpret, we change multiple things at once

When the same problem appears again, this time the scope of modification becomes broader. The person in charge touches multiple points simultaneously without identifying the root cause. Part of the logic is modified, configuration values are adjusted, and related parameters are changed together. Instead of applying each change separately, everything is bundled and deployed at once. After a few calls, normal behavior is observed, and that combination is shared as an “effective approach.” However, which change actually made the difference is never verified. Some elements in that combination may have been unnecessary, or may have even created new problems, but those distinctions are not identified. Since there is no baseline to verify each change individually, the attempt to separate them disappears altogether. A result is produced, but the path that led to that result is not preserved.
This choice quickly becomes fixed. Instead of repeating single changes, changing multiple things at once begins to appear more efficient. In a state where comparison is impossible, there is no way to judge which method is better, so the method that produces results more quickly is chosen. Experiments are not designed, and combinations continue to grow. At this point, one critical shift occurs. The moment multiple things are changed simultaneously, it becomes impossible to separate the impact of each change. A result exists, but the cause that produced it cannot be explained in parts. An unexplained result is not preserved as a record, but remains only as a lump in memory. What remains afterward is not “what worked,” but the impression of “what was applied together.”
Simultaneous changes in a state that cannot be interpreted erase causes and turn results into memory
The Criteria Do Not Stay One — They Multiply

At first, it was just a simple exception. A different rule applied only to a specific case, and that rule was meant to complement the existing logic. But if that exception remains over time, it stops being an exception and becomes another rule. The original rule does not disappear and remains intact, and the newly added rule is not removed either. In this way, rules are not replaced—they accumulate.
The problem begins at this point. A state is created where multiple different rules can be applied simultaneously to the same input. The result can vary depending on which rule is applied, but the basis for choosing between them is no longer clearly defined. In the code, this appears as branching logic, but the reasoning behind selecting a branch has already been pushed outside the code. Eventually, the decision falls to people, and each person begins applying different criteria.
In this state, the concept of a “correct rule” can no longer be maintained. The rules exist, but there is no rule that defines when each rule should be applied. It becomes a state where there are rules without a rule above them. From that moment on, the system loses consistency. The same input can no longer guarantee the same output, and even the language needed to explain the differences in results begins to disappear.
The Moment Criteria Disappear, Reversibility Is Lost

The core problem is not the coexistence of multiple rules itself. The real issue is that the moment this state is created, the very criteria for determining which rule is correct disappear. In a structure where different rules coexist, it becomes impossible to decide which rule should be removed. Even the act of removal requires another criterion.
At this point, any attempt to roll back inevitably fails. Removing one rule may restore correctness for some cases, but it breaks others. Removing a different rule causes another set of problems. Because there is no way to determine which state is more “correct,” removal is always perceived as a risk and ultimately avoided. As a result, every rule survives.
Consequently, the system transitions from a “modifiable state” to a “state that must be maintained.” No choice improves the system as a whole; every choice makes some part of it worse. In this structure, the concept of recovery no longer holds. The moment recovery is attempted, yet another rule is added. From this point on, change is no longer improvement but accumulation, and the system becomes fixed in an irreversible state.
When We Cannot Decide, We Copy and Paste

When the problem reappears, the person in charge no longer tries to find the root cause. They cannot determine where to make changes. There is no criterion to identify which condition created the issue or which change influenced it, making it nearly impossible to design a new approach. Instead, they recall what “worked before.” Code combinations that once produced correct behavior, branches that prevented issues, configuration values that temporarily stabilized results—these remain in memory. They take that combination and bring it into the current logic. They do not try to understand the code, nor verify why it worked. They simply paste it as is.
This choice gradually becomes natural. It feels faster and safer to reuse something that has already worked than to write new code. In a state where nothing can be verified, new attempts have a high probability of failure, and there is no baseline to revert to when they fail. On the other hand, any combination that has succeeded even once becomes its own justification. As a result, the codebase accumulates multiple different combinations designed to prevent the same problem. Each combination may work in a specific context, but its role within the overall flow is never explained. Code created at different points in time becomes entangled within a single logic, and their relationships grow increasingly complex.
From this point onward, development is no longer design—it becomes a repetition of choices. Decisions are not based on what is correct, but on what has worked at least once. These choices accumulate, and the accumulation of choices forms the structure. But this structure is not intentional—it is a collection of copied outcomes. Once this structure is formed, it cannot be reversed. Because no one can explain what each piece means, neither removal nor reconstruction is attempted.
When judgment becomes impossible, copying replaces design.
Because we cannot understand it, we cannot delete it

When you open the code, conditions that clearly do not match the current requirements are visible. Parameters that are no longer used, branches that only work under specific values, and fallback logic whose meaning cannot be explained are all still there. Logically, it makes sense to remove them. But in reality, this is where we stop. Because we cannot know why they were added.
At the previous stage, the meaning of the code is already no longer interpretable. We cannot explain what problem a condition was meant to prevent, nor can we reproduce the same situation. In this state, deletion becomes an experiment. But that experiment cannot be validated because there is no baseline for comparison. We cannot determine whether deleting it removes the issue or simply causes it to reappear through another path. In the end, deletion becomes an “unverifiable risk.”
So the choice becomes fixed. We do not delete.
As this decision repeats, every condition in the code loses its meaning. It is no longer “something that exists because it is needed,” but becomes “something that is maintained because it exists.” Once logic is introduced, it remains regardless of whether it can be explained. Nothing is removed. As a result, the structure is not refined—it accumulates.
In this state, the structure can no longer be reorganized. Because the existing flow cannot be understood, it is impossible to clean it up. When new requirements arrive, the existing code is not modified. Instead, new conditions are added on top of it. In a structure where deletion is impossible, all change happens through addition.
At this point, the structure is no longer the result of design. It is closer to a form where unexplained decisions have solidified simply because they were never removed. No one knows why something exists, and yet it remains. That state itself replaces structure.
From this moment on, the system is no longer a “maintained structure,” but a “fixed structure that exists only because it cannot be deleted.”
In a system that cannot be understood, deletion is not an option
Because we cannot fix it, changes only move the problem

When an issue occurs, the engineer does not touch the existing code. Instead of solving the problem, they add new branches around the conditions where the issue appears and make it bypass specific cases. The existing flow remains intact, and only new conditions are layered on top. The change is deployed quickly, and in that specific case, the issue appears to be resolved. But this change is not the result of removing the root cause—it is merely the result of temporarily avoiding a specific path. When the same input comes through a different path, the problem reappears. The engineer opens the code again and adds another condition to block that path. In this process, existing conditions are never removed. Because no one knows what impact their removal might have.
As this pattern repeats, the code becomes layered with conditions added at different points in time. Each condition may prevent a problem in a specific case, but at the same time, it can conflict with others or create unexpected flows. Fewer and fewer people can explain which branch executes first, which condition takes precedence, or how the entire flow works. From this point on, changes are no longer an act of restructuring. They become fixed as an act of adding yet another path while keeping the existing flow untouched.
The problem does not end there. At some point, no change functions in the direction of reducing issues. Adding one condition may eliminate a specific case, but it simultaneously creates a new issue somewhere else. Changes do not remove problems. They only relocate them. A problem that used to occur in A moves to B. When B is blocked, it appears in C. Each time, new conditions are added, and existing ones remain untouched.
At this point, the act of “fixing” loses its original meaning. It is no longer a means of recovery. It is no longer a process of removing the cause and restoring the system to a correct state. Instead, it only works as a way to push problems into different locations within the existing structure. No change stabilizes the system—it merely hides specific cases temporarily.
And when this state repeats, the act of moving problems itself becomes accepted as normal system behavior.
In a system that cannot be fixed, change is not recovery—it is relocation